
 Abstract
Abstract
- Decentralised experimentation and mutual learning of public policies is seen as one of the important advantages of federal systems (Oates: laboratory federalism). Based upon Hayekian ideas of the advantages of decentralised experimentation (as a discovery procedure), we analyse the long-term benefits of parallel experimentation in a federal system from an evolutionary economics perspective. We present a simulation model in which the lower-level jurisdictions in a federal system experiment with randomly chosen policy innovations and can imitate the relatively best solutions. The simulations confirm our hypotheses that a higher degree of decentralisation has positive effects on the long-term accumulation of knowledge of suitable policy solutions and also limits risks through better protection against erroneous policies. Also problems of policy learning and trade offs with (static and dynamic) advantages of centralisation are taken into account.
- Keywords:
- Laboratory Federalism, Policy Learning, Policy Innovation, Decentralisation
Introduction
- 1.1
- Centralisation / harmonisation vs. decentralisation is one of the most intensely discussed policy questions, both in the EU and in many other countries. The argument that decentralised federal systems might be more conducive to the innovation and adaptability of public policies due to the advantages of decentralised experimentation and mutual policy learning has in recent years gained a surprising momentum. It can be found in the economic federalism theory (laboratory federalism, Oates 1999), in the economic and legal discussion on interjurisdictional / regulatory competition, and in the political science literature on policy innovation and learning. Despite a large literature on policy innovation, policy learning and laboratory federalism, the basic argument about the advantages of parallel experimentation in a federal system has not been analysed so far in a formal model. Kollman et al. (2000) is the only paper that analyses the benefits of a decentralised parallel search for policy solutions in comparison to a centralised search. In contrast to their search-theoretic model, we want to analyse the long-term benefits of parallel experimentation in a decentralised federal system from an evolutionary economics perspective. This is based upon Hayekian ideas of the knowledge problem and the advantages of decentralised experimentation (as a discovery procedure) and the fundamental insight of evolutionary economics into the pivotal role of the generation of variety. We present a simulation model in which the lower-level jurisdictions in a federal system experiment with randomly chosen policy innovations and can imitate the relatively best solutions. Our aim is to study the long-term accumulation of knowledge of suitable policy solutions under different institutional settings. The simulations confirm our hypotheses that a higher degree of decentralisation has positive effects on the generation of better policies and also limits risks through better protection against erroneous policies. We will show that this result remains even when widely discussed problems of policy learning are taken into account. Also trade offs between these benefits of decentralised experimentation and (static and dynamic) advantages of centralisation are analysed.
- 1.2
- In section 2 we explain the theoretical background of policy innovation and decentralised experimentation in federal systems from an evolutionary economics perspective and present the main hypotheses. Section 3 encompasses the basic simulation model and the results of three different groups of simulations under different assumptions. A brief discussion of the results can be found in the final section 4.
Laboratory Federalism: Theoretical Background and Hypotheses
-
Policy Innovation and Policy Learning in Multi-Level Systems of Jurisdictions
- 2.1
- Our knowledge about appropriate public policies is limited. We have to assume that the best policies have not yet been found and that policies working satisfactorily so far can fail in the future due to economic, social and technological change. An evolving society does not need only technological innovations but also a corresponding co-evolution of institutions and public policies.[1] Therefore, searching for better policies is a permanent task from an evolutionary economics perspective. In the last two decades a fast growing literature has emphasized the advantages of improving policies through learning from the experiences of others. In political science, a large (primarily empirical) literature has emerged about policy innovation and policy learning (Dolowitz and Marsh 2000). However, the main thrust of these studies focusses on the determinants, benefits and problems of policy transfers between countries, which can be closely linked to the more general literature on diffusion as part of modern innovation research (Rogers 1995). This can be also seen as the theoretical background for the "Open Method of Co-ordination" (OMC) as a new governance instrument of the EU, which intends to promote policy learning of the Member States by evaluating their (decentrally implemented) policies in a kind of benchmarking approach ("best practices") and then recommending the best policies to the Member States (Borrás and Jacobsson 2004; Kerber and Eckardt 2007). A parallel discussion can also be found in law, in which regulatory competition has been viewed as a method of how superior legal rules and regulations might be identified and spread by imitation (Ogus 1999; Van den Bergh 2000). The common insight of all these strands of literature is that learning from the successful policies of other countries can be very helpful for improving public policies but might also be hampered or even fail due to a number of impediments and problems. All of these issues are also deeply intertwined with the discussions about centralisation (or: harmonisation) vs. decentralisation.
- 2.2
- In economics, the economic theory of federalism has provided a number of criteria for assessing the positive and negative welfare effects of centralised and decentralised policies in order to determine the optimal vertical allocation of competencies. The basic idea that federal systems with decentralised policies can also be viewed as laboratories for experimenting with new policies has led to the concepts of policy laboratories or laboratory federalism (Elazar 1987; Oates 1999).[2] This has been linked with the theory of interjurisdictional (and regulatory) competition as part of competitive federalism, in which the lower-level jurisdictions compete for firms and production factors by improving their public policies (including legal rules). There is a large literature on the advantages and problems of these competition processes as well as on the necessity to differentiate between several types of interjurisdictional and regulatory competition (due to different mobility assumptions).[3] The advantages of interjurisdictional competition in regard to the innovation and imitation of new policies is one of the crucial arguments in this discussion. After much theoretical and empirical research about these issues, there seems to be a wide-spread consensus that the question of the optimal structure of a federal multi-level system of jurisdictions must be seen as the result of complex trade offs between the advantages and disadvantages of both centralisation and decentralisation as well as of the benefits and problems of interjurisdictional (or regulatory) competition, leading to different optimal solutions for different policies and regulations. It also implies that these advantages of decentralised experimentation are only one important effect among a number of other relevant ones.
- 2.3
- Although the idea of federal systems as laboratories is widely quoted, there is nearly no theoretical research about this mechanism of decentralised experimentation and mutual learning in federal systems. Oates (1999), for example, emphasizes the utmost importance of this effect but he does not attempt to grasp it theoretically, perhaps because it might not be compatible with his otherwise static neoclassical approach to federalism theory. Only Kollman et al. (2000) have studied in a theoretical model the advantages of a decentralised parallel search of new policy solutions in federal systems. Drawing on previous research about a decentralised search in large organizations (e.g., Chang and Harrington 1998), they analysed different institutional settings in federal states (centralism, local autonomy without mutual learning, and policy laboratories, in which the central level forces the subunits to incremental or direct adoption of the better policy solutions) in regard to their suitability for solving policy problems with different difficulties. They can show that there are advantages of a decentralised parallel search for policy solutions, but since they assume that the central level has more competence for solving difficult problems their model leads to a trade off between the advantages of a decentralised parallel search and centralised problem-solving. Their main results are that both very easy problems and very difficult problems might be best solved centrally, whereas in the case of moderately difficult problems, policy laboratory solutions with a decentralised search might be a superior institutional solution in federal systems. Kollman et al's search-theoretic model is a valuable contribution for analysing the effects of an institutionalised policy laboratory in a federal system. However, they have focussed on the analysis of a top-down form of policy laboratories in which the central level organises a decentralised parallel search and mutual learning; there is no ongoing competitive process of experimentation between the federal subunits, and they mainly focus on the impact of problem difficulty.
