
 Abstract
Abstract
- This paper investigates the relevance of reputation to improve the explorative capabilities of agents in uncertain environments. We have presented a laboratory experiment where sixty-four subjects were asked to take iterated economic investment decisions. An agent-based model based on their behavioural patterns replicated the experiment exactly. Exploring this experimentally grounded model, we studied the effects of various reputational mechanisms on explorative capabilities at a systemic level. The results showed that reputation mechanisms increase the agents' capability for coping with uncertain environments more than individualistic atomistic exploration strategies, although the former does entail a certain amount of false information inside the system.
- Keywords:
- Reputation, Trustworthiness, Laboratory Experiment, Agent-Based Model, Exploration Vs. Exploitation
Introduction
- 1.1
- In real life, agents do not decide what to do simply by relying on their computational capabilities as they often communicate with qualified people and are influenced by information received by third parties. This happens, for instance, when private estate owners look for competent builders to restore property or when entrepreneurs try to sort out trustworthy partners to sub-contract critical production. This is a well-known situation in markets characterised by uncertainty, information asymmetries and ambiguity. In such situations, the quality of goods exchanged is difficult to evaluate and guarantee, moral hazard among the parties involved in a transaction can take place and market failures can easily ensue (e.g., Akerlof 1970; Williamson 1979).
- 1.2
- In these cases, information can help reduce the gap between what people know and what people should know and allow agents to risk interacting with unknown partners. The intriguing issue is that information, especially when concerned with 'hot' issues, is often kept secret or distorted by agents for their own profit. This happens because information is a relevant asset and can be negotiated, exchanged or protected (Burt 2005). Therefore, the challenge for agents is to discriminate between cheaters and trustworthy informers, so as to assess the reliability of the information received.
- 1.3
- The consequence of this situation is that people are likely to be much more sensitive to gossip, reputation and other social information sources (Conte and Paolucci 2002). This has been confirmed by a large amount of recent experimental evidence (e.g., Milinski, Semmann and Krambeck 2002a, 2002b; Milinski and Rockenbach 2007; Sommerfeld et al. 2007, 2008;Corten and Cook 2008; Piazza and Bering 2008; Barrera and Buskens 2009; Boero et al. 2009a, 2009b). This evidence has emphasized the social dimension of economic activity (Granovetter 1974; Raub and Weesie 1990; e.g., the case of financial markets in Callon 1998; Beunza and Stark 2003; Knorr Cetina and Preda 2004; Burt 2005). Interestingly, the relevance of real social contexts where economic activity takes place and information that circulates there, has also been investigated in some recent economic studies (e.g., Durlauf and Young-Peyton 2001; Gui and Sugden 2005).
- 1.4
- Along these lines, this paper investigates how reputation and social information can affect, at the micro level, the performance of economic agents in uncertain environments and, at the macro level, the exploration capability of the system as a whole. In particular, we focused on agents' capability of detecting reliable information sources while dealing with risky investment and exploration processes. We therefore compared social systems where agents are atomized entities that rely solely on their individual experience and systems where agents can rely on reputation mechanisms.
- 1.5
- The method suggested in this paper is a combination of lab experiments and agent-based models (from now, ABM). This combination has mutual advantages. Lab experiments are a powerful means to obtain well grounded information on the micro-foundations of complex social outcomes that facilitate cumulative scientific progress more than other standard qualitative or quantitative methods (Fehr and Gintis 2007; Boero et al. 2009b). This is because, in lab experiments: (a) individuals are subjected to incentives, (b) they interact according to rules of the game that are clearly defined and easily understandable, (c) what is being observed is the concrete behaviour of individuals and not a self-representation by the subject him/herself (as during an interview), (d) the presence of the observer does not affect the behaviour of individuals (unlike a field observation), (e) it is possible to manipulate certain theoretically crucial factors (e.g., incentives, rules of the game, interactions) and verify their consequences at a micro and macro level, and (f) experimental conditions and results can be easily (also inter-subjectively) replicated, giving rise to cumulativeness (e.g., Selten 1998).
