
Luis R. Izquierdo, Segismundo S. Izquierdo, José Manuel Galán and José Ignacio Santos (2009)
Techniques to Understand Computer Simulations: Markov Chain Analysis
Journal of Artificial Societies and Social Simulation
vol. 12, no. 1 6
<https://www.jasss.org/12/1/6.html>
For information about citing this article, click here
Received: 16-Apr-2008 Accepted: 10-Sep-2008 Published: 31-Jan-2009

 Abstract
Abstract|
Applet 1
|
| Applet 1. Applet designed to illustrate the fact that a pseudorandom number generator always produces the same sequence of pseudorandom numbers when given the same random seed. The button "Clear" initialises the model, setting the random seed to 0. The user can select a specific random seed by clicking on "Change random seed", or ask the computer to generate one automatically (based on the current date and time) by clicking on "Computer-generated seed". Clicking on the button labelled "Generate list of pseudorandom numbers" shows a list of three pseudorandom numbers drawn from a uniform distribution between 0 and 1. This applet has been created with NetLogo 4.0 (Wilensky 1999) and its source code can be downloaded here. |

|
| Figure 1. Snapshot of CoolWorld. Patches are coloured according to their temperature: the higher the temperature, the darker the shade of red. The white labels on each patch indicate the integral part of their temperature value. Houses are coloured in orange and walkers (represented as a person) are coloured in green. |
The value of prob-leaving-home and prob-random-move is shared by every walker in the model. There is no restriction about the number of walkers that can stay on the same patch at any time.

|
| Figure 2. Snapshot of CoolWorld. Patches are coloured according to their temperature: the higher the temperature, the darker the shade of red. Houses are coloured in orange, and form a circle around the central patch. Walkers are coloured in green, and represented as a person if standing on a patch without a house, and as a smiling face if standing on a patch with a house. In the latter case, the white label indicates the number of walkers in the same house. |
|
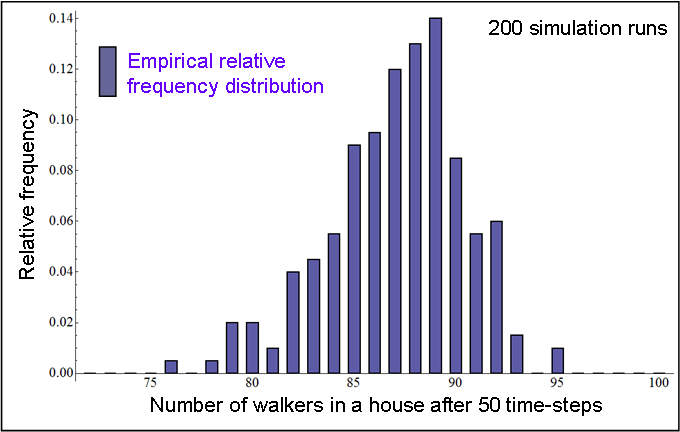
| Figure 3. Relative frequency distribution of the number of walkers in a house after 50 time-steps, obtained by running CoolWorld 200 times, with the initial conditions described in the text. |
|
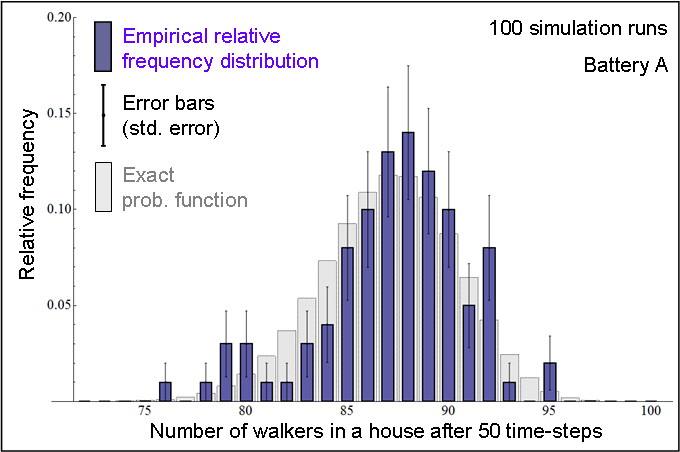