- 2.4
- We want to model the long-term knowledge accumulation effect through decentralised experimentation by using an evolutionary approach.[4] The generation and diffusion of knowledge of better public policies in a federal system is modelled through a multi-period stochastic simulation model. The basic driving-force for the evolution of policies is the continuously generated variety of policy solutions (policy innovations) coupled with a selection mechanism, which identifies the relatively best policies and induces their spreading through imitation. We use an evolutionary concept of interjurisdictional competition in which the lower-level jurisdictions—along Hayekian ideas of competition as a discovery procedure (Hayek 1978)—experiment with new policies, leading to feedback for the competing jurisdictions with the possibility to learn from the relatively best policy solutions. Different transmission mechanisms can be assumed for the competition between the lower-level jurisdictions, either through simple yardstick competition, interjurisdictional competition via mobility of firms and production factors, or through free choice of law as one form of regulatory competition (Vanberg and Kerber 1994; Kerber 2008). Therefore, from our evolutionary economics perspective, the basic idea of laboratory federalism is that a decentralised competitive system of jurisdictions will lead to a more rapid improvement of public policies due to parallel experimentation and mutual learning, driven by variety and competition among the lower-level jurisdictions (Kerber 2005).
Decentralised Experimentation and Mutual Learning: Hypotheses
- 2.5
- With our simulation model we want to test a number of hypotheses about the determinants and potential problems of such processes of decentralised experimentation and mutual learning. We assume a two-level system of jurisdictions (as, e.g., the EU and its member states, or the US and the federal states), in which the competencies for policies can be allocated to the central level or the lower-level jurisdictions. We are interested in the long-term performance of the whole set of public policies within this federal system, aggregated as the sum of performance values of each policy. Whereas the centralised policies can only experiment sequentially, parallel processes of experimentation and mutual learning can take place for decentralised policies at lower-level jurisdictions. In each period all policies are going through a phase of innovation (modelled as a stochastic process), followed by an imitation phase in the case of decentralised policies. We do not model the competitive threat through a particular form of interjurisdictional competition explicitly; however, the assumptions about the necessity of imitating superior policies suggest considerable incentives for not lagging behind in this competition. Our main hypotheses refer to the impact of the extent of decentralisation in a federal system, both on the long-term overall performance of all public policies and its dispersion.
- HYPOTHESIS 1: The larger the degree of decentralisation (proportion of decentralised to all policies), the higher the long-term overall performance of the set of policies in a federal system.
Since the knowledge generation effect through parallel experimentation cannot work on the central level, a higher overall performance can be expected if more policies are decentralised.
- HYPOTHESIS 2: The larger the number of lower-level jurisdictions, the higher the long-term overall performance of the set of policies in a federal system (for a given degree of decentralisation).
If a larger number of jurisdictions experiment with new policies, the variety of policy innovations increases, leading to better policies, which can be imitated by others. The effect that a larger number of parallel experiments might generate faster superior innovations is also wellknown in regard to parallel research in innovation economics (Linge 2008).
- HYPOTHESIS 3: The more decentralised a federal system, the larger the error-correcting forces through mutual learning, leading to a smaller dispersion of the long-term overall performance of the set of policies in a federal system.
Larger decentralisation (i.e., higher degree of decentralisation and/or more lower-level jurisdictions) allows for much easier and faster corrections of erroneous policies through imitating superior policies. This should lead to a smaller dispersion of the overall performance values of its implemented policies in the long run, i.e. that decentralisation can also be interpreted as an insurance against the negative effects of wrong policy decisions.
- HYPOTHESIS 1: The larger the degree of decentralisation (proportion of decentralised to all policies), the higher the long-term overall performance of the set of policies in a federal system.
- 2.6
- Both from the political science discussion and the literature on the diffusion of innovations, we know that knowledge generation and learning from others can be difficult (Rogers 1995). Therefore we cannot suppose that parallel experimentation and mutual learning will always run smoothly without being hampered by a number of problems. For example, in the legal discussion there is a well-developed literature about the problems of "legal transplants", i.e. the difficulties that legal rules that work successfully in one legal system might not work equally well when transplanted into another legal system (Berkowitz et al. 2003a, 2003b; Mousourakis 2010). This effect that imitated legal rules might work differently in another institutional setting is similar to claims in the political science literature that the effectiveness of policies is context-specific (Radaelli 2003). Therefore, in a second step (in section 3.3), we want to test whether the above hypotheses still hold under conditions that hamper the knowledge generation process of parallel experimentation and mutual learning. How do the results change, (1) if part of the decentralised policies cannot be imitated by other jurisdictions (non-imitability), and (2) if there are (limited) complementarities between policies, i.e. that an isolated transplanting of a policy from another jurisdiction reduces its effectiveness (transplant effect)? In a third group of simulations we investigate the problem of trade offs between this advantage of decentralisation through decentralised experimentation and important advantages of centralisation (section 3.4). These simulations will focus only on two arguments: (1) The central level might have a (static) cost advantage for providing a policy compared to the provision by lower-level jurisdictions (e.g., due to economies of scale). (2) The central level can also have a superior innovation capability for public policies in comparison to the lower-level jurisdictions (e.g., due to larger financial resources). To what extent can the above hypotheses still be confirmed, if the central level of a federal system has one of these advantages?
Simulations
-
Basic Model
- 3.1
- In a federal two-level system of jurisdictions, consisting of one central jurisdiction and n lower-level jurisdictions, we assume that m different policies are carried out to fulfill the preferences of the citizens. The competencies for these policies can be allocated either to the central level or the lower-level jurisdictions. The set of mc centralised policies is denoted as C, whereas D represents the set of md decentralised policies (with m = mc + md). The performance of a policy i (i = 1, … , m) in each jurisdiction j in period t is represented by a performance value fijt. The index j = 0 denotes the central level of the federal state, and j = 1, … n the n lower-level jurisdictions. The performance value of a policy can be interpreted as a quality or productivity index, which indicates the extent of the fulfillment of citizens' preferences through the policy (either directly or indirectly by contributing to the productivity of firms). For simplification, we assume that both the policies and the lower-level jurisdictions are equally important, i.e. they have the same impact on the performance values (equal weights). Therefore the overall performance of the entire set of policies in the federal system in period t, Gt, can be calculated as the simple (unweighted) average of the performance values of all m policies in this federal state, either implemented at the central or decentral level:
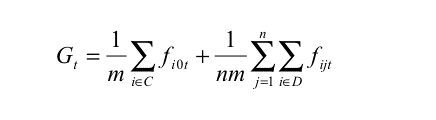
(1) - 3.2
- All jurisdictions try to improve their performance by searching for better policies through (1) experimentation with new policies and (2) imitation of more successful policies. Each period consists of an innovation and an imitation phase. In the innovation phase both the central level and the lower-level jurisdictions search for better problem solutions for all the policies within their competence. Since the effectiveness of new policy innovations cannot be known ex ante, they are modelled as stochastic processes, i.e., as drawing from sets of new policies. It is assumed that the performance of these new policies are normally-distributed with a variance of σ2 > 0 and an expected value E(f'ijt). f'ijt denotes the performance value of the policies after innovation. Although, on average, we assume that the jurisdictions are successful in their search for better policies (E(f'ijt) = η E(fijt-1) with η > 1), temporary deteriorations of policies are also possible. These stochastic innovation processes take place independently from each other for all policies on the central level and in all lower-level jurisdictions.
