
 Abstract
Abstract
- We compare a sample-free method proposed by Gargiulo et al. (2010) and a sample-based method proposed by Ye et al. (2009) for generating a synthetic population, organised in households, from various statistics. We generate a reference population for a French region including 1310 municipalities and measure how both methods approximate it from a set of statistics derived from this reference population. We also perform a sensitivity analysis. The sample-free method better fits the reference distributions of both individuals and households. It is also less data demanding but it requires more pre-processing. The quality of the results for the sample-based method is highly dependent on the quality of the initial sample.
- Keywords:
- Synthetic Populations, Sample-Free, Iterative Proportional Updating, Sample Based Method, Microsimulation
Introduction
- 1.1
- For two decades, the number of micro-simulation models, simulating the evolution of large populations with an explicit representation of each individual, has been constantly increasing with the computing capabilities and the availability of longitudinal data. When implementing such an approach, the first problem is initialising properly a large number of individuals with the adequate attributes. Indeed, in most of the cases, for privacy reasons, exhaustive individual data are excluded from the public domain. Aggregated data at various levels (municipality, county,...), guaranteeing this privacy, are hence only available in general. Sometimes, individual data are available on a sample of the population, these data being chosen also for guaranteeing the privacy (for instance omitting the individual's location of residence). This paper focuses on the problem of generating a virtual population with the best use of these data, especially when the goal is generating both individuals and their organisation in households.
- 1.2
- Two main methods, both requiring a sample of the population, aim at tackling this problem:
- The synthetic reconstruction methods (SR) (Wilson & Pownall 1976). These methods generally use the Iterative Proportional Fitting (Deming & Stephan 1940) and a sample of the target population to obtain the joint-distributions of interest (Huang & Williamson 2002; Ye et al. 2009; Arentze et al. 2007; Guo & Bhat 2007; Beckman et al. 1996). Many of the SR methods match the observed and simulated households joint-distribution or individual joint-distribution but not simultaneously. To circumvent these limitations Ye et al. (2009), Arentze et al. (2007), and Guo & Bhat (2007) proposed different techniques to match both household and individual attributes. Here, we focus on the Iterative Proportional Updating developed by Ye et al. (2009).
- The combinatorial optimization (CO). These methods create a synthetic population by zone using marginals of the attributes of interest and a sub-set of a sample of the target population for each zone (for a complete description see Huang & Williamson (2002); Voas & Williamson (2000)).
- 1.3
- Recently, sample-free SR methods appeared (Gargiulo et al. 2010; Barthelemy & Toint 2012). The sample-free SR methods build households by picking up individuals in a set comprising initially the whole population and progressively shrinking. In Barthelemy & Toint (2012), if there is no appropriate individual in the current set, the individual is picked up in the already generated households, whereas in (Gargiulo et al. 2010), the individuals are picked up in the set only. Both approaches are illustrated on real life examples, Barthelemy & Toint (2012) generated a synthetic population of Belgium at the municipality level and Gargiulo et al. (2010) generated the population of two municipalities in Auvergne region (France). These methods can be used in the usual situations where no sample is available and one must only use distributions of attributes (of individuals and households). Hence, they overcome a strong limit of the previous methods. It is therefore important to assess if this larger scope of the sample-free method implies a loss of accuracy compared with the sample-based method.
- 1.4
- The aim of this paper is contributing to this assessment. With this aim, we compare the sample-based IPU method proposed by Ye et al. (2009) with the sample-free approach proposed by Gargiulo et al. (2010) on an example.
- 1.5
- In order to compare the methods, the ideal case would be to have a population with complete data available about individuals and households. It would allow us to measure precisely the accuracy of each method, in different conditions. Unfortunately, we do not have such data. In order to put ourselves in a similar situation, we generate a virtual population and then use it as a reference to compare the selected methods as in Barthelemy & Toint (2012). All the algorithms presented in this paper are implemented in JAVA on a desktop machine (PC Intel 2.83 GHz).
- 1.6
- In the first section we formally present the two methods. In the second section we present the comparison results. Finally, we discuss our results.
Details of the chosen methods
-
Sample-free method Gargiulo et al. (2010)
- 2.1
- We consider a set of n individuals X to dispatch in a set of m households Y in order to obtain a set of filled households P. Each individual x is characterised by a type tx from a set of q different individual types T (attributes of the individual). Each household y is characterised by a type uy from a set of p differents household types U (attributes of the household). We define
nT = {ntk}1
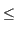 k q as the number of individuals of each type and
nU = {nul}1 l p as the number of households of each type. Each household y of a given type uy has a probability to be filled by a subset of individuals L, then the content of the household equals L, which is denoted c(y) = L. We use this probability to iteratively fill the households with the individuals of X.
k q as the number of individuals of each type and
nU = {nul}1 l p as the number of households of each type. Each household y of a given type uy has a probability to be filled by a subset of individuals L, then the content of the household equals L, which is denoted c(y) = L. We use this probability to iteratively fill the households with the individuals of X.
- 2.2
- The iterative algorithm used to dispach the individuals into the households according to the Equation 1 is described in Algorithm 1. The algorithm starts with the list of individuals X and of the households Y, defined by their types. Then it iteratively picks at random a household, and from its type and Equation 1, derives a list of individual types. If this list of individual types is available in the current list of individuals X, then this filled household is added to the result, and the current lists of individuals and households are updated. This operation is repeated until one of the lists X or Y is void, or a limit number of iterations is reached.
- 2.3
- In the case of the generation of a synthetic population, we can replace the selection of the list L by the selection of the individuals one at a time by order of importance in the household. In this case Equation 2 replaces Equation 1.
- 2.4
- The iterative approach algorithm associated with this probability is described in Algorithm 2. The principle is the same as previously, it is simply quicker. Instead of generating the whole list of individuals in the household before checking it, one generates this list one by one, and as soon as one of its members cannot be found in X, the iteration stops, and one tries another household.
- 2.5
- In practice this stochastic approach is data driven. Indeed, the types T and U are defined in accordance with the data available and the complexity to extract the distribution of the Equation 2 increases with nT and nU. The distributions defined in Equation 2 are called distributions for affecting individual into household. In concrete applications, it occurs that one needs to estimate nT, nU and the distributions of probabilities presented in Equation 2. This estimation implies that the Algorithm 2 can not converge in a reasonable time because of the stopping criterion (y ≠ ∅). This stopping criterion is equivalent to an infinite number of "filling" trials by households. In this case, we can replace the stopping criterion by a maximal number of iterations by households and then put the remaining individuals in the remaining households using relieved distributions for affecting individual into household.
- 2.6
- In a perfect case where all the data are available and the time infinite, the algorithm would find a perfect solution. When the data are partial and the time constrained, it is interesting to assess how this method manages to make the best use of the available data.
The sample-based approach (General Iterative Proportional Updating)
- 2.7
- This approach, proposed by Ye et al. (2009), starts with a sample Ps of P and the purpose is to define a weight wi associated with each individual and each househld of the sample in order to match the total number of each type of individuals in X and households in Y to reconstruct P. The method used to reach this objective is the Iterative Proportional Updating (IPU). The algorithm proposed in Ye et al. (2009) is described in Algorithm 3. In this algorithm, for each type of households or individuals j the purpose is to match the weighted sum swj with the estimated constraints ej with an adjustement of the weights. ej is an estimation of the total number of households or individuals j in P. This estimation is done separetely for each individual and household type using a standard IPF procedure with marginal variables. When the match between the weighted sample and the constraint becomes stable, the algorithm stops. The procedure then generates a synthetic population by drawing at random the filled households of Ps with probabilities corresponding to the weights. This generation is repeated several times and one chooses the result with the best fit with the observed data.