| Figure 4. In blue: Relative frequency distribution of the number of walkers in a house after 50 time-steps, obtained by running CoolWorld 100 times (Battery A), with the initial conditions described in the text. In grey: Exact probability function (calculated using Markov chain analysis). |
|
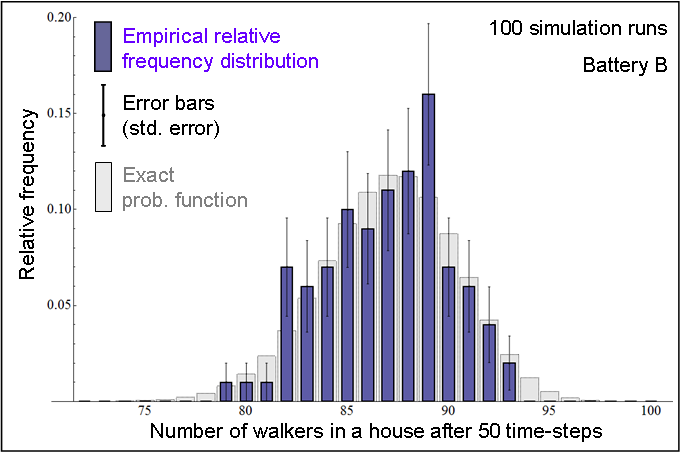
| Figure 5. In blue: Relative frequency distribution of the number of walkers in a house after 50 time-steps, obtained by running CoolWorld 100 times (Battery B), with the initial conditions described in the text. In grey: Exact probability function (calculated using Markov chain analysis). |
|
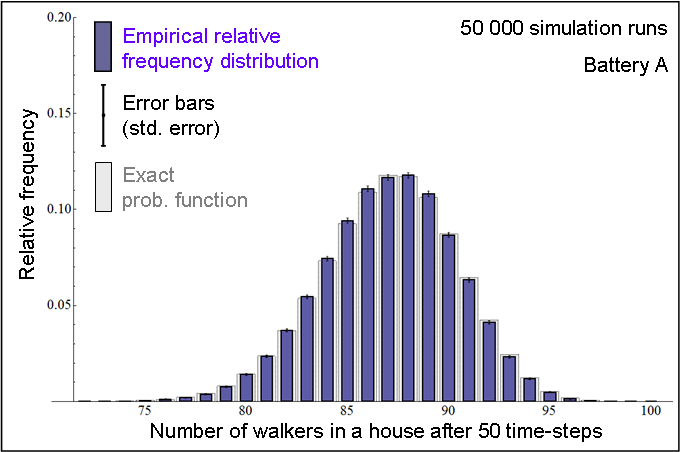
| Figure 6. In blue: Relative frequency distribution of the number of walkers in a house after 50 time-steps, obtained by running CoolWorld 50 000 times (Battery A), with the initial conditions described in the text. In grey: Exact probability function (calculated using Markov chain analysis). |
|
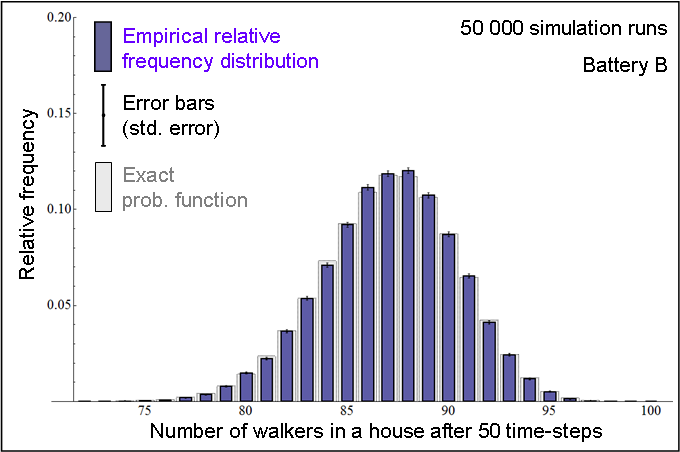
| Figure 7. In blue: Relative frequency distribution of the number of walkers in a house after 50 time-steps, obtained by running CoolWorld 50 000 times (Battery B), with the initial conditions described in the text. In grey: Exact probability function (calculated using Markov chain analysis). |
|
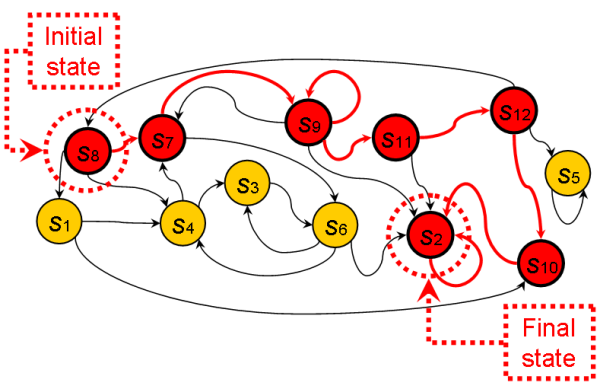
| Figure 8. Schematic transition diagram of a Markov chain. Circles denote states and directed arrows indicate possible transitions between states. In this figure, circles and arrows coloured in red represent one possible path where the initial state X0 is s8 and the final state is s2. |
Implicitly, our definition of transition probabilities assumes two important properties about the system:
P(Xn+1 = xn+1 | Xn = xn, Xn—1 = xn—1,…, X0 = x0) = P(Xn+1 = xn+1 | Xn = xn)
P(Xn+1 = j | Xn = i) = P(Xn = j | Xn—1 = i) = pi,j
|
Applet 2
|
| Applet 2. Applet of a 1-dimensional random walk. Patches are placed in a horizontal line at the top-right corner of the applet; each of them is labelled with a red integer. Pressing the button labelled "Create Walker" allows the user to create one single random walker, by clicking with the mouse on one of the patches. Clicking on "go once" will make the random walker move once, while "go" asks the random walker to move indefinitely. The plot beneath the patches shows the time series of the random walker's position. Patches are coloured in shades of blue according to the number of times that the random walker has visited them: the higher the number of visits, the darker the shade of blue. This applet has been created with NetLogo 4.0 (Wilensky 1999) and its source code can be downloaded here. |