- 3.3
- The jurisdictions cannot know the effectiveness of their new policies before their implementation, but this information is revealed at the end of the innovation phase (as experience from this experiment). It can be the result of an explicit policy evaluation or the outcome of assessments through private agencies, investors, media, or the citizens themselves. In this basic model we assume that this assessment is clear and reliable enough for a comparison of the performance of the policies of different jurisdictions. In particular, we assume that the relatively best policy can be identified, and that this information is revealed to all jurisdictions.[5] If k denotes the lower-level jurisdiction with the highest performance value of policy i after innovation (f'ikt), it follows: f'ikt = max f'ijt [max over j = 1, … , n]. Due to the incentives through interjurisdictional competition it can be expected that the jurisdictions try to imitate these best policies. Since imitation takes time and might be difficult, we assume that during the imitation phase the jurisdictions are only able to catch up to a certain extent with the best policies (imitation rate λ , with 0 < λ < 1). The imitation process can be described as follows (for j = 1, …, n):[6]
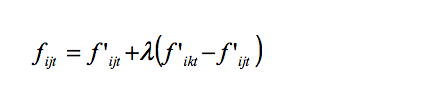
(2) - 3.4
- After the imitation process of the first period, the second period begins, in which again all jurisdictions innovate and imitate in the same way. In the following, we use this basic simulation model for testing our set of hypotheses (section 2.2). Since we are interested in the long-term overall performance of the policies, 100 of these periods consisting each of an innovation and an imitation phase are simulated. The presented results are based upon 50,000 simulation runs with the following parameters: η = 1.01, σ = 0.05, λ = 0.5, m = 8, and a normalised starting performance value for all policies, fijt=0 = 1.[7]
Simulation Results I: Effects of Decentralisation in the Basic Model
- 3.5
- Hypothesis 1 states that a larger degree of decentralisation d (with d = md / m) would lead to a higher overall performance of the policies of the federal system Gt=100. In our simulations we investigated the effects of a variation of d (d = 0, 0.25, 0.5, 0.75, 1) and of the number of lower-level jurisdictions n (n = 4, 8, 12, 16, 20)[8] on Gt=100. The latter simultaneously tests our hypothesis 2 in regard to the positive effects of the number of parallel experimenting jurisdictions on the knowledge generation. In Figure 1(a) (see Table 1 in Appendix) the average Gt=100 can be seen in dependence of the degree of decentralisation d and the number of lower-level jurisdictions n. Since we assume an expected 1% increase in the performance of policies solely through the innovation process each period (η = 1.01), the overall performance of the policies in a fully-centralised system also increases from Gt=0 = 1 to Gt=100 = 3.72. However, Gt=100 increases much more in more decentralised federal states. Both hypotheses have been confirmed by our simulations: Independent from the number of lower-level jurisdictions, a higher degree of decentralisation leads to a larger overall performance of the policies Gt=100. At the same time, a larger number of lower-level jurisdictions increases Gt=100 for all degrees of decentralisation (with the exception of the fully-centralised case d = 0). Another result is that the additional knowledge generation effects through one additional experimenting jurisdiction decreases with larger n (i.e., there are positive but decreasing marginal benefits of more parallel experimentation; see also Kollman et al. 2000, 110).
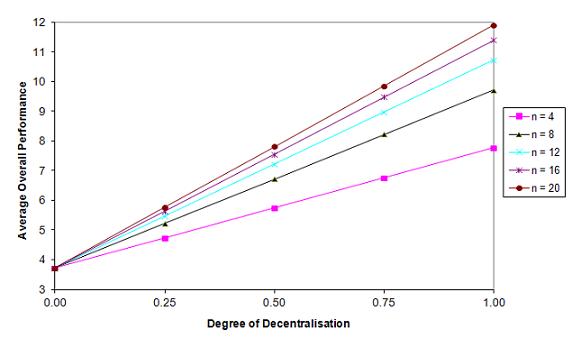
(a) Average overall performance Gt=100 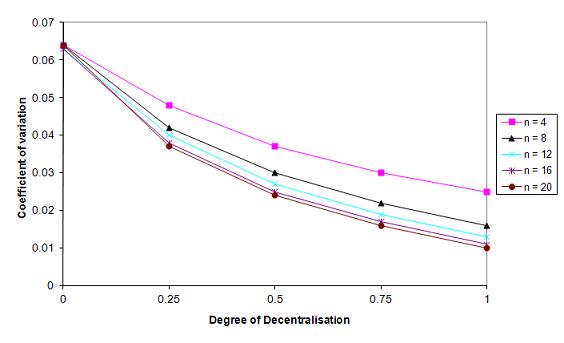
(b) Coefficient of variation cv Figure 1. Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d and the Number of Lower-Level Jurisdictions n (after 100 periods in 50,000 simulation runs) - 3.6
- A more decentralised federal system does not only lead to a higher average overall performance of policies, it might also narrow down the dispersion of the expected overall performance of these policies (hypothesis 3). The numbers in parentheses in Table 1 (Appendix) show the coefficient of variation cv and the standard deviation of the overall performance values Gt=100 of all 50,000 simulation runs.[9] Whereas the standard deviation is a measure for the absolute size of the dispersion, the coefficient of variation cv as a measure for relative dispersion is more suitable for comparing dispersions, if the average values are very different (as in our case). Therefore we will use the coefficient of variation cv as the relevant measure for testing hypothesis 3. The results in Figure 1(b) clearly show that cv decreases considerably with an increasing degree of decentralisation d and an increasing number of lower-level jurisdictions n (except for d = 0). It is interesting that this is true even for the standard deviation despite the much higher Gt=100 in more decentralised systems. This clear confirmation of hypothesis 3 is a very important result, because risk-averse citizens are not only interested in the expected average overall performance of policies in a federal system but also in avoiding the risk of ending up with a bad performance due to erroneous policies. Since we assume that policy innovation is characterised by high uncertainty, the capabilities of a federal system to detect and correct erroneous new policies are very important for its assessment. Therefore a decentralised federal system can fulfill a crucial insurance function against mistaken policies.[10] It is a very striking result that - contrary to many other problems in economics - here no trade off exists between a higher expected overall performance and a lower dispersion of this performance (i.e. a lower risk of a bad outcome): A more decentralised federal system facilitates the achievement of both objectives simultaneously.[11]
Simulation II: Taking into Account Imitation Problems and the Transplant Effect
- 3.7
- In a second group of simulations we want to test whether our three hypotheses still hold if we use less ideal assumptions for the process of parallel experimentation and mutual learning. Both in the policy innovation / transfer discussion in political science and the innovation economics literature on diffusion, as well as the law and economics literature on the legal transplant problem it has been argued that the imitation of a successful policy (or a legal rule) can be difficult or even fail due to a number of problems (see for an overview Kerber and Eckardt 2007, 234-239; Schnellenbach 2008). Imitation problems can be the result of lacking to observe policies (or how they are implemented), of the tacitness of knowledge, or of lacking knowledge and capabilities for the imitating jurisdictions. These problems can lead to an imitation lag but also to a lower effectiveness of the imitated policy. However, through the imitation parameter λ, imitation lags have been already taken into account in the basic model and it can be easily shown that a lower λ will slow down the knowledge generation process in decentralised federal systems.[12] Another possibility is that this imitation parameter λ can vary for different policies, enabling us to analyse the impact of the simultaneous existence of policies that are easy or hard to imitate. It is particularly interesting to study the impact on this knowledge generation effect through decentralised experimentation if (e.g., due to cultural reasons and/or specific institutional path dependencies) certain policies are not imitable at all for other jurisdictions.
Non-imitable Policies
- 3.8
- In the following simulations, we have analysed the impact of one or two non-imitable policies on the overall performance Gt=100 and its dispersion. In Figure 2 (see Table 2 in Appendix), it can be seen that an increasing number of non-imitable policies mh (mh = 0, 1, 2) leads (for any degree of decentralisation d and number of lower-level jurisdictions n) to a lower overall performance of the entire set of policies and to larger coeffients of variation, i.e. that the positive effects of decentralisation are smaller compared to the absence of non-imitable policies. Since the knowledge generation effects of decentralisation cannot work on these non-imitable policies, this weakening of the positive effects of decentralised experimentation is not surprising. However, the inclusion of some non-imitable policies does not change the confirmation of all three main hypotheses, i.e. that the positive effects of an increase of d and n on the overall performance of the policies in a federal system Gt=100 as well as their negative effects on its dispersion (cv) still holds.