Table 1: IPU Table. The light grey table represents the frequency matrix D showing the household type U and the frequency of different individual types T within each filled households for the sample Ps. The dimension of D is | Ps|×(p + q), where | Ps| is the cardinal number of the sample Ps, q the number of individual types and p the number of household types. An element dij of D represents the contribution of filled household i to the frequency of individual/household type j. 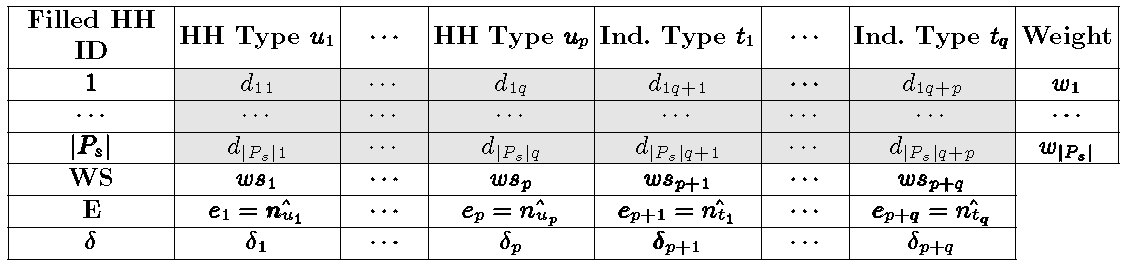



Generating a synthetic population of reference for the comparison
- 3.1
- Because we cannot access any population with complete data available about individuals and households, we generate a virtual population and then use it as a reference to compare the selected methods as in Barthelemy & Toint (2012).
- 3.2
- We start with statistics about the population of Auvergne (French region) in 1990 using the sample-free approach presented above. The Auvergne region is composed of 1310 municipalities, 1,321,719 inhabitants gathered in 515,736 households. Table 2 presents summary statistics on the Auvergne municipalities.
Generation of the individuals
- 3.3
- For each municipality of the Auvergne region we generate a set X of individuals with a stochastic procedure. For each individual of the age pyramid (distribution 1 in Table 3), we randomly choose an age in the bin and then we draw randomly an activity status according to the distribution 2 in Table 3.
Generation of the households
- 3.4
- For each municipality of the Auvergne region we generate a set Y of households according to the total number of individual n = | X| with a stochastic procedure. We draw at random households according to the distribution 3 in Table 3 while the sum of the capacities is below n and then we determine the last household to have n equal to the sum of the size of the households.
Distributions for affecting individual into household
Single
- The age of the individual 1 is determined using the distribution 4 in Table 3.
Monoparental
- The age of the individual 1 is determined using the distribution 4 in Table 3.
- The ages of the children are determined according to the age of individual 1 (An individual can do a child after 15 and before 55) and the distribution 6 in Table 3.
Couple without child
- The age of the individual 1 is determined using the distribution 4 in Table 3.
- The age of the individual 2 is determined using the distribution 5 in Table 3.
Couple with child
- The age of the individual 1 is determined using the distribution 4 in Table 3.
- The age of the individual 2 is determined using the distribution 5 in Table 3.
- The ages of the children are determined according to the age of individual 1 and the distribution 6 in Table 3.
Other
- The age of the individual 1 is determined using the distribution 4 in Table 3.
- The ages of the others individuals are determined according to the age of individual 1.
Table 3: Data description IDDescription Level 1Number of individuals grouped by ages Municipality (LAU2) 2Distribution of individual by activity status according to the age Municipality (LAU2) 3Joint-distribution of household by type and size Municipality (LAU2) 4Probability to be the head of household according to the age and the type of household Municipality (LAU2) 5Probability of having a couple according to the difference of age between the partners (from"-16years" to "21years") National level 6Probability to be a child (child=live with parent) of household according to the age and the type of household Municipality (LAU2)
- 3.5
- To obtain a synthetic population P with households Y filled by individuals X we use the Algorithm 2 where we approximate the Equation 2 with the distributions 4, 5 and 6 in Table 3. We put no constraint on the number of individuals in the age pyramid, hence the reference population does not give any advantage to the sample-free method. Figure 4 and Figure 5 show the values obtained for individual's and household's attributes for the Auvergne region and for Marsac-en-Livradois, a municipality drawn at random among the 1310 Auvergne municipalities. These figures show the results obtained with the reference, the sample-free and the sample-based populations.
Comparing sample-free and sample-based approaches
- 4.1
- The attributes of both individuals and households are respectivily described in Table 4 and Table 5. The joint-distributions of both the attributes for individuals and households give respectively the number of individuals of each individual type
nT = {ntk}1 k q and the number of households of each household type
nU = {nul}1 l p. In this case, q = 130 and p = 17. It's important to note that p is not equal to
6 . 5 = 30 because we remove from the list of household types the inconsistent values like for example single households of size 5. We do the same for the individual types (removing for example retired individuals of age comprised betweeen 0 and 5).
Table 4: Individual level attributes Attribute Value Age [0,5[ [5,15[ [15,25[ [25,35[ [35,45[ [45,55[ [55,65[ [65,75[ [75,85[ 85 and more Activity Status Student Active Family Status Head of a single household Head of a monoparental household Head of a couple without children household Head of a couple with children household Head of a other household Child of a monoparental household Child of a couple with children household Partner Other
Fitting accuracy measures
- 4.2
- We need fitting accuracy measures to evaluate the adequacy between both observed O and estimated E household and individual distributions. The first measure is the Proportion of Good Prediction (PGP) (Equation 3), we choose this first indicator for the facility of interpretation. In the Equation 3 we multiplied by 0.5 because as we have
 Ok = Ek, each misclassified individual or household is counted twice (Harland et al. 2012).
Ok = Ek, each misclassified individual or household is counted twice (Harland et al. 2012).
- 4.3
- We use the
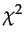 distance to perform a statistic test. Obviously the modalities with a zero value for the observed distribution are not included in the computation. If we consider a distibution with p modalities different from zero in the observed distribution, the distance follows a distribution with p - 1 degrees of freedom.
distance to perform a statistic test. Obviously the modalities with a zero value for the observed distribution are not included in the computation. If we consider a distibution with p modalities different from zero in the observed distribution, the distance follows a distribution with p - 1 degrees of freedom.
- 4.4
- For more details on the fitting accuracy measures see Voas & Williamson (2001).
Sample-free approach
- 4.5
- To test the sample-free approach, we extract from the reference population, for each municipality, the distributions presented in Table 3. Then we use the procedure used for generating the population of reference but now with the constraints on the number of individuals from the age pyramid derived from the reference (remember that we did not have such constraints when generating the reference population). Then we fill the households with the individuals one at a time using the distributions for affecting individual into household. We limit the number of iterations to 1000 trials by household: If after 1000 trials a household is not filled, we put at random individuals in this household and we change its type to "other". We repeat the process 100 times and we choose, for each municipality, the synthetic population minimizing the distance between simulated and reference distributions for affecting individual into household.