|
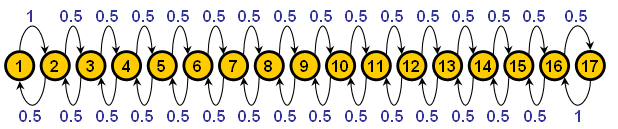
| Figure 9. Transition diagram of the model shown in Applet 2. Each yellow circle represents a state of the system, with the number inside denoting the patch number. Arrows between states show possible transitions between states. Every arrow has a blue label that indicates the probability with which that transition takes place. |

|
(1) |
Where, as explained above, pi,j is the probability P(Xn+1 = j | Xn = i) that the system will be in state j in the following time-step, knowing that it is currently in state i.
It can be shown that one can easily calculate the transient distribution in time-step n, simply by multiplying the initial conditions by the n-th power of the transition matrix P.
Proposition 1. a(n) = a(0) · Pn.
Thus, the elements p(n)i,j of Pn represent the probability that the system is in state j after n time-steps having started in state i, i.e. p(n)i,j = P(Xn = j | X0 = i). A straightforward corollary of Proposition 1 is that a(n+m) = a(n) · Pm.
As an example, let us consider the 1-dimensional random walk implemented in Applet 2. Imagine that the random walker starts at a random initial location, i.e. a(0) = [1/17, …, 1/17]. The exact distribution of the walker's position in time-step 100 would then be a(100) = a(0) · P100. This distribution is represented in Figure 10, together with an empirical distribution obtained by running the model 50 000 times.
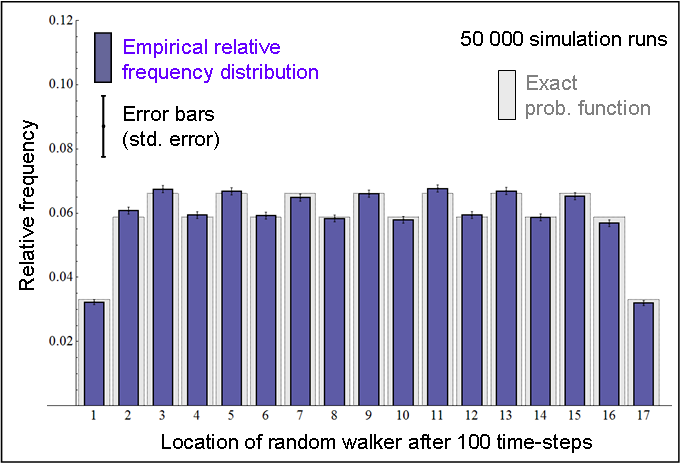
|
| Figure 10. Probability function of the position of Applet 2's random walker in time-step 100, starting at a random initial location. |

|
| Figure 11. Transient distributions of the location of a single walker in a CoolWorld model where the temperature profile and the distribution of houses are as described in paragraph 5.8. The height of each patch denotes the relative probability that the walker is on the patch in any given time-step. In other words, the plot uses height to represent a(n) for each time-step n. |
Note that j is accessible from i ≠ j if and only if there is a directed path from i to j in the transition diagram. In that case, we write i→j. If i→j we also say that i leads to j. As an example, in the THMC represented in Figure 8, s2 is accessible from s12 but not from s5. Note that the definition of accessibility does not depend on the actual magnitude of p(n)i,j , only on whether it is exactly zero or strictly positive.