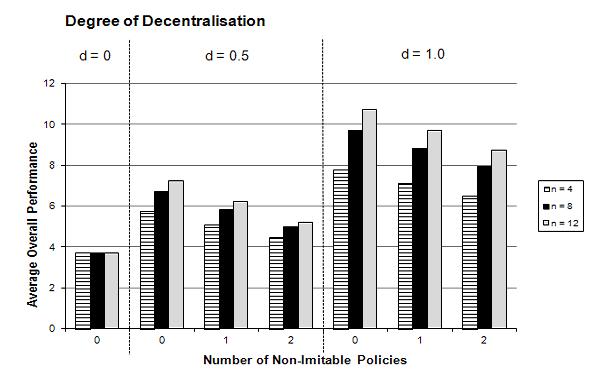
(a) Average overall performance Gt=100 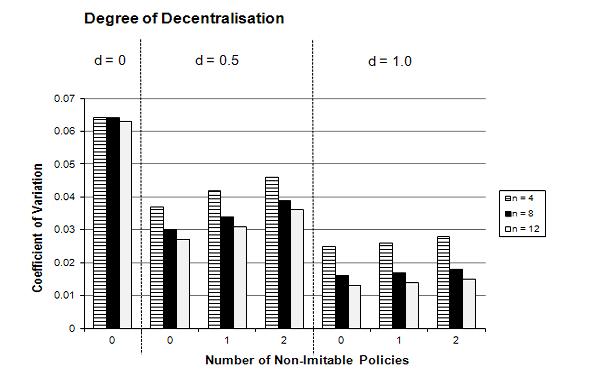
(b) Coefficient of variation cv Figure 2. Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and the Number of Non-Imitable Policies mh (after 100 periods in 50,000 simulation runs) Transplant Effect
- 3.9
- Another special type of imitation problem is the already mentioned transplant effect. Its basic idea is that a legal rule (or, generally, a policy) that works successfully in one jurisdiction can have a lower effectiveness in a different jurisdiction. In the legal discussion, this empirically often well-observed effect is traced back to the problem that a foreign legal rule can lead to inconsistencies within the legal system because it does not fit in well with the other domestic rules.[13] This problem of "context dependence" has also been emphasized in the political science literature on policy innovation and policy transfer (Radaelli 2003). The transplant effect can be defined as the loss of effectiveness of a policy (or a legal rule), which is caused through its implementation in another jurisdiction with a different set of policies (Berkowitz et al 2003a, 170). Since empirically we can also observe a lot of successful policy imitations, such a transplant effect might or might not emerge, can be large or small, and might be permanent or only a temporary phenomenon (until a process of institutional adaptation has solved these problems). Therefore we will analyse the impact of limited transplant effects that might occur in the mutual learning processes between the lower-level jurisdictions. In the following, we assume that there might be pairs of policies which must fit to each other, i.e., that these two policies can be seen as complements (as, e.g., social and labor market policy). If these policies do not come from the same jurisdiction, we expect the emergence of some compatibility problems which reduce the performance of both policies through a multiplicative parameter κ (with 0 ≤ κ < 1). If both complementary policies have been developed in the same jurisdiction, no such effect will emerge.
- 3.10
- How can this be implemented in our simulation model? Nothing changes for all centralised and non-complementary policies. For decentralised policies, we introduce the possibility of such pairs of complementary policies. Since the transplant effect does not affect the innovation process, the generation of new policies in the innovation phase does not change. The decisive question, however, for the imitation of complementary policies is, whether the lower-level jurisdictions should stick to their own (pair of) innovations, imitate the best pair of these complementary policies (which would avoid a transplant effect), or imitate (as usually) the best policies of all jurisdictions separately. If the transplant effect is small, it can be expected that the positive effects of being able to select the best of both policies separately might dominate the transplant effect. In the following, the performance value of the best pair of two complementary policies a and b after the innovation phase is denoted by (f'alt + f'blt) (with l being the jurisdiction with this best pair), the best separate policies were denoted above as f'akt and f'bkt, and the transplant effect is given by κ. Then, the imitation of the jurisdictions for the complementary policies a and b can be described as follows:[14]
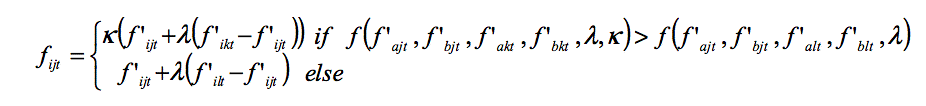
with
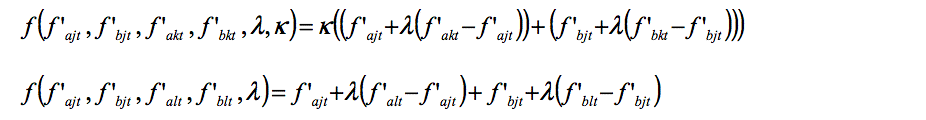
- 3.11
- For the three cases mk = 0, 1, and 2 pairs of complementary policies (with κ = 0.995), we ran simulations for different degrees of decentralisation d (d = 0, 0.5, 1) and different numbers of lower-level jurisdictions n (n = 4, 8, 12). The results in Figure 3 (see Table 3 in Appendix) show clearly that the transplant effect has a negative impact on the extent of knowledge generation. For any degree of decentralisation d and any number of lower-level jurisdictions n, the average overall performance of the policies in the federal system decreases and the coefficient of variation increases with the number of pairs of complementary policies mk. Therefore the transplant effect reduces the extent of the advantages of decentralised experimentation in federal systems. How can this be explained? Pairs of complementary policies reduce the positive effects of imitation, because either the best pair after innovation is imitated, whose aggregate performance value is nearly always smaller than the sum of the separately best performance values of both policies after innovation, or both policies are imitated separately, which, however, leads to a loss of performance through the transplant effect (with the parameter κ < 1). However, the results for our three hypotheses are not altered through the transplant effect: It is still true that a larger degree of decentralisation d and a larger number of experimenting lower-level jurisdictions n lead to a higher average overall performance of the policies of the federal system, irrespective of the number of pairs of complementary policies. Also, the insurance function of the federal system through error-correction is still working, i.e., also hypothesis 3 can be confirmed despite the emergence of transplant effects.
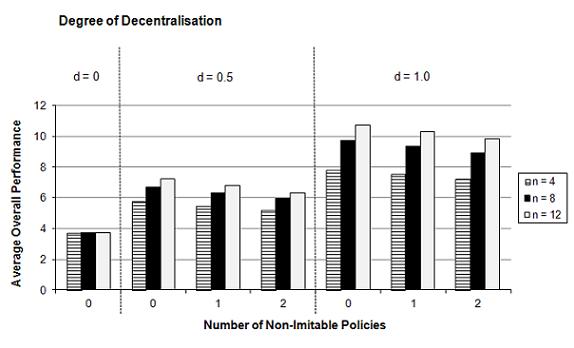
(a) Average overall performance Gt=100 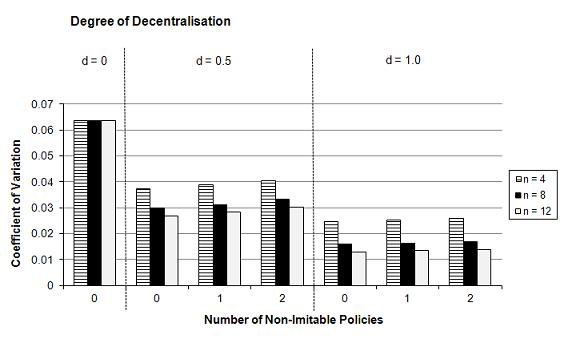
(b) Coefficient of variation cv Figure 3. Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and the Number of Pairs of Complementary Policies (with a Transplant Effect) mk (after 100 periods and 50,000 simulation runs) Simulation III: Decentralised Experimentation vs. Static and Dynamic Advantages of Centralisation
Static Cost Advantages on the Central Level
- 3.12
- Cost advantages on the central level can stem from direct economies of scale in the provision of a policy (e.g., through fixed set up costs) or from lower information and other transaction costs for firms and citizens due to one harmonised policy instead of n different policies. As for the trade off between these static cost advantages of centralised policies and the dynamic advantages of decentralised experimentation, it can be suggested, that in the long run, the faster knowledge generation about superior policies in more decentralised systems will lead to higher overall performance values than in more centralised systems, despite its static cost advantages. This would be an example of the (also otherwise well-known) trade off between static and dynamic effects. How can this be implemented in the simulation model? If, e.g., the central level could provide the policies with 20% lower costs than the lower-level jurisdictions, this cost differential can be taken into account by multiplying the performance value of centralised policies with a parameter ω (here: ω = 1.2). In the case of a cost advantage of the central level: ω > 1; in the not unrealistic (but here not analysed) reverse case of a cost disadvantage: ω < 1. Since this cost differential does not influence innovation and imitation, because it only increases all performance values of centralised policies through multiplication with ω, its effect can be taken into account by multiplying the starting performance value of centralised policies with ω, i.e. their starting value is ω instead of 1.