- 4.6
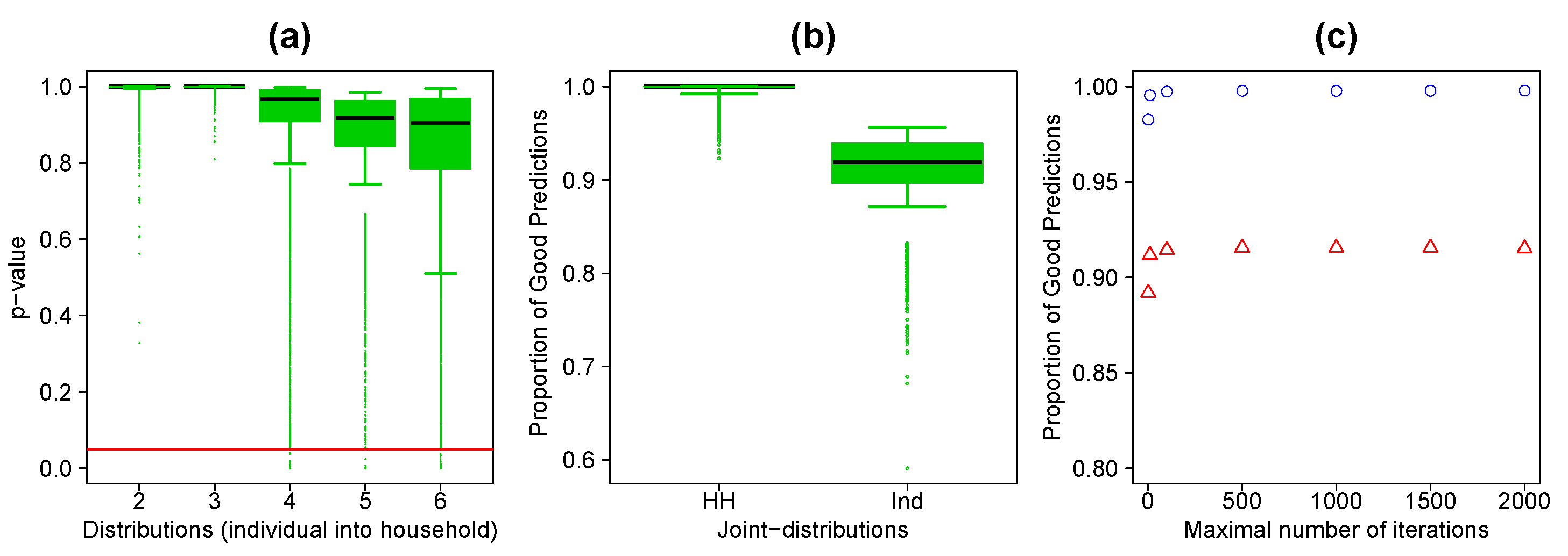
- In order to assess the robustness of the stochastic sample-free approach, we generate 10 synthetic populations by municipalities, yielding 13,100 synthetic municipality populations in total. For each of them and for each distributions for affecting individual into household we compute the p-value associated to distance between the reference and estimated distributions. As we can see in the Figure 1 a the algorithm is quite robust.
- 4.7
- To validate the algorithm we compute the proportion of good predictions for each 13,100 synthetic populations and for each joint-distribution. We obtain an average of 99.7% of good predictions for the household distribution and 91.5% of good predictions for the individual distribution (Figure 1b). We also compute the p-value of the distance between the estimated and reference distributions for each of the synthetic populations and for each joint-distribution. Among the 13,100 synthetic populations 100% are statistically similar to the observed one at a 0.95% level of confidence for the household joint-distribution and 94% for the individual joint-distribution.
- 4.8
- In order to understand the effect of the maximal number of iterations by household, we repeat the previous tests for different values of this parameter (1,10,100,500,1000,1500 and 2000) and we compute the mean proportion of good predictions obtained for both individual and household. We note that after 100 the quality of the results no longer changes.
Figure 1: (a) Boxplots of the p-values obtained with the distance between the estimated distributions and the observed distributions for
each distribution for affecting individual into household, municipalities and replications. The x-axis represents the distributions presented in Table 3. The red line
represents the
risk 5% for the test. (b) Boxplots of the proportion of good predictions for each joint-distribution, municipalities and replications.
(c) Average proportion of good predictions as a function of the number of maximal iteration by households. Blue circles for the households. Red
triangles for the individual.
IPU
- 4.9
- To use the IPU algorithm we need a sample of filled households and marginal variables. In order to obtain these data we pick at random a significant sample of 25% of households from the reference population P and we also extract from P the two one-dimensional marginals (Size and Type distributions) that we need to build the household joint-distributions with IPF and the three two-dimensional marginals (Age × Activity Status, Age × Family Status and Family Status × Activity Status) joint-distributions that we need to build the individual joint-distributions with IPF. Then we apply the Algorithm 3 using the recommendation of Ye et al. (2009) for the well-know zero-cell and zero-marginal problems to obtain a weighted sample Ps. With this sample we generate 100 times the synthetic population P and choose the one with lowest distance between reference and simulated individual joint-distributions.
- 4.10
- To check the results obtained with the IPU approach, we generate 10 synthetic populations by municipality using different samples of 25% of households randomly selected. For each of these synthetic populations and for each joint-distribution we compute the proportion of good predictions (Figure 2a). We obtain an average of 98.6% of good predictions for the household distribution and 86.9% of good predictions for the individual distribution. To determine the error of estimation due to the IPF procedure we compute the proportion of good predictions for the estimated and the IPF-reference distributions. As we can see in Figure 2b the results are improved for the household distribution but not for the individual distribution. We also compute the p-value of the distance between the estimated and observed distributions for each of the synthetic populations and for each joint-distribution. Among the 13,100 synthetic populations 100% are statistically similar to the observed one at a 0.95% level of confidence for the household joint-distribution and 61% for the individual joint-distribution. We obtained a similarity between the estimated and the IPF-objective distributions of 100% at a 0.95% level of confidence for the household distribution and 64% for the individual distribution.
- 4.11
- In order to check the sensitivity of the results to the size of the sample, we plot, on Figure 2c, the average proportion of good predictions of the 13,100 household and individuals joint-distributons for different values of the percentage of the reference households drawn at random in the sample (5, 10, 15, 20 ,25, 30, 35, 40, 45 and 50). We note that the results are always good for the household distribution but for the individuals the results are good only from random sample of at least 25% of the reference household population. Not surprisingly, globally the quality of the results increases with the parameter.