If i communicates with j we also say that i and j communicate and write i↔j. As an example, note that in the simple random walk presented in paragraph 6.4 (see Applet 2) every state communicates with every other state. It is worth noting that the relation "communication" is transitive, i.e.
{i↔j , j↔k} ⇒ i↔k.
{i ∈ C, j ∈ C } ⇒ i↔j
{i ∈ C, i↔j} ⇒ j ∈ C
As an example, note that in the simple random walk presented in paragraph 6.4 there is one single communicating class that contains all the states. Similarly, any CoolWorld model where prob-leaving-home ∈ (0, 1) and prob-random-move ∈ (0, 1) has one single communicating class containing all the possible states. In the THMC represented in Figure 8 there are 4 communicating classes: {s2}, {s5}, {s10}, {s1, s3, s4, s6, s7, s8, s9, s11, s12}.
Note that once a Markov chain visits a closed communicating class, it cannot leave it. Hence we will sometimes refer to closed communicating classes as "absorbing classes". This latter term is not standard in the literature, but we find it useful here for explanatory purposes. Note that if a Markov chain has one single communicating class, it must be closed.
As an example, note that the communicating classes {s10} and {s1, s3, s4, s6, s7, s8, s9, s11, s12} in the THMC represented in Figure 8 are not closed, as they can be abandoned. On the other hand, the communicating classes {s2} and {s5} are indeed closed, since they cannot be abandoned. When a closed communicating class consists of one single state, this state is called absorbing. Thus, s2 and s5 are absorbing states. Formally, state i is absorbing if and only if pi,i = 1 and pi,j = 0 for i ≠ j.
S = C1 ∪ C2 ∪ … ∪ Ck ∪ T where C1, C2, …, Ck are closed communicating classes, and T is the union of all other communicating classes.
Note that we do not distinguish between non-closed communicating classes: we lump them all together into T. Thus, the unique partition of the THMC represented in Figure 8 is S = {s2} ∪ {s5} ∪ {s1, s3, s4, s6, s7, s8, s9, s10, s11, s12}. Any CoolWorld model where prob-leaving-home ∈ (0, 1) and prob-random-move ∈ (0, 1) has one single (closed) communicating class C1 containing all the possible states, i.e. S ≡ C1. Similarly, all the states in the simple random walk presented in paragraph 6.4 belong to the same (closed) communicating class.
As an example, note that every state in the simple random walk presented in paragraph 6.4 is periodic with period 2. On the other hand, every state in any CoolWorld model where prob-leaving-home ∈ (0, 1) and prob-random-move ∈ (0, 1) is aperiodic.
An interesting and useful fact is that if i↔j , then i and j must have the same period (see theorem 5.2. in Kulkarni (1995)). In particular, note that if pi,i > 0 for any i, then the communicating class to which i belongs must be aperiodic. Thus, it makes sense to qualify communicating classes as periodic with period d, or aperiodic. A closed communicating class with period d can return to its starting state only at times d, 2d, 3d, …
Proposition 3 states that sooner or later the THMC will enter one of the absorbing classes and stay in it forever. Formally, for all i ∈ S and all j ∈ T: 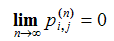 , i.e. the probability of finding the process in a state belonging to a non-closed communicating class goes to zero as n goes to infinity. Naturally, if the initial state already belongs to an absorbing class Cv, then the chain will never abandon such a class. Formally, for all i ∈ Cv and all j ∉ Cv: p(n)i,j = 0 for all n ≥ 0. We provide now two examples to illustrate the usefulness of Proposition 3.
, i.e. the probability of finding the process in a state belonging to a non-closed communicating class goes to zero as n goes to infinity. Naturally, if the initial state already belongs to an absorbing class Cv, then the chain will never abandon such a class. Formally, for all i ∈ Cv and all j ∉ Cv: p(n)i,j = 0 for all n ≥ 0. We provide now two examples to illustrate the usefulness of Proposition 3.