- 3.13
- The results of the simulations in Figure 4 (see Table 4 in Appendix) encompass the overall performance of policies Gt=100 and the coefficient of variation cv in dependence of ω (ω = 1.0, 1.2, 1.4), on d (d = 0, 0.5, 1) and n (n = 4, 8, 12). Since we also want to take into account some problems of decentralised knowledge generation, we ran the same simulations again with the additional assumption of two pairs of complementary policies with their transplant effect. The results show that an increasing static cost advantage on the central level ω increases (decreases) the overall performance Gt=100 (the coefficient of variation cv) for d = 0 and d = 0.5, because now the centralised policies have a higher performance value; of course, this can have no impact in the case of d = 1. Therefore such cost advantages on the central level have a positive impact on Gt=100 in our simulation model. However, these static cost advantages are not able to alter our main hypotheses: The overall performance values of the policies in a federal system still increase with a larger degree of decentralisation d and a higher number of lower-level jurisdictions n, as well as the coefficient of variation cv decreases with an increasing d and n. The explanation is that the initial static cost advantage of the central level is getting outpaced relatively fast by the dynamic advantages of decentralised experimentation and mutual learning. Therefore another approach of analysing this trade off would focus on the number of periods that are necessary for a more decentralised system to outpace a more centralised system with static cost advantages on the central level. As we would expect from our analysis in the last section, comparing the results with and without the transplant effect shows that the overall performance values are smaller and the coefficient of variation higher with two pairs of complementary policies. However, our main hypotheses still hold despite the transplant effect and static costs advantages. But we can presume that in such a case of a less smoothly running knowledge generation process more time is necessary for outpacing a more centralised system.
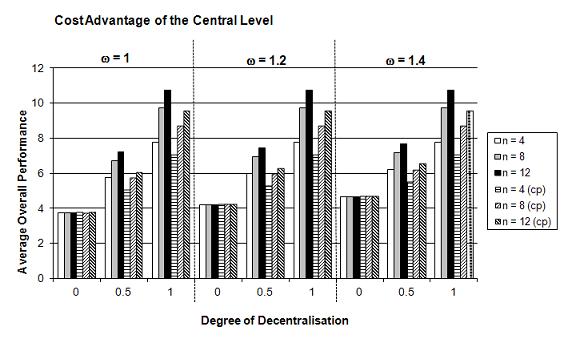
(a) Average overall performance Gt=100 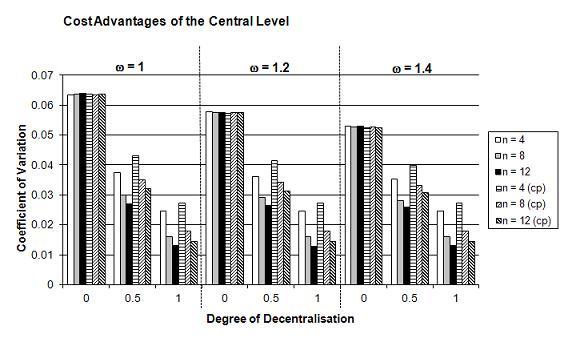
(b) Coefficient of variation cv Figure 4. Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and Different Cost Advantages of the Central Level ω (after 100 periods in 50,000 simulation runs) Superior Policy Innovation Capabilities on the Central Level
- 3.14
- The central government might have superior capabilities for the innovation of new policies, because it might have more financial resources or more and better qualified staff for developing and implementing new policies (see, e.g., Kollman et al. 2000), or it might better internalise the benefits of policy innovation due to less free-rider problems (Rose-Ackerman 1980). However, contrary to the first argument about static cost advantages, it is very unclear whether the central level is more innovative than lower-level jurisdictions, because there are often also much greater political rigidities on the central level which tend to block policy reforms and policy innovation. Empirically, it is an open question whether central governments or lower-level jurisdictions are more innovative (Strumpf 2002; Feld and Schnellenbach 2004). Following, we want to analyse what the implications for our three hypotheses about the advantages of laboratory federalism are, if we assume that the central level might have advantages in generating policy innovations. In our simulation model, superior capabilities for innovation can be taken into account through a higher expected increase of the performance values in the innovation phase, i.e. ηc (for centralised policies) > ηd (for decentralised policies). We have run simulations for different degree of decentralisations d (d = 0, 0.5, 1), different numbers of lower-level jurisdictions n (n = 4, 8, 12), and different ηc (ηc = 1.01, 1.015, 1.02, 1.025). ηc = 1.01 is the reference case, in which both jurisdictional levels have the same innovation capabilities. As in the case for static advantages, we simulated the impact of dynamic advantages both with and without two pairs of complementary policies in order to also test for a less ideal mechanism of decentralised experimentation and mutual learning.
- 3.15
- In regard to the impact of a higher innovation capability ηc on the central level, the results for the average overall performance Gt=100 in Figure 5 (see Table 5 in Appendix) show clearly that for lower values of ηc the advantages of decentralised experimentation and mutual learning remain larger than the dynamic advantages of the central level. But that above a certain critical threshold ηc*, the effects of the superior innovation capabilities of the central level dominate the advantages of decentralisation. This threshold ηc* also depends on the number f lower-level jurisdictions: For n = 4, it lies between ηc = 1.015 and ηc = 1.02, because in the latter case Gt=100 decreases with increasing d. For n = 8 and n = 12, the critical threshold ηc* lies between ηc = 1.02 and ηc = 1.025. This implies that the positive knowledge generation effects of a larger number of experimenting lower-level jurisdictions n counterbalance to a certain extent the higher innovation capability of the central level, i.e. a higher ηc is necessary for making the centralised system more successful. The inclusion of transplant effects does not change these results, although the lower effectiveness of decentralised experimentation leads to a lower critical threshold ηc*. A marginal case, for example, is n = 8 and ηc = 1.02, in which an increasing d leads first to a decrease of Gt=100 (d = 0: 8.192; d = 0.5: 7.929) and then again to an increase (d = 1: 8.688; see Table 5 in Appendix). All this implies that in the case of a sufficiently superior innovation capability of the central level, our first hypothesis does not hold any more: More decentralisation would lead to a lower overall performance of the policies of the federal state. However, empirically it might well be that ηc < ηd, which will reinforce the advantages of decentralised experimentation. An interesting result is that our second hypothesis still holds: independent from ηc, a higher number of lower-level jurisdictions n leads to an increase of Gt=100 (except again for d = 0). Also our third hypothesis is still confirmed: the coefficient of variation cv decreases with increasing d and increasing n (independent from ηc) — both with and without transplant effects.