Figure 2: (a) Boxplots of the proportion of good predictions for a comparaison between the estimated distribution and the observed distribution for each municipality and replication. (b) Boxplots of the proportion of good predictions for a comparaison between the estimated distribution and the IPF-objective distribution for each municipality and replication. (c) Average proportion of good predictions as a function of the sample size. Blue circles for the households. Red triangles for the individuals. 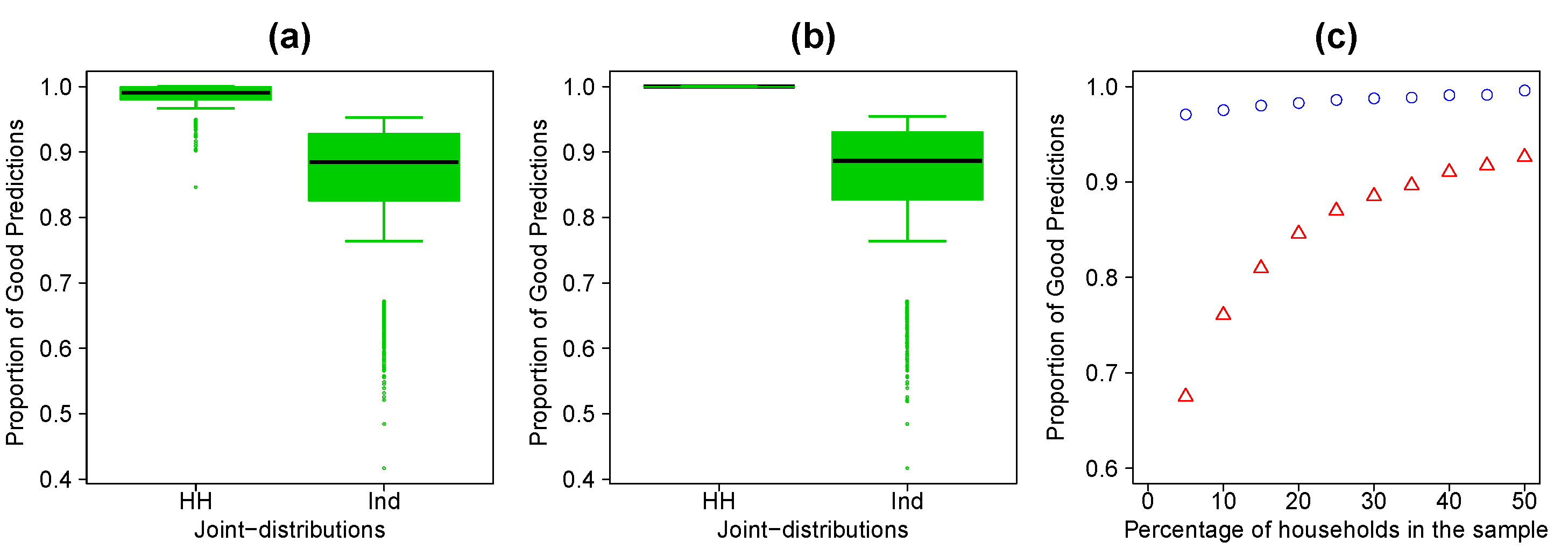
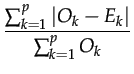
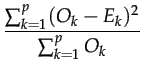
Discussion
- 5.1
- The sample-free method is less data demanding but it requires more data pre-processing. Indeed, this approach requires to extract the distributions for affecting individual into household from data. The sample-free method gives better fit between observed and simulated distribution for both household and individual distribution than the IPU approach. We can observe in Figure 3 that, for both methods, the goodness-of-fit is negatively correlated with the number of inhabitants. This observation is especially true for the IPU method because it depends on the number of individuals in the sample. Indeed, the lower is the number of individuals, the higher is the number of sparse cells in the individual distribution. The results obtained with the IPU approach depend of the quality of the initial sample. The execution time on a desktop machine (PC Intel 2.83 GHz) is almost the same for 100 maximal iterations by household for the sample-free method and 25% reference households drawn at random in the sample reference households for the sample-based approach.