|
|

|
| Figure 12. Average number of walkers in each patch over time-steps 0 to 10 000 calculated with one single run (i.e. an estimation of the mean of the occupancy distribution for each patch, assuming 10 000 time-steps are enough) in a CoolWorld model parameterised as described in paragraph 5.8. |

|
| Figure 13. Average number of walkers in each patch in time-step 1000, calculated over 1000 simulation runs (i.e. an estimation of the mean of the limiting distribution for each patch, assuming 1000 time-steps are enough) in a CoolWorld model parameterised as described in paragraph 5.8. |
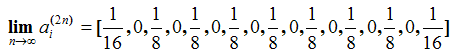
|
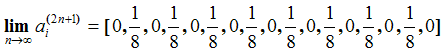
|
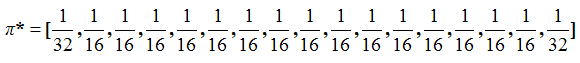
|
|
|
|
|
|
Applet 3
|
| Applet3. A model of reinforcement learning for 2 × 2 games. The white square on the top right is a representation of the state space, with player 1's propensity to cooperate in the vertical axis and player 2's propensity to cooperate in the horizontal axis. Thus, each patch in this square corresponds to one state. The red circle represents the current state of the system and its label (CC, CD, DC, or DD) denotes the last outcome that occurred. Patches are coloured in shades of blue according to the number of times that the system has visited the state they represent: the higher the number of visits, the darker the shade of blue. The plot beneath the representation of the state space shows the time series of both players' propensity to cooperate. This applet has been created with NetLogo 4.0 (Wilensky 1999) and its source code can be downloaded here. |
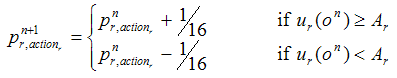
|
where pnr,action is player r's propensity to undertake action actionr in time-step n, and ur(on) is the payoff obtained by player r in time-step n, having experienced outcome on. The updated propensity for the action not selected derives from the constraint that propensities must add up to one. Note that this model can be represented as a THMC by defining the state of the system as a vector containing both players' propensity to cooperate, i.e. [p1,C , p2,C]. The following subsections analyse models where Tr > Rr > Pr > Ar > Sr, r = 1, 2.

|
| Figure 14. Transient distributions of the reinforcement learning model without trembling hands noise. Each patch represents a certain state of the system [p1,C , p2,C]. The closest patch to the vertical axis on the left represents the state where both players' propensity to cooperate is 0. The axis departing away from us from the origin denotes player 1's propensity to cooperate. The other axis (coming towards us) denotes player 2's propensity to cooperate. The height of each patch denotes the probability that the system is on the state represented by the patch in any given time-step. In other words, the plot uses height to represent the distribution of Xn for each time-step n. |

|
| Figure 15. Transient distributions of the reinforcement learning model with trembling hands noise equal to 0.1. Each patch represents a certain state of the system [p1,C , p2,C]. The closest patch to the vertical axis on the left represents the state where both players' propensity to cooperate is 0. The axis departing away from us from the origin denotes player 1's propensity to cooperate. The other axis (coming towards us) denotes player 2's propensity to cooperate. The height of each patch denotes the probability that the system is on the state represented by the patch in any given time-step. In other words, the plot uses height to represent the distribution of Xn for each time-step n. |
2Note that simulations of stochastic models are actually using pseudorandom number generators, which are deterministic algorithms that require a seed as an input.
3The mere fact that the model has been implemented and can be run in a computer is a proof that the model is formal (Suber 2007).
4As a matter of fact, strictly speaking, inputs and outputs in a computer model are never numbers. We may interpret strings of bits as numbers, but we could equally well interpret the same strings of bits as e.g. letters. More importantly, a bit itself is already an abstraction, an interpretation we make of an electrical pulse that can be above or below a critical voltage threshold.
5A sufficient condition for a programming language to be "sophisticated enough" is to allow for the implementation of the following three control structures:
6The frequency of the event "there are i walkers in a patch with a house at time-step 50" calculated over n simulation runs can be seen as the mean of a sample of n i.i.d. Bernouilli random variables where success denotes that the event occurred and failure denotes that it did not. Thus, the frequency f is the maximum likelihood (unbiased) estimator of the exact probability with which the event occurs. The standard error of the calculated frequency f is the standard deviation of the sample divided by the square root of the sample size. In this particular case, the formula reads:
Std. error (f, n) = (f (1 — f) / (n — 1))1/2
Where f is the frequency of the event, n is the number of samples, and the standard deviation of the sample has been calculated dividing by (n — 1).
7The term 'Markov chain' allows for countably infinite state spaces too (Karr 1990).
8Formally, the occupancy of state i is defined as:
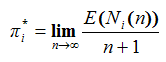
|
where Ni(n) denotes the number of times that the THMC visits state i over the time span {0, 1,…, n}.
9Given that the system has entered the absorbing class Cv.
ARTHUR, W B (1989) Competing technologies, increasing returns, and lock-in by historical events. Economic Journal 99(394), pp. 116-131.
AXELROD, R (1984). The Evolution of Cooperation. New York, Basic Books USA.
AXELROD, R (1986) An Evolutionary Approach to Norms. American Political Science Review 80(4), pp. 1095-1111.