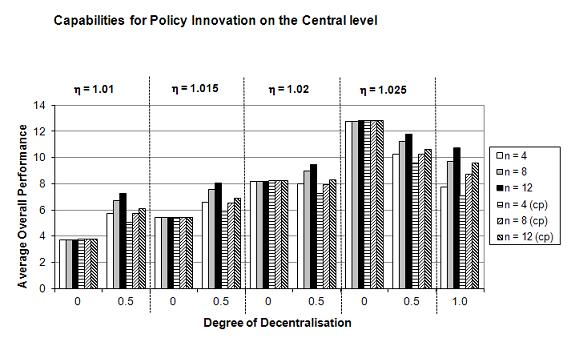
(a) Average overall performance Gt=100 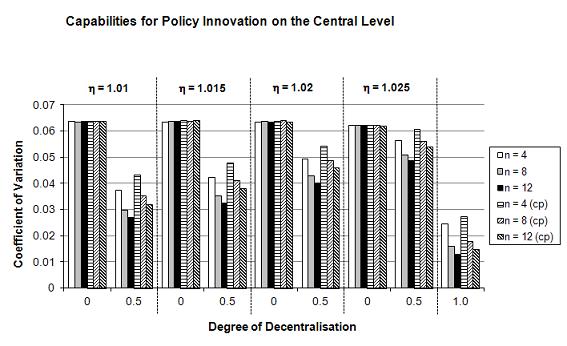
(b) Coefficient of variation cv Figure 5. Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and Different Capabilities for Policy Innovation on the Central Level ηc (after 100 periods in 50,000 simulation runs).
Since for d = 1 all policies are decentralised, different ηc can have no effects; therefore only one set of simulations are presented for d = 1.
Discussion of the Simulation Results and Conclusions
- 4.1
- All three hypotheses about the specific determinants and effects of laboratory federalism have been confirmed by our simulation model: Both a larger degree of decentralisation and an increase in the number of lower-level jurisdictions have a positive effect on the long-term overall performance of the policies in a federal state and simultaneously reduce the risk of low overall performance through decreasing the dispersion of possible performance values through policy error correction by mutual learning. An additional important result is that our three hypotheses still hold if we take into account some widely discussed problems of policy learning and policy transfer from other jurisdictions. Our simulations with non-imitable policies and complementary policies (with the transplant effect) demonstrate that these impediments slow down the knowledge generation effect in decentralised systems, but do not eliminate these advantages of experimentation. Therefore decentralised experimentation and mutual learning can be seen as a rather robust knowledge generation mechanism, which seems capable of producing considerably positive effects despite a number of serious imperfections. A crucial result is that this evolutionary mechanism can also produce both a larger overall performance and provide an insurance function against the persistence of erroneous policies.
- 4.2
- From the theory of federalism, it is evident that this knowledge generation effect through decentralised experimentation is only one effect among a number of other effects, leading to difficult trade off problems. In our last set of simulations we analysed two kinds of trade offs. The simulations demonstrated clearly that static cost advantages of the central level are getting outpaced in the long run by the dynamic advantages of laboratory federalism. This implies that the importance of static cost advantages should not be over-estimated in decisions about the long-term structure of a federal system. If, however, it can be demonstrated that the central level has itself superior policy innovation capabilities, which, however, is empirically very unclear, then a real long-term trade off between these dynamic advantages of the central level and the dynamic advantages of decentralised experimentation might occur, but only in the case of a large innovation capabilities differential between the central and decentral level. Due to these and other (here not considered) trade off problems through several important advantages and disadvantages of centralisation and decentralisation, we cannot derive a general policy conclusion that the most decentralised system is the best solution. What we can derive from our simulation results is that more decentralisation increases this specific knowledge generation effect through experimentation and mutual learning, and that this advantage of decentralisation is a very important effect that should always receive much attention in studies about the optimal vertical allocation of competencies and should have a considerable weight in the ensueing trade off analyses. So far, it is neglected in many discussions about centralisation or harmonisation of policies.
- 4.3
- There are several simplifying assumptions in our simulation model, where more differentiation would open up promising further research perspectives. We assumed that the parameters that determine the innovation and imitation processes, η, σ, and λ, have the same values for all policies and jurisdictions. It is much more realistic to assume these parameters as policy-specific (and perhaps even jurisdiction-specific, e.g., in the case of larger or smaller, richer or poorer lower-level jurisdictions). Another possibility would be the analysis of these processes, if the innovation and imitation phase would not be synchronised, i.e. that the jurisdictions are not at the same time in the innovation or imitation phase. In regard to non-imitable policies and different policy innovation capabilities between the central and decentral level, we already introduced some differentiation. It would be particularly interesting to analyse more deeply the impact of different parameters on the trade offs between the advantages of centralisation and decentralisation. Policy-specific differences of these parameters would lead to different sizes of the advantages of decentralised experimentation and therefore might lead to different results in regard to the balancing of the benefits of centralisation and decentralisation in the overall trade off analysis about the optimal vertical allocation of competencies. Therefore it would be possible with such a simulation model to derive optimal solutions, in which some policies are centralised and other decentralised. The results would fit in very well with the general literature on multi-level federal systems, in which often sophisticated combinations of centralisation and decentralisation seem to be preferable solutions (Kerber 2008). What would also be very interesting is what the effects of Kollman et al's (2000) differentiation between easy and difficult policy problems are in our evolutionary modelling of the benefits of parallel experimentation and mutual learning. It would be no problem to consider the different importance of policies and jurisdictions through the introduction of specific weights, or even through the use of more sophisticated ways, how to aggregate the performance of the policies in the federal state.
- 4.4
- Another interesting line of further research would refer to a deeper analysis of the specific impediments and problems of knowledge generation through parallel experimentation and mutual learning in federal states. The political science literature as well as the legal literature is heavily struggling with the chances and problems of policy transfers and legal transplants - without having offered much of a theoretical analysis. It is clear that the compatibility with other policies or legal rules is crucial for the success of policy learning from others. Our attempt to grasp this transplant effect through introducing pairs of (limitedly) complementary policies is only one rather simple way of modelling these kinds of effects. But they can be much more complicated. Those complementary effects can also exist between a group of policies or even all policies. In particular, cases can exist in which policies are complementary to other policies, which are themselves non-imitable (e.g., due to cultural reasons). What effects would such conditions have on the knowledge generation effect of decentralised experimentation? The challenge for such analyses is that from an empirical perspective we have to stay in the middle ground between assuming that policy learning is easy and no problem and the other extreme of assuming the impossibility and futility of policy learning. This also relates to another important and so far not mentioned problem, namely, to what extent different policy objectives in different jurisdictions impede policy learning from others. We would claim that a careful analysis of this problem would show that moderate differences in policy objectives are no real impediments for policy learning, but we have not considered this in our model, which implicitly assumes identical policy objectives.
- 4.5
- Another often not clearly discussed question is to what extent laboratory federalism presupposes some form of interjurisdictional competition. For example, Oates (1999) treats interjurisdictional competition and laboratory federalism as two different topics, which do not seem to be linked to each other. From an evolutionary economics perspective, the use of a Schumpeterian or Hayekian concept of competition offers an integrated theoretical approach, in which the innovation and imitation of public policies can be seen as part of interjurisdictional competition (as a discovery procedure), which generates the advantages of laboratory federalism but presupposes decentralisation (Vanberg and Kerber 1994; Kerber 2005). Similar to the approach in the models of Nelson and Winter (1982), this evolutionary competition has been modelled implicitly through the innovation and imitation processes in our simulation model. However, these competition processes have not been modelled explicitly: We did not differentiate between different types of competition among jurisdictions, i.e. between pure yardstick competition, interjurisdictional competition for firms and production factors, or regulatory competition via free choice of law. These different types can lead to a different intensity of competition, implying different incentives (competitive threat) for the innovation and imitation of policies for the jurisdictions. With different values of the parameters η, σ and λ, this different intensity of competition might be taken into account: If this competition is beneficial, a higher intensity of competition could result in faster innovation (with larger η and also σ) and faster imitation (with larger λ) leading to a more rapid increase of the overall performance of policies in a federal state. Such research would be important, because the intensity of competition among jurisdictions can itself be influenced by rules about interjurisdictional mobility and choice of law, which are therefore an essential part of the institutional structure of a federal multi-level system. This fits well into the insight that from an evolutionary economics perspective, a multi-level system of jurisdictions can be interpreted as an institutionalised system for the innovation and imitation of public policies, which facilitates the necessary coevolution of public policies with the evolving society and its perennial technological, economic and social change.