- 5.2
- To conclude, the sample-free method gives globally better results in this application on small French municipalities. These results confirm those of Barthelemy & Toint (2012) who compared their sample-free method for working with data from different sources with a sample-based method (Guo & Bhat 2007), and obtained similar conclusions. Of course, these conclusions cannot be generalized to all sample-free and sample-based methods without further investigation. However, these results confirm the possibility to initialise accurately micro-simulation (or agent-based) models, using widely available data (and without any sample of households).
Figure: Maps of the average proportion of good predictions ((a) sample-free and (b) IPU) and the number of inhabitants ((c)) by municipality for the Auvergne case study. For (a)-(b), in blue 0.5  PGP < 0.75; In green 0.75 PGP < 0.9; In red 0.9 PGP. For (c), in green, the number of
inhabitants is lower than 350. In red, the number of inhabitants is upper than 350. Base maps source: Cemagref - DTM -
Développement Informatique Système d'Information et Base de Données : F.Bray & A.Torre
IGN (Géofla®, 2007).
PGP < 0.75; In green 0.75 PGP < 0.9; In red 0.9 PGP. For (c), in green, the number of
inhabitants is lower than 350. In red, the number of inhabitants is upper than 350. Base maps source: Cemagref - DTM -
Développement Informatique Système d'Information et Base de Données : F.Bray & A.Torre
IGN (Géofla®, 2007).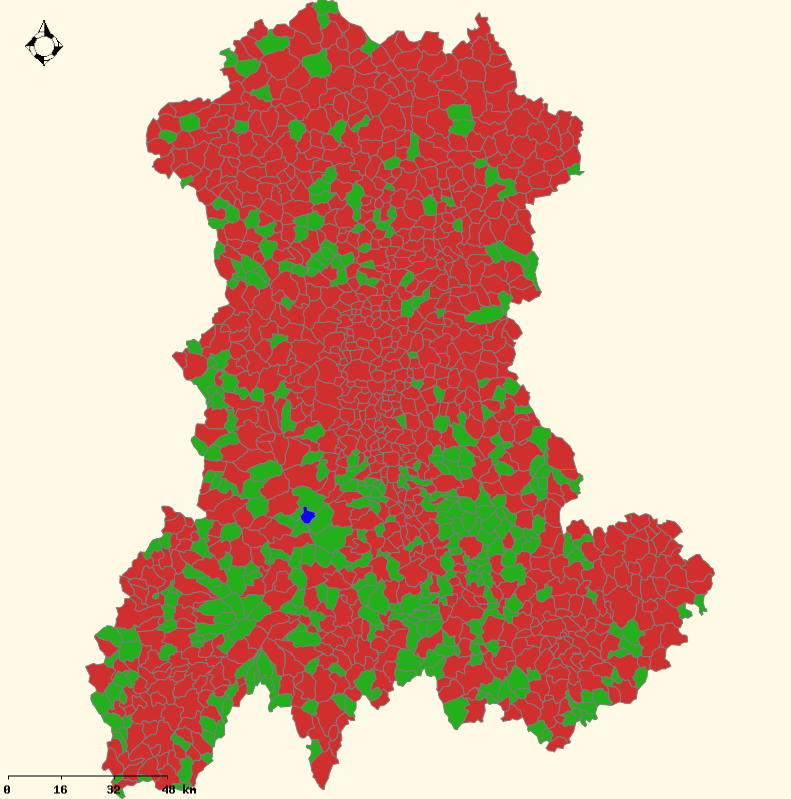 (a)
(a)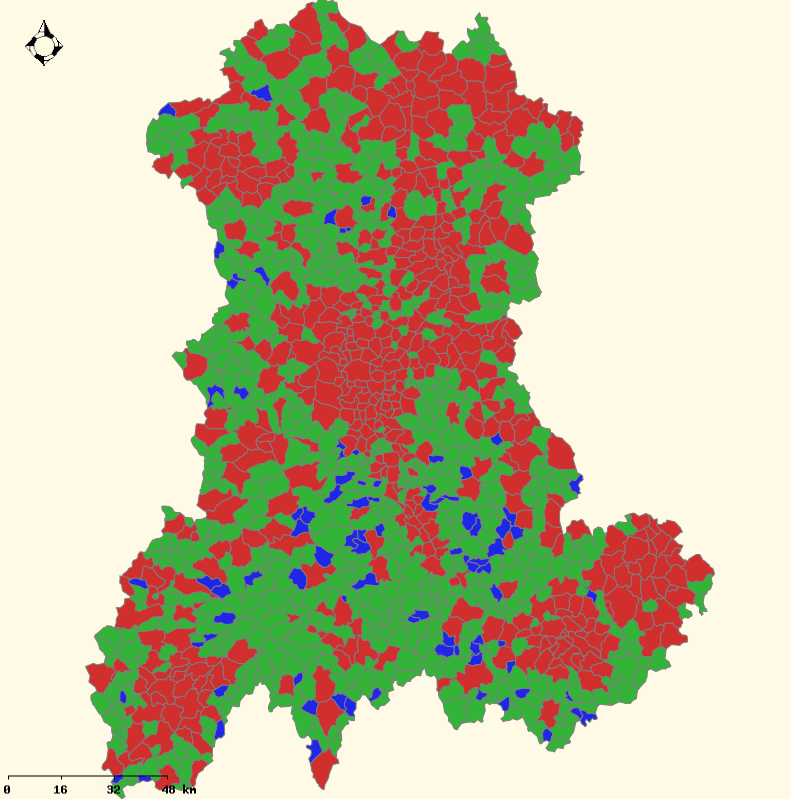 (b)
(b)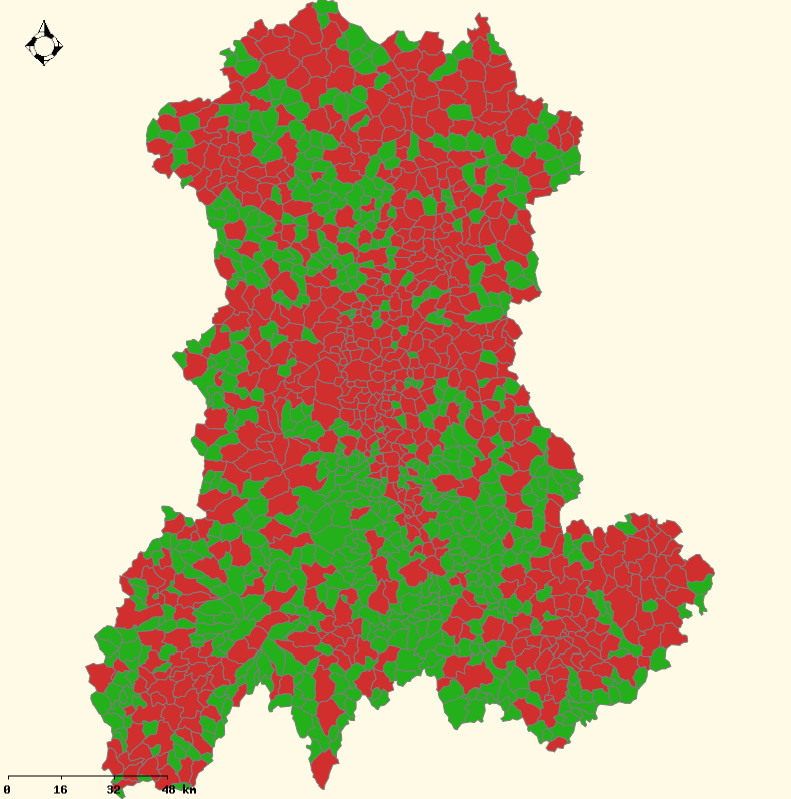 (c)
(c)
Appendix A:
-
Figure 4: Barplots of individual's and household's attributes for the Auvergne region. (a) Household's size. (b) Household's type. (c) Individual's age distribution. In black, the reference population. In dark grey, the population obtained with the sample-free method (1000 maximal iterations). In light grey, the population obtained with the sample-based method (25% of the reference household population). The bars represent the standard deviations obtained with 10 replications. 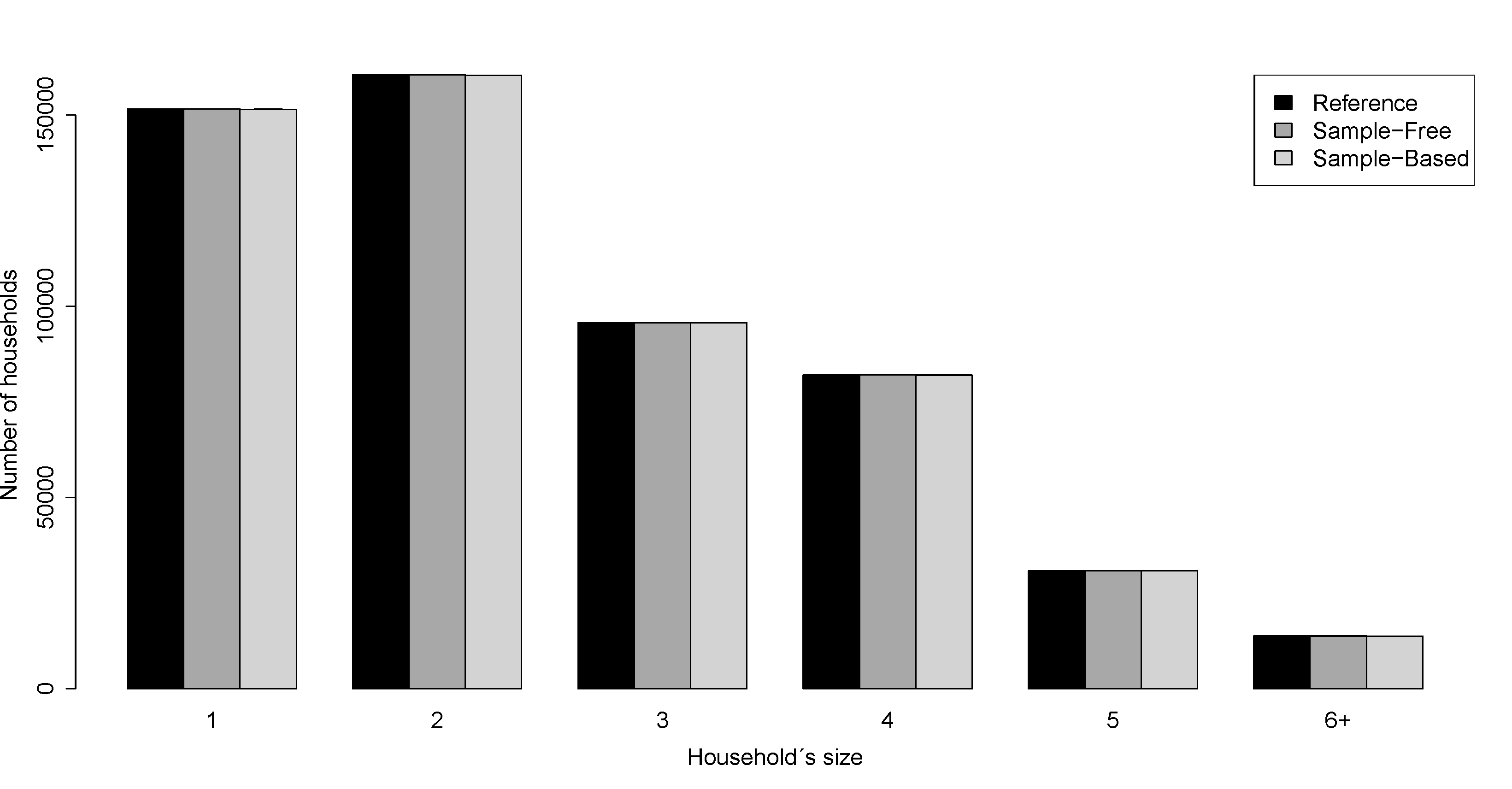 (a)
(a)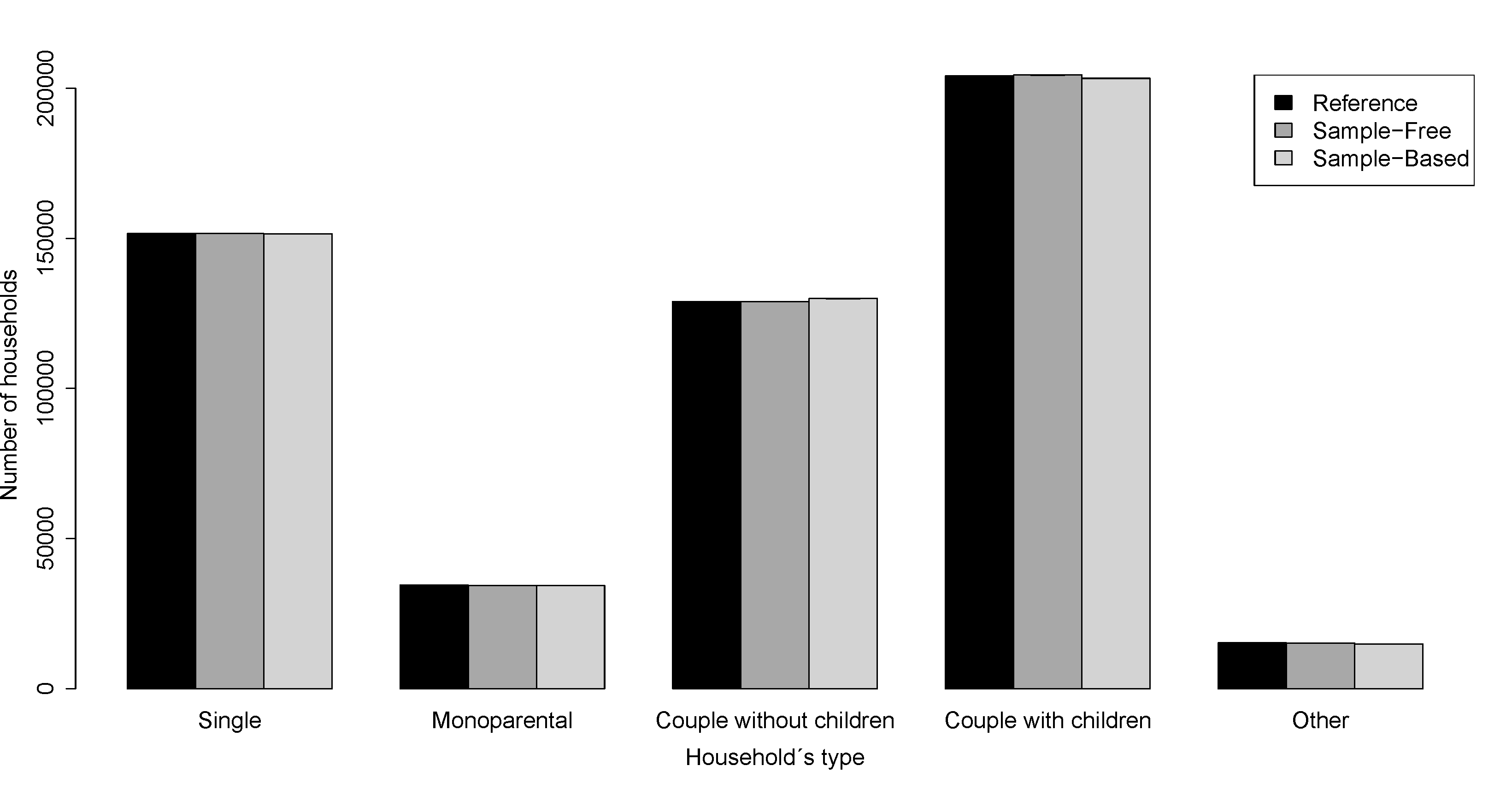 (b)
(b)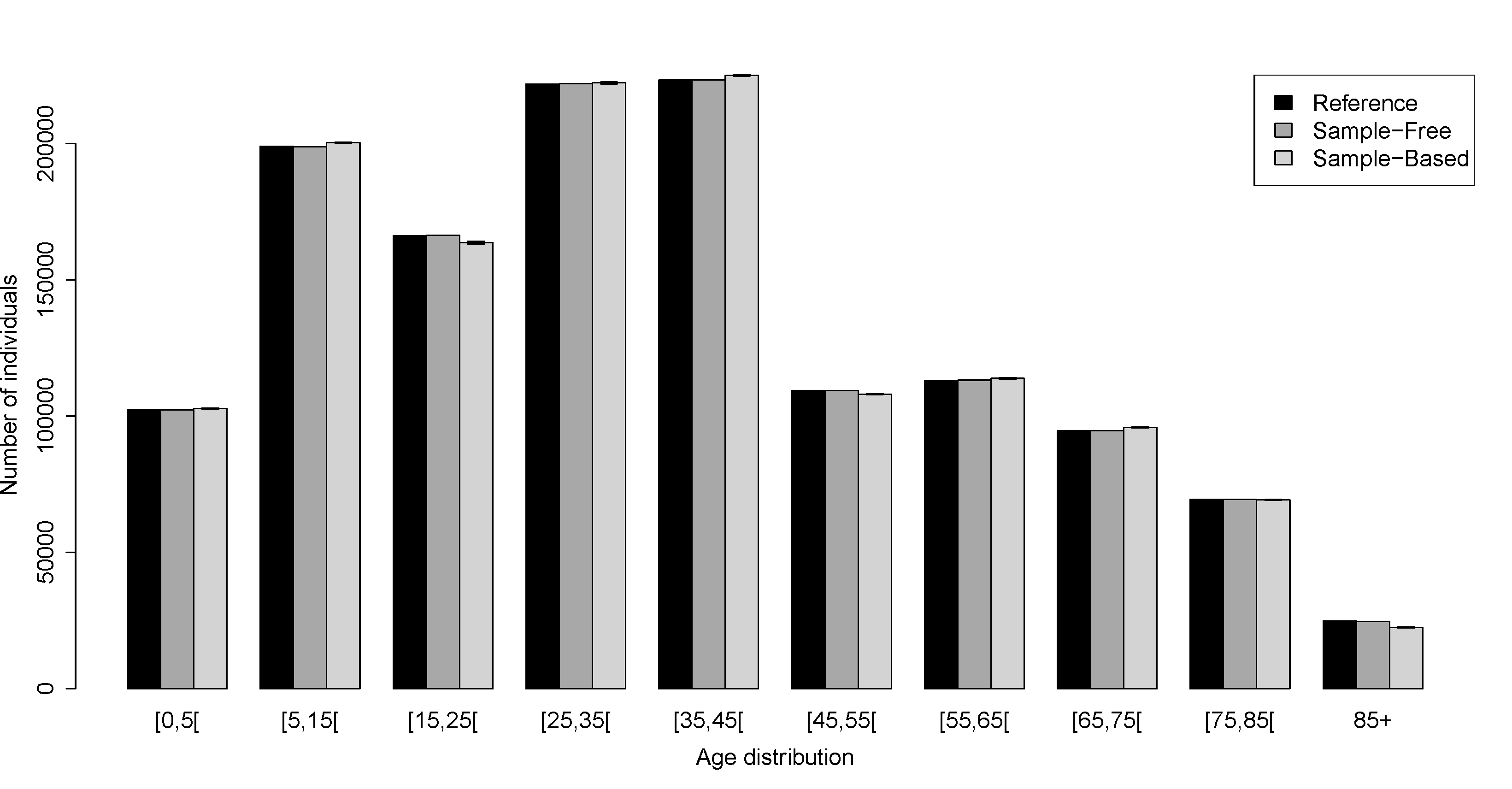 (c)
(c)Figure 5: Barplots of individual's and household's attributes for Marsac-en-Livradois, a municipality drawn at random among the 1310 Auvergne municipalities. (a) Household's size. (b) Household's type. (c) Individual's age distribution. In black, the reference population. In dark grey, the population obtained with the sample-free method (1000 maximal iterations). In light grey, the population obtained with the sample-based method (25% of the reference household population). The bars represent the standard deviations obtained with 10 replications. 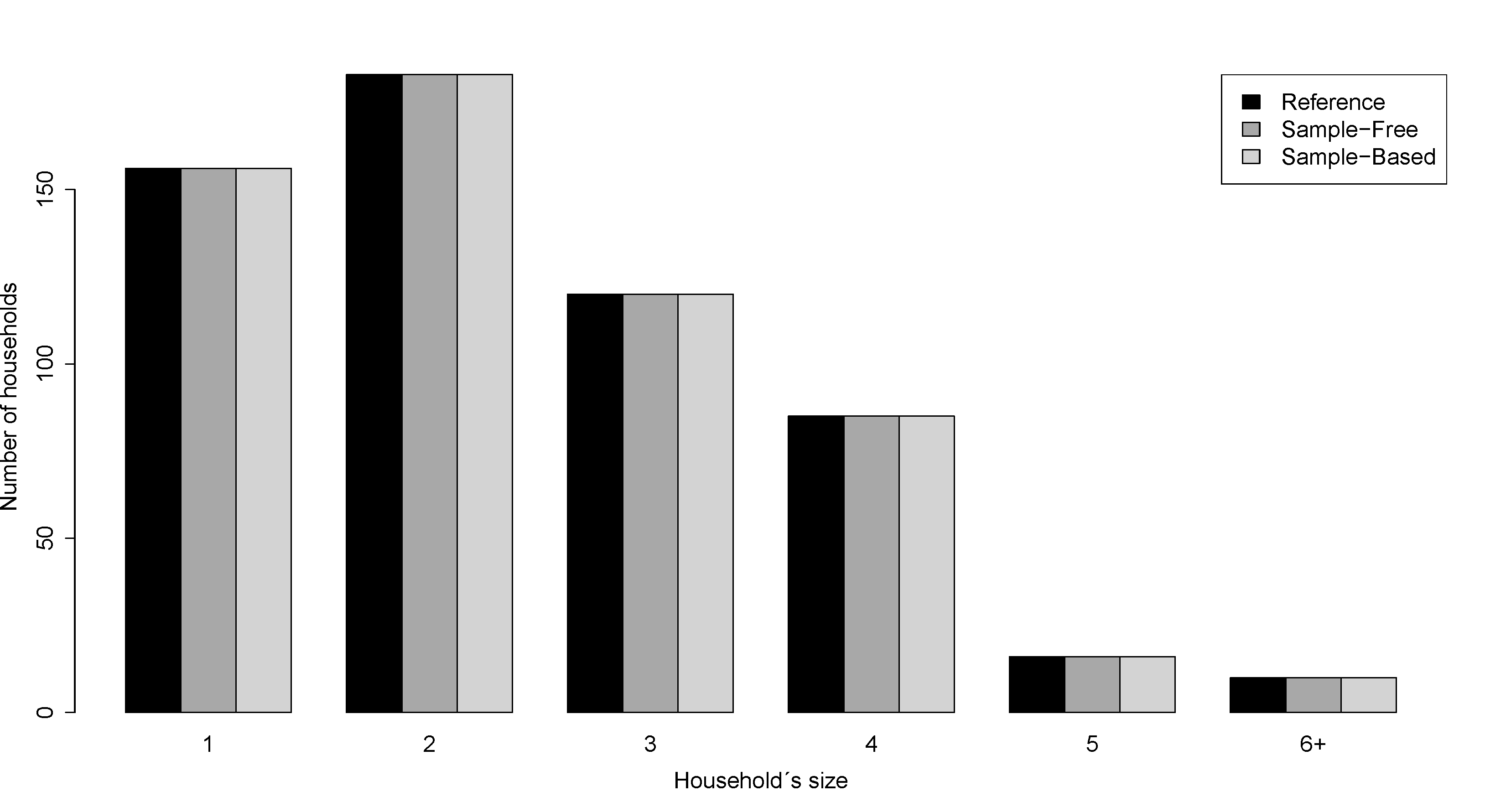 (a)