AXELROD, R (1997) The dissemination of culture: A model with local convergence and global polarization. Journal of Conflict Resolution 41(2), pp. 203-226.
AXELROD, R and Bennett, D S (1993) A Landscape Theory of Aggregation. British Journal of Political Science 23(2), pp. 211-233.
AXELROD, R and Hamilton, W D (1981) The evolution of cooperation. Science 211(4489), pp. 1390-1396.
AXELROD, R M, Mitchell, W, Thomas, R E, Bennett, D S and Bruderer, E (1995) Coalition Formation in Standard-Setting Alliances. Management Science 41(9), pp. 1493-1508.
AXTELL, R (2000). Why agents? On the varied motivations for agent computing in the social sciences. In Macal, C M and Sallach, D (eds.), Proceedings of the Workshop on Agent Simulation: Applications, Models, and Tools: 3-24. Argonne, IL, Argonne National Laboratory.
AYDINONAT, N E (2007) Models, conjectures and exploration: An analysis of Schelling's checkerboard model of residential segregation. Journal of Economic Methodology 14(4), pp. 429-454.
BALZER, W, Brendel, K R and Hofmann S (2001) Bad Arguments in the Comparison of Game Theory and Simulation in Social Studies. Journal of Artificial Societies and Social Simulation 4(2) 1. http://jasss.soc.surreyac.uk/4/2/1.html
BENENSON, I and Torrens, P M (2004). Geosimulation: automata-based modeling of urban phenomena. Chichester, UK, John Wiley and Sons.
BHAVNANI, R (2003) Adaptive agents, political institutions and Civic Traditions in Modern Italy. Journal of Artificial Societies and Social Simulation 6(4) 1. http://jasss.soc.surreyac.uk/6/4/1.html
BÖHM, C and Jacopini, G (1966) Flow diagrams, turing machines and languages with only two formation rules. Communications of the ACM 9(5), pp. 366-371.
BUZING, P, Eiben, A and Schut, M (2005) Emerging communication and cooperation in evolving agent societies. Journal of Artificial Societies and Social Simulation 8(1) 2. http://jasss.soc.surreyac.uk/8/1/2.html
CASTELLANO, C, Marsili, M and Vespignani, A (2000) Nonequilibrium phase transition in a model for social influence. Physical Review Letters 85(16), pp. 3536-3539.
CENTOLA, D, González-Avella, J C, Eguíluz, V M and San Miguel, M (2007) Homophily, Cultural Drift, and the Co-Evolution of Cultural Groups. Journal of Conflict Resolution 51(6), pp. 905-929.
COHEN, M D, Riolo, R L and Axelrod, R (1999). "The Emergence of Social Organization in the Prisoners' Dilemma: How Context-Preservation and other Factors Promote Cooperatio." Santa Fe Institute Working Paper 99-01-002.
COLMAN, A M (1995). Game Theory and Its Applications in the Social and Biological Sciences. Oxford, UK, Butterworth-Heinemann.
CUTLAND, N (1980). Computability: An Introduction to Recursive Function Theory. Cambridge University Press.
CHING, W-K and Ng, M (2006). Markov Chains: Models, Algorithms and Applications. New York, Springer.
DAWES, R M (1980) Social Dilemmas. Annual Review of Psychology 31, pp. 169-193.
DE JONG, K A (2006). Evolutionary computation. A unified approach. Cambridge, Mass., MIT Press.
DE MARCHI, S (2005). Computational and Mathematical Modeling in the Social Sciences. Cambridge University Press.
DOEBELI, M and Hauert, C (2005) Models of cooperation based on the Prisoner's Dilemma and the Snowdrift game. Ecology Letters 8, pp. 748-766.
EDMONDS, B and Hales, D (2005) Computational simulation as theoretical experiment. Journal of Mathematical Sociology 29(3), pp. 209-232.
ELLISON, G (2000) Basins of Attraction, Long Run Equilibria, and the Speed of Step-by-Step Evolution. Review of Economic Studies 67, pp. 17-45.
EPSTEIN, J M (1999) Agent-based computational models and generative social science. Complexity 4(5), pp. 41-60.
EPSTEIN, J M (2006). Remarks on the Foundations of Agent-Based Generative Social Science. In Amman, H M, Kendrick, D A and Rust, J (eds.), Handbook of Computational Economics 2: 1585-1604. North-Holland.
EPSTEIN, J M and Axtell, R L (1996). Growing Artificial Societies: Social Science from the Bottom Up. The MIT Press.
ESHEL, I and Cavalli-Sforza, L L (1982) Assortment of Encounters and Evolution of Cooperativeness. Proceedings of the National Academy of Sciences of the United States of America 79(4), pp. 1331-1335.