- 1.6
- For these reasons, the lab can offer sound, clean and informative data on agents' behaviour which are pivotal for evidence-based models. On the other hand, agent-based modelling complements the lab since it allows to explore complex interaction structures and long time evolution which is impossible to investigate in the lab. Agent-based models can both allow for macro-level implication analyses of experimental evidence and provide new interpretations for the lab. In our view, there is a mutual cross-fertilization that is good for social simulation (e.g., Boero and Squazzoni 2005; Janssen and Ostrom 2006).
- 1.7
- Therefore, our first step was to design a lab experiment with robust data on human behaviour in a controlled decision setting (Boero and Squazzoni 2005). To capture the widest possible range of individual decisions in uncertain environments, we created an ad hoc experiment similar to an external observation of controlled human decisions. Unlike game theory experiments, where experiments are designed to closely follow a standard theory which predicts how agents behave, our experiment was explicitly designed to trace the highest heterogeneity and variety of participant behaviour. As a consequence, it did not try to understand the impact of treatment of a particular variable, nor to analyse the systemic consequence of the treatment itself, but rather to identify bottom-up human behaviour embedded in an uncertain environment. The second step was to analyse behavioural patterns in the laboratory. The third step was to design an agent-based model to validate our experimental patterns, by re-running the experiment and replicating the behavioural patterns. The assumption was that, if we were able to replicate the experimental results exactly, this would mean that the abstraction imposed on the experimental data had no relevant information loss. The following step was to design an experimental evidence-based model to introduce interaction among agents, pass from a micro to macro level, and explore the impact of certain relevant simulation parameters on the macro outcomes.
- 1.8
- In conclusion, we presented a cross-methodological exercise that shows how much explanatory potential can be achieved when agent-based modelling is based on experimental data. The substantive evidence was twofold: firstly, we showed that human subjects tend to exhibit a certain degree of coherence in different decision domains; secondly, we showed that reputation mechanisms allow social agents to generate more efficient exploration patterns in uncertain environments than atomistic strategies, though an amount of false information circulated within the system.
 The "Find the Best" Experiment
The "Find the Best" Experiment
- 2.1
- Sixty four subjects participated in the experiment that took place between October and November 2007 over two days in the computer laboratory of the Faculty of Economics of Brescia University, which is equipped with the experimental software z-Tree (Fischbacher 2007). Subjects were students belonging to different faculties, 38 females and 26 males, recruited through public announcements. They played 17 rounds of the FTB "Find the Best" game, where they were asked to explore an uncertain solution space.
- 2.2
- The game was organized as follows. Subjects had an initial endowment of 1000 experimental currency units (ECU) and a randomly assigned security with a given yield. The space consisted of 30 securities with an unknown yield. They were allowed to ask for a new security each round. The order of the securities' exploration was a fixed sequence. The game ended after 17 rounds, but subjects knew only that it was supposed to end with a probability = 0.1 on each round. In each round, subjects knew only the securities discovered in the previous rounds. The search for new securities was a risky investment and subjects bore an exploration cost. The expected final profit was dependent on the security yields discovered by the subjects.
- 2.3
- Subjects were fictitiously paired with three players in groups of four (one subject + three players). Each subject supposedly repeatedly interacted each round with one of the other three players, called players A, B and C, i.e., automata with predetermined behaviour. In each round, the subjects performed two separate decisions: (1) what to do with the securities, i.e., exploiting the already discovered security or exploring for a new security, and (2) what information on the already discovered securities to transmit to player A, B or C. Information transmission involved only the securities already discovered and could have been true or false. Subjects had the choice to transmit four kinds of information:
- They informed player A, B or C that a given security (that is the maximum-yield security discovered so far) yielded exactly what it actually yielded (true information), even if player A, B or C did not know that the security in question was the maximum yield security;
- They informed player A, B or C that a given security, namely an average yield security, yielded exactly what it actually yielded (true information);
- They informed player A, B or C that a given security (that is the maximum-yield security discovered so far) yielded less than what it actually yielded (false information);
- They informed player A, B or C that a given security, namely an average yield security they have discovered, yielded more than what it actually yielded (false information).