(a)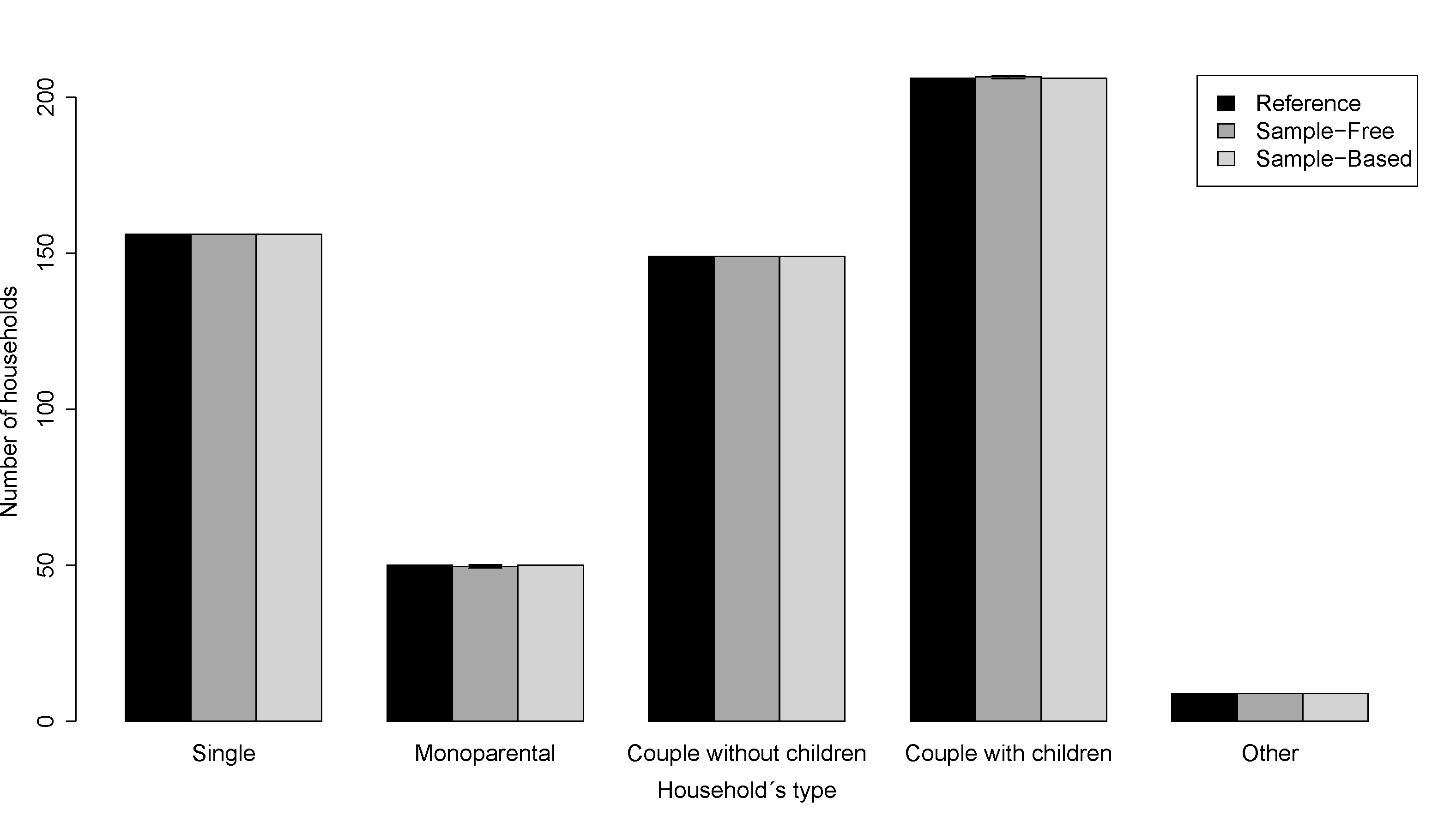 (b)
(b)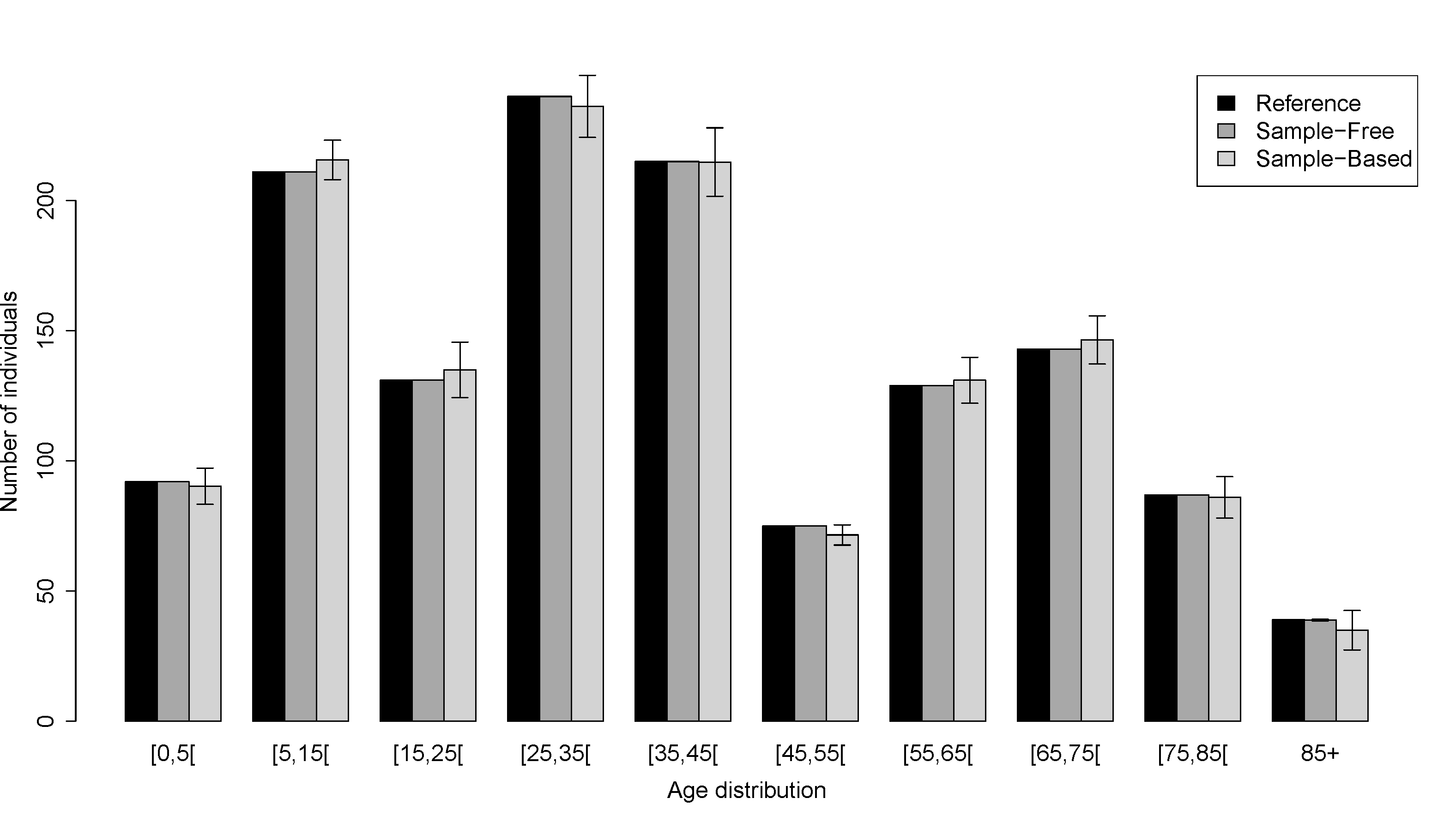 (c)
(c)
Acknowledgements
- This publication has been funded by the Prototypical policy impacts on multifunctional activities in rural municipalities collaborative project, European Union 7th Framework Programme (ENV 2007-1), contract no. 212345. The work of the first author has been funded by the Auvergne region.
References
-
ARENTZE, T., TIMMERMANS, H. & HOFMAN, F. (2007).
Creating synthetic household populations: Problems and approach.
Transportation Research Record: Journal of the Transportation
Research Board 2014, 85-91. [doi:10.3141/2014-11]
BARTHELEMY, J. & TOINT, P. L. (2013). Synthetic Population Generation Without a Sample. Transportation Science 47, 2, 266-279. [doi:10.1287/trsc.1120.0408]
BECKMAN, R. J., BAGGERLY, K. A. & MCKAY, M. D. (1996). Creating synthetic baseline populations. Transportation Research Part A: Policy and Practice 30(6 PART A), 415-429. [doi:10.1016/0965-8564(96)00004-3]
DEMING, W. E. & STEPHAN, F. F. (1940). On a least squares adjustment of a sample frequency table when the expected marginal totals are known. Annals of Mathematical Statistics 11, 427-444. [doi:10.1214/aoms/1177731829]
GARGIULO, F., TERNES, S., HUET, S. & DEFFUANT, G. (2010). An iterative approach for generating statistically realistic populations of households. PLoS ONE 5(1). [doi:10.1371/journal.pone.0008828]