Appendix
-
(average overall performance Gt=100 and coefficient of variation cv / standard deviation [in parentheses] after 100 periods in 50,000 simulations runs)Table 1: Overall Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n d 0 0.25 0.5 0.75 1 n 4 3.72
(0.064 / 0.237)4.74
(0.048 / 0.226)5.75
(0.037 / 0.215)6.76
(0.030 / 0.204)7.77
(0.025 / 0.192)8 3.72
(0.064 / 0.237)5.22
(0.042 / 0.219)6.72
(0.030 / 0.201)8.22
(0.022 / 0.179)9.72
(0.016 / 0.156)12 3.72
(0.063 / 0.236)5.47
(0.040 / 0.217)7.23
(0.027 / 0.193)8.97
(0.019 / 0.169)10.73
(0.013 / 0.139)16 3.72
(0.063 / 0.236)5.64
(0.038 / 0.216)7.56
(0.025 / 0.191)9.48
(0.017 / 0.162)11.40
(0.011 / 0.130)20 3.72
(0.064 / 0.237)5.77
(0.037 / 0.214)7.81
(0.024 / 0.188)9.86
(0.016 / 0.159)11.90
(0.010 / 0.123)
(average overall performance Gt=100 and coefficient of variation cv / standard deviation [in parentheses] after 100 periods in 50,000 simulations runs)Table 2: Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and the Number of Non-Imitable Policies mh d = 0 d = 0.5 d = 1.0 mh 0 1 2 0 1 2 n 4 3.72
(0.064)5.75
(0.037)5.11
(0.042)4.48
(0.046)7.77
(0.025)7.14
(0.026)6.51
(0.028)8 3.72
(0.064)6.72
(0.030)5.84
(0.034)4.97
(0.039)9.72
(0.016)8.84
(0.017)7.96
(0.018)12 3.72
(0.063)7.23
(0.027)6.22
(0.031)5.22
(0.036)10.73
(0.013)9.72
(0.014)8.72
(0.015)
(average overall performance Gt=100 and coefficient of variation cv / standard deviation [in parentheses] after 100 periods in 50,000 simulations runs)Table 3: Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and the Number of Pairs of Complementary Policies (with a Transplant Effect) mk d = 0 d = 0.5 d = 1.0 mk 0 1 2 0 1 2 n 4 3.72
(0.0636)5.75
(0.0374)5.47
(0.0389)5.20
(0.0404)7.77
(0.0247)7.50
(0.0253)7.22
(0.0259)8 3.72
(0.0637)6.72
(0.0299)6.33
(0.0312)5.95
(0.0332)9.71
(0.0160)9.33
(0.0164)8.94
(0.0169)12 3.72
(0.0635)7.23
(0.0268)6.78
(0.0285)6.34
(0.0303)10.73
(0.0130)10.28
(0.0134)9.84
(0.0138)
(average overall performance Gt=100 and coefficient of variation cv / standard deviation [in parentheses] after 100 periods in 50,000 simulations runs)Table 4: Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and Different Cost Advantages of the Central Level ω ω 1.0 1.2 1.4 d 0 0.5 1.0 0 0.5 1.0 0 0.5 1.0 n 4 3.724
(0.0634)
3.724
(0.0636)5.748
(0.0375)
5.007
(0.0430)7.773
(0.0246)
7.031
(0.0273)4.186
(0.0578)
4.183
(0.0574)5.979
(0.0362)
5.239
(0.0414)7.773
(0.0247)
7.030
(0.0273)4.648
(0.0529)
4.649
(0.0525)6.212
(0.0353)
5.468
(0.0400)7.773
(0.0245)
7.033
(0.0272)8 3.724
(0.0636)
3.722
(0.0634)6.720
(0.0299)
5.693
(0.0352)9.715
(0.0160)
8.689
(0.0179)4.182
(0.0576)
4.186
(0.0575)6.950
(0.0291)
5.922
(0.0343)9.715
(0.0160)
8.687
(0.0179)4.649
(0.0527)
4.650
(0.0528)7.182
(0.0282)
6.155
(0.0332)9.715
(0.0161)
8.688
(0.0179)12 3.724
(0.0638)
3.723
(0.0636)7.223
(0.0269)
6.051
(0.0322)10.728
(0.0130)
9.553
(0.0146)4.183
(0.0576)
4.184
(0.0576)7.456
(0.0265)
6.281
(0.0314)10.727
(0.0129)
9.552
(0.0146)4.649
(0.0529)
4.650
(0.0526)7.688
(0.0260)
6.515
(0.0307)10.727
(0.0131)
9.552
(0.0146)
(average overall performance Gt=100 and coefficient of variation cv / standard deviation [in parentheses] after 100 periods in 50,000 simulations runs)Table 5: Overall Policy Performance in a Federal System in Dependence of the Degree of Decentralisation d, the Number of Lower-Level Jurisdictions n, and Different Capabilities for Policy Innovation of the Central Level ηc ηc 1.01 1.015 1.02 1.025 d 0 0.5 0 0.5 0 0.5 0 0.5 1.0 n 4 3.724
(0.0636)
3.722
(0.0636)5.749
(0.0374)
5.004
(0.0431)5.401
(0.0635)
5.402
(0.0640)6.590
(0.0422)
5.842
(0.0477)8.191
(0.0634)
8.191
(0.0638)7.986
(0.0493)
7.241
(0.0541)12.790
(0.0621)
12.792
(0.0621)10.279
(0.0565)
9.544
(0.0607)7.773
(0.0246)
7.032
(0.0273)8 3.722
(0.0634)
3.724
(0.0636)6.720
(0.0298)
5.693
(0.0352)5.404
(0.0638)
5.404
(0.0638)7.557
(0.0354)
6.532
(0.0410)8.193
(0.0638)
8.192
(0.0640)8.954
(0.0430)
7.929
(0.0486)12.786
(0.0622)
12.788
(0.0621)11.252
(0.0509)
10.223
(0.0562)9.715
(0.0160)
8.688
(0.0179)12 3.723
(0.0636)
3.725
(0.0638)7.226
(0.0270)
6.049
(0.0320)5.402
(0.0638)
5.400
(0.0640)8.065
(0.0326)
6.888
(0.0381)8.194
(0.0633)
8.191
(0.0633)9.458
(0.0403)
8.284
(0.0460)12.794
(0.0622)
12.795
(0.0620)11.757
(0.0488)
10.584
(0.0539)10.728
(0.0129)
9.553
(0.0147)
Notes
-
1In the following, we use the term policy very broadly as an abbreviation for all kinds of policy measures and changes of legal rules through a jurisdiction.
2"It is one of the happy incidents of the federal system that a single courageous state may, if its citizens choose, serve as a laboratory; and try novel social and economic experiments without risk to the rest of the country" (Louis Brandeis, Judge at the US Supreme Court 1932; quoted in Oates 1999, 1132).
3For overviews on this literature see Oates (1999), Esty and Geradin (2001), Feld and Kerber (2006), and in regard to multi-level legal systems, Kerber (2008).
4See Metcalfe's (1989) insistence on the crucial importance of the generation of variety and the modelling of technological development in Nelson and Winter (1982); for a comprehensive survey and analysis of evolutionary reasonings about the advantages of experimentation and diversity see Linge (2008).