- 2.4
- This held for the first five rounds. The assumption of subjects sending information to player A, B or C without any consequence or feedback, was to induce them to believe that there was an interaction between players. In fact, during the subsequent 12 rounds, subjects began to receive hints on security yields from player A, B or C as informers. Informers followed three fixed behaviour:
- they communicated hints that were always true;
- their hints concerned securities that yielded less than what was communicated;
- they communicated hints that were always false because yields were randomly higher or lower than what they really were.
- 2.5
- The three players were randomly assigned to each of the three behaviour patterns for each subject. By introducing player A, B and C as group informers, we dramatically changed the possibility of exploring the security space for players. Now exploration was not only driven by random search, as in the first five rounds, but also by the availability and possibility to use hints from other people who were supposed (wrongfully or rightfully) to know more. The process of information transmission was fixed, as well as what informers respectively did each round. As shown in Table 1, whenever subjects decided to use information from informers to explore new securities, there was a fixed outcome for each round: at round 6, hints on securities were true (=1), while at round 7 they were false (=2), and so forth.
Table 1: The structure of informers' hints from round 6 to the end of the game. Round Information sent to subjects Effective Yield Informers
1= always the truth
2= always higher yields
3=higher or lower yields6 48 48 1 7 52 44 2 8 56 46 2 9 50 48 3 10 62 62 1 11 70 70 1 12 74 58 2 13 73 75 3 14 80 66 3 15 88 88 1 16 94 96 3 17 96 68 2 - 2.6
- From round 6 on, the decision of each subject was composed of three steps. The first was what to do with securities. On this, the following options were allowed:
- exploiting the maximum-yield security discovered (also available in the first five rounds);
- exploring the space by discovering a new security via a random search (also available in the first five rounds);
- exploring the space by following informers' hints (introduced since round 6).
- 2.7
- The second step was the same as in rounds 1-5 and involved information transmission from one subject to the fictitious group members, player A, B and C. The options were those mentioned above (i; ii; iii; iv). Information from one subject was addressed to the same paired player (player A, B or C) who transmitted the information to the subject in that round of the game. Finally, at the end of 17 round, the end of the game was eventually communicated to subjects.
- 2.8
- In conclusion, the "FTB game" made two challenges for subjects: maximizing their expected profit at the end of the game by exploiting or exploring the space of possibilities, and discovering/understanding when the hint of informers was true and then following it.
Experimental Results
- 3.1
- We made a two-step cluster analysis to recognize and abstract some behavioural patterns on experimental data: both concerning information transmission and decisions on securities[1]. As regards to subjects' decision on information transmission, the cluster analysis allowed us to determine three clusters called I1, 2, and 3. They were as follows:
- I1 cluster (26.6% of subjects) was represented by cooperative subjects who transmitted true information regardless of the quality of information they received from informers;
- I2 cluster (50% of subjects) was represented by conditionally cooperative subjects who tended to transmit true information but also to reciprocate false information;
- I3 cluster (23.4% of subjects) was represented by cheaters who mostly exaggerated the yields of discovered securities regardless of the quality of information they received.
- 3.2
- I1 subjects told the truth in 80% of cases by transmitting the exact yield of the best security discovered. I3 subjects told lies in 80% of cases, half the cases transmitting to others higher yields. I2 subjects told the truth in 75% of cases, transmitting the exact yield of the best security discovered or other high yields. I1 subjects told the truth only when they met trustworthy and false informers (A= 88%; C = 88%), I2 subjects told the truth almost always but were more prompt than I1 subjects to reciprocate with informers (35% false information to B and 25% false information to C informers), whereas I3 subjects transmitted false information in 76% of cases. I1 subjects told the truth by transmitting reliable information on best discovered yields (91%), while I2 and I3 subjects preferred to exaggerate the yields of discovered securities (65% for I2 and 67% for I3 players). I1 subjects, when they decided to transmit false information, preferred to report lower value yields rather than higher ones, I2 and I3 subjects told a partial truth, by transmitting some second-best rather than the best ones. This meant that, when I1 subjects decided to cheat, they did not play hard, so to be less responsible for inducing others to follow false information.