FLACHE, A and Hegselmann, R (2001) Do Irregular Grids make a Difference? Relaxing the Spatial Regularity Assumption in Cellular Models of Social Dynamics. Journal of Artificial Societies and Social Simulation 4(4) 6. http://jasss.soc.surreyac.uk/4/4/6.html
FLACHE, A and Macy, M W (2002) Stochastic collusion and the power law of learning: A general reinforcement learning model of cooperation. Journal of Conflict Resolution 46(5), pp. 629-653.
FLENTGE, F, Polani, D and Uthmann, T (2001) Modelling the emergence of possession norms using memes. Journal of Artificial Societies and Social Simulation 4(4) 3. http://jasss.soc.surreyac.uk/4/4/3.html
FORT, H and Pérez, N (2005) The Fate of Spatial Dilemmas with Different Fuzzy Measures of Success. Journal of Artificial Societies and Social Simulation 8(3) 1. http://jasss.soc.surreyac.uk/8/3/1.html
FOSTER and Young (1990) Stochastic evolutionary game dynamics. Theoretical Population Biology 38, pp. 219-232.
GALAM, S (1996) Fragmentation versus stability in bimodal coalitions. Physica A: Statistical Mechanics and its Applications 230(1-2), pp. 174-188.
GALAN, J M and Izquierdo, L R (2005) Appearances can be deceiving: Lessons learned re-implementing Axelrod's 'evolutionary approach to norms'. Journal of Artificial Societies and Social Simulation 8(3) 2. http://jasss.soc.surreyac.uk/8/3/2.html
GATHERER, D (2002) Identifying cases of social contagion using memetic isolation: Comparison of the dynamics of a multisociety simulation with an ethnographic data set. Journal of Artificial Societies and Social Simulation 5(4) 5. http://jasss.soc.surreyac.uk/5/4/5.html
GENZ, A and Kwong, K-S (2000) Numerical evaluation of singular multivariate normal distributions. Journal of Statistical Computation and Simulation 68(1), pp. 1-21.
GILBERT, N (2007) Agent-Based Models. Series: Quantitative Applications in the Social Sciences. Sage Publications: London.
GONZÁLEZ-AVELLA, J, Cosenza, M G, Klemm, K, Eguíluz, V M and San Miguel, M (2007) Information feedback and mass media effects in cultural dynamics. Journal of Artificial Societies and Social Simulation 10(3) 9. https://www.jasss.org/10/3/9.html
GOTTS, N M, Polhill, J G and Law, a N R (2003) Agent-based simulation in the study of social dilemmas. Artificial Intelligence Review 19(1), pp. 3-92.
HAREL, D (1980) On folk theorems. Communications of the ACM 23(7), pp. 379-389.
HAUERT, C and Doebeli, M (2004) Spatial structure often inhibits the evolution of cooperation in the snowdrift game. Nature 428(6983), pp. 643-646.
HEGSELMANN, R and Flache, A (1998) Understanding Complex Social Dynamics: A Plea For Cellular Automata Based Modelling. Journal of Artificial Societies and Social Simulation 1(3) 1. http://jasss.soc.surreyac.uk/1/3/1.html
IZQUIERDO, L R, Izquierdo, S S, Gotts, N M and Polhill, J G (2007) Transient and asymptotic dynamics of reinforcement learning in games. Games and Economic Behavior 61(2), pp. 259-276.
IZQUIERDO, S S, Izquierdo, L R and Gotts, N M (2008) Reinforcement learning dynamics in social dilemmas. Journal of Artificial Societies and Social Simulation 11(2) 1. https://www.jasss.org/11/2/1.html
JANSSEN, J and Manca, R (2006). Applied Semi-Markov Processes. New York, NY, USA, Springer.
JOYCE, D, Kennison, J, Densmore, O, Guerin, S, Barr, S, Charles, E and Thompson, N S (2006) My Way or the Highway: a More Naturalistic Model of Altruism Tested in an Iterative Prisoners' Dilemma. Journal of Artificial Societies and Social Simulation 9(2) 4. http://jasss.soc.surreyac.uk/9/2/4.html
KARR, A F (1990). Markov Processes. In Heyman, D P and Sobel, M J (eds.), Stochastic Models. Handbooks in Operations Research and Management Science 2: 95-123. Elsevier Science Publishers B.V. (North-Holland).
KILGOUR, D M (1971) The simultaneous truel. International Journal of Game Theory 1(1), pp. 229-242.
KILGOUR, D M (1975) The Sequential Truel. International Journal of Game Theory 4(3), pp. 151-174.