GUO, J. Y. & BHAT, C. R. (2007). Population synthesis for microsimulating travel behavior. Transportation Research Record: Journal of the Transportation Research Board 2014, 92-101. [doi:10.3141/2014-12]
HARLAND, K., HEPPENSTALL, A., SMITH, D. & BIRKIN, M. (2012). Creating realistic synthetic populations at varying spatial scales: A comparative critique of population synthesis techniques. Journal of Artificial Societies and Social Simulation 15(1), 1. https://www.jasss.org/15/1/1.html.
HUANG, Z. & WILLIAMSON, P. (2002). A comparison of synthetic reconstruction and combinatorial optimization approaches to the creation of small-area microdata. Working paper, Departement of Geography, University of Liverpool.
VOAS, D. & WILLIAMSON, P. (2000). An evaluation of the combinatorial optimisation approach to the creation of synthetic microdata. International Journal of Population Geography 6(5), 349-366. [doi:10.1002/1099-1220(200009/10)6:5<349::AID-IJPG196>3.0.CO;2-5]
VOAS, D. & WILLIAMSON, P. (2001). Evaluating goodness-of-fit measures for synthetic microdata. Geographical and Environmental Modelling 5(2), 177-200. [doi:10.1080/13615930120086078]
WILSON, A. G. & POWNALL, C. E. (1976). A new representation of the urban system for modelling and for the study of micro-level interdependence. Area 8(4), 246-254.
YE, X., KONDURI, K., PENDYALA, R. M., SANA, B. & WADDELL, P. (2009). A methodology to match distributions of both household and person attributes in the generation of synthetic populations. In: 88th Annual Meeting of the Transportation Research Board.