5Contrary to another simulation model we made about processes of parallel experimentation and mutual learning in markets (Kerber and Saam 2001), in which there was only one information feedback from the market about the overall performance of an entire firm (through the profit/loss-feedback), for this analysis of laboratory federalism we consider it more appropriate to assume a direct and separate information feedback about the performance of each policy. Another assumption is that this best policy is the best for all jurisdictions, which suggests homogeneous preferences of the citizens.
6Whereas the innovation phase is the same on the central and decentral level, no imitation can take place for centralised policies. In accordance with sequential experimentation, we assume that the central level is capable to compare the outcome of the new policy with the performance of its old policy, and therefore can imitate its old superior policy (but only with the imitation rate λ) correcting for at least some of the errors that have been made.
7It can be shown that in this model the number of policies has no impact on Gt. In our earlier model (Kerber and Saam 2001) this was different due to a different information feedback mechanism.
8Please note that the number of lower-level jurisdictions in federal states can vary considerably (e.g.: Germany: 16 Bundesländer; US: 50 states; Switzerland: 26 Kantone; Canada: 10 provinces).
9The coefficient of variation is here calculated as follows: cv = σ(Gt=100) / Gt=100; σ(Gt=100) is the standard deviation of all 50,000 values of Gt=100 in all simulation runs.
10This problem differs from the also interesting (but here not analysed) question of the dispersion of the average performance values of the policies of the lower-level jurisdictions, which would address the problem of convergence within a federal system.
11This can also be confirmed by an analysis of the best and worst values of Gt=100 of all 50,000 simulation runs.
12In other simulation runs (not presented here) it can be shown that a lower λ reduces the extent of the knowledge generation effect; in fact, λ = 0 would eliminate all of these advantages.
13See in more detail and with a lot of references the empirical paper of Berkowitz et al. (2003a); also important is the matching between formal and informal rules. In the German Ordoliberal tradition this aspect of compatibility between rules has been called "Interdependenz der Ordnungen".
14The case that the jurisdiction j is the best in regard to the pair of complementary policies is taken into account in the second alternative of the following equation; it would make the term in the brackets zero, and hence no imitation takes place.
References
-
BERKOWITZ, D., Pistor, K. and Richard, J. F. (2003a). The Transplant Effect. American Journal of Comparative Law, 51, 163-203. [doi:10.2307/3649143]
BERKOWITZ, D,. Pistor, K. and Richard, J. F. (2003b). Economic Development, Legality, and the Transplant Effect. European Econ Rev, 47, 165-195. [doi:10.1016/S0014-2921(01)00196-9]
BORRÁS, S., Jacobsson, K. (2004). The Open Method of Co-ordination and New Governance Patterns in the EU. J European Public Policy 11, 185-202. [doi:10.1080/1350176042000194395]
CHANG, M. H, Harrington, J. Jr. (1998). Organizational Structure and Firm Innovation in a Retail Chain. Computational and Mathematical Organizational Theory, 3, 267-288. [doi:10.1023/A:1009657511505]
DOLOWITZ, D., Marsh, D. (2000). Learning from Abroad: the Role of Policy Transfer in Contemporary Policy Making. Gov 13, 1-24. [doi:10.1111/0952-1895.00120]
ELAZAR, D., (1987). Exploring Federalism. University of Alabama Press, Tuscaloosa.
ESTY, D. C., & D. Geradin (Eds.) (2001). Regulatory Competition and Economic Integration, Comparative Perspectives. Oxford: Oxford University Press.
FELD, L., Schnellenbach, J. (2004). Begünstigt fiskalischer Wettbewerb die Politikinnovation und -diffusion? Theoretische Anmerkungen und erste Befunde aus Fallstudien. In: C. A. Schaltegger, & D. Schaltegger (Eds.), Perspektiven der Schweizer Wirtschaftspolitik (pp 259-277). Zürich.
FELD, L., Kerber,W. (2006). Mehr-Ebenen-Jurisdiktionssysteme: Zur variablen Architektur von Integration. In: U. Vollmer (Ed.), Ökonomische und politische Grenzen von Wirtschaftsräumen (pp 109-146), Berlin: Duncker & Humblodt.
HAYEK, F. A. von (1978). Competition as a Discovery Procedure. In: F. A. von Hayek, Studies in Philosophy, Politics and Economics (pp 66-81). Chicago.
KERBER, W. (2005). Applying Evolutionary Economics to Economic Policy: the Example of Competitive Federalism. In: K. Dopfer (Ed.). Economics, Evolution and the State: The Governance of Complexity (pp 296-324), Cheltenham: Edward Elgar. [doi:10.4337/9781845428020.00021]
KERBER, W. (2008). European System of Private Laws: An Economic Perspective. In: F. Cafaggi F, H. Muir Watt (Eds,). The Making of European Private Law (pp 64-97), Cheltenham: Edward Elgar.
KERBER, W., Eckardt, M. (2007). Policy Learning in Europe: The "Open Method of Coordination" and Laboratory Federalism. J European Public Policy, 14, 229-249. [doi:10.1080/13501760601122480]
KERBER, W., Saam, N. (2001). Competition as a Test of Hypotheses: Simulation of Knowledge-generating Market Processes. Journal of Artificial Societies and Social Simulation (JASSS) 4(3), 2 < https://www.jasss.org/4/3/2.html>
KOLLMAN, K., Miller, J. H., Page, S.E. (2000). Decentralization and the Search for Policy Solutions. The J Law, Econ, & Organization, 16, 102-128. [doi:10.1093/jleo/16.1.102]
LINGE, G. (2008). Competition Policy, Innovation, and Diversity, Frankfurt a.M.: Lang.
METCALFE, J. S. (1989). Evolution and Economic Change. In: A. Silberston (Ed.), Technology and Economic Progress (pp 544-585), Basingstoke: MacMillan.
MOUSOURAKIS, G. (2010). Transplanting Legal Models across Culturally Diverse Societies: A Comparative Law Perspective. Osaka University Law Review, 57, 87-106.
OATES, W. E. (1999). An Essay on Fiscal Federalism. J Econ Literature, 37, 1120-1149. [doi:10.1257/jel.37.3.1120]
OGUS, A. (1999). Competition Between National Legal Systems: A Contribution of Economic Analysis to Comparative Law. International and Comparative Law Quarterly, 48, 405-418. [doi:10.1017/s0020589300063259]
NELSON, R. R., Winter, S. G. (1982). An Evolutionary Theory of Economic Change. Cambridge: Belknap Press.
RADAELLI, C. M. (2003). The Open Method of Coordination: A New Governance Architecture for the European Union. Swedish Institute for European Policy Studies, Rapport Nr 1.
ROGERS, E., (1995). Diffusion of Innovations, 4th Edn. New York: Free Press.
ROSE-ACKERMAN, S. (1980). Risk Taking and Reelection: Does Federalism Promote Innovation? J Leg Stud, 9, 593-616. [doi:10.1086/467654]
SCHNELLENBACH, J. (2008). Rational Ignorance is Not Bliss: What Do Ignorant Voters Learn from Decentralized Policy Experiments? Jahrbücher für Nationalökonomie und Statistik / J Econ and Statistics, 228, 372-393.
STRUMPF, K. S. (2002). Does Fiscal Decentralization Increase Policy Innovation? J Public Econ Theory, 4, 207-241. [doi:10.1111/1467-9779.00096]
VAN DEN BERGH, R. J. (2000). Towards an Institutional Legal Framework for Regulatory Competition in Europe. Kyklos, 53, 435-466. [doi:10.1111/1467-6435.00129]
VANBERG, V, Kerber, W. (1994). Institutional Competition Among Jurisdictions: An Evolutionary Approach. Const Political Econ, 5, 193-219. [doi:10.1007/BF02393147]