KILGOUR, D M (1977) Equilibrium points of Infinite Sequential Truels. International Journal of Game Theory 6(3), pp. 167-180.
KINNAIRD, C (1946). Encyclopedia of Puzzles and Pastimes. Secaucus, NJ, Citadel.
KLEMM, K, Eguíluz, V M, Toral, R and San Miguel, M (2003a) Global culture: A noise-induced transition in finite systems. Physical Review E 67(4), Article 045101.
KLEMM, K, Eguíluz, V M, Toral, R and San Miguel, M (2003b) Nonequilibrium transitions in complex networks: A model of social interaction. Physical Review E 67(2), Article 026120.
KLEMM, K, Eguíluz, V M, Toral, R and San Miguel, M (2003c) Role of dimensionality in Axelrod's model for the dissemination of culture. Physica A 327, pp. 1-5.
KLEMM, K, Eguíluz, V M, Toral, R and San Miguel, M (2005) Globalization, polarization and cultural drift. Journal of Economic Dynamics and Control 29(1-2), pp. 321-334.
KULKARNI, V G (1995). Modeling and Analysis of Stochastic Systems. Chapman & Hall/CRC.
KULKARNI, V G (1999). Modeling, Analysis, Design, and Control of Stochastic Systems. New York, Springer-Verlag.
LEOMBRUNI, R and Richiardi, M (2005) Why are economists sceptical about agent-based simulations? Physica A: Statistical Mechanics and its Applications 355(1), pp. 103-109.
LEYDESDORFF, L (2001) Technology and culture: The dissemination and the potential 'lock-in' of new technologies. Journal of Artificial Societies and Social Simulation 4(3) 5. http://jasss.soc.surreyac.uk/4/3/5.html
MACY, M W and Flache, A (2002) Learning dynamics in social dilemmas. Proceedings of the National Academy of Sciences of the United States of America 99, pp. 7229-7236.
MILLER, J H and Page, S E (2007). Complex Adaptive Systems: An Introduction to Computational Models of Social Life. Princeton University Press.
MILLER, J H and Page, S E (2004) The standing ovation problem. Complexity 9(5), pp. 8-16.
NÉMETH, A and Takács, K (2007) The Evolution of Altruism in Spatially Structured Populations. Journal of Artificial Societies and Social Simulation 10(3) 4. https://www.jasss.org/10/3/4.html
NOWAK, M A and May, R M (1992) Evolutionary games and spatial chaos. Nature 359(6398), pp. 826-829.
NOWAK, M A and Sigmund, K (1998) Evolution of indirect reciprocity by image scoring. Nature 393(6685), pp. 573-577.
RICHIARDI, M, Leombruni, R, Saam, N and Sonnessa, M (2006) A common protocol for agent-based social simulation. Journal of Artificial Societies and Social Simulation 9(1) 15. https://www.jasss.org/9/1/15.html
SAKODA, J M (1971) The Checkerboard Model of Social Interaction. The Journal of Mathematical Sociology 1(1), pp. 119-132.
SCHELLING, T C (1969) Models of segregation. American Economic Review 59(2), pp. 488-493.
SCHELLING, T C (1971) Dynamic Models of Segregation. The Journal of Mathematical Sociology 1(2), pp. 143-186.
SCHELLING, T C (1978). Micromotives and Macrobehavior. New York, Norton.
SELTEN, R (1975) Reexamination of the perfectness concept for equilibrium points in extensive games. International Journal of Game Theory 4(1), pp. 25-55.
SUBER, P (2007) Formal Systems and Machines: An Isomorphism. Hand-out for "Logical Systems". Earlham College.
TAKAHASHI, N (2000) The emergence of generalized exchange. American Journal of Sociology 10(4), pp. 1105-1134.
TORAL, R and Amengual, P (2005). Distribution of winners in truel games. In Garrido, P L, Marro, J and Muñoz, M A (eds.), Modelling Cooperative Behavior in the Social Sciences Vol. 779 of AIP Conf. Proc.: 128-141. American Institute of Physics.
VEGA-REDONDO, F (2003) Economics and the Theory of Games. Cambridge University Press.
WIKIPEDIA, C (2007). Structured program theorem. Wikipedia, The Free Encyclopedia, Available from http://en.wikipedia.org/w/index.php?title=Structured_program_theorem&oldid=112885072.
WILENSKY, U (1999). NetLogo. Evanston, IL Center for Connected Learning and Computer-Based Modeling, Northwestern University. http://ccl.northwestern.edu/netlogo/.
YOUNG, H P (1993) The Evolution of Conventions. Econometrica 61(1), pp. 57-84.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2009]