- 3.3
- The evidence found was that the behavioural clusters showed a certain coherence, a small degree of conditionality on cooperation was found in all clusters, but with significantly lower impact on I1 and I3. Furthermore, all subjects perfectly understood the game. There was no noisy or illogical behaviour, and subjects perfectly understood the different trustworthiness of players A, B, and C.
- 3.4
- The next step was to extract the behavioural patterns from the experimental evidence and translate them into a computational code that could be used to build the model and replicate the experiment (see the pseudo-codes of I1, I2 and I3 respectively in Table A.1, A.2, and A.3 in the appendix).
- 3.5
- We also applied the same cluster analysis on decision data on securities. As mentioned before, the experiment required subjects to decide between random exploration of new securities, hint-following exploration of new securities, and exploitation of already discovered securities. The results of the cluster analysis allowed us to dissect the three following clusters called A1, A2, and A3:
- A1 cluster (31.3% of subjects) included explorative subjects who took the risk of exploring informers' hints;
- A2 cluster (14.1% of subjects) included subjects who made decisions based on the reliability of informers; when the informer was trustworthy, they decided to explore but often followed a random exploration strategy; when the informer was not trustworthy, if they decided to explore the space, they did not follow the informers' hints;
- A3 cluster (54.7% of subjects) included subjects who followed the informers' hints when informers were reliable, whereas they decided to exploit already discovered securities whenever the informers' hints were not reliable.
- 3.6
- While A1 subjects preferred to explore the securities space (75% of cases), usually by following informers' hints, A2 subjects did not explore so much (55% of cases), but when they did, it was random. A3 subjects preferred not to explore space (55% of cases) either, but unlike A2 subjects, when they did, they followed informers' hints. While A1 subjects preferred to explore space regardless of informers' hints (i.e., there was no difference when hints came from player A, B, or C), A2 subjects were sensitive to informers' reliability (i.e., they followed true A hints in 72% of case, against C false hints in 44% of cases), and A3 subjects evaluated the reliability of informers in 2/3 of cases. The behaviour of A2 subjects was statistically a minority but was particularly interesting. They were sensitive to the informers' reliability, but they mostly decided to explore space through random search. They viewed hints as mere signals of potentially new yields, clearly separating the informers' reliability and their quality of information. As in the previous case, the next step was to extract behavioural patterns that were translated into a computational code used to build the model and replicate the experiment (see the pseudo-codes of I1, I2 and I3 respectively in Table A.4, A.5, and A.6 in the appendix).
- 3.7
- Subsequently, we combined the two cluster analyses so as to recognize whether subjects would have been coherent between decisions in different domains, such as information and space exploration. Our hypothesis was that such decisions, although oriented rationally to different and hypothetically separated domains, would not be perceived as being totally independent. Indeed, the subjects' distribution across I and A clusters confirmed this hypothesis.
- 3.8
- As shown in Table 2, subjects who did not follow informers' hints, suggested in their turn false information to others. The evidence is that A2 subjects, who decided to explore the space randomly, were the same I3 subjects who decided to transmit false information to others. A2-I3 subjects behaved in a particular and coherent pattern, i.e., they decided to explore the space via a random search, when they knew that other securities were available, but they did not trust informers and therefore may have decided eventually to follow a random search. When they were asked to send information, they consequently sent false information. Secondary evidence was that subjects who followed informers' hints in their turn suggested correct information to others. Table 2 shows that A1 and A3 subjects were especially distributed in I1 and I2 clusters.
Table 2: Distribution of subjects for I clusters according to A clusters belonging. A1 A2 A3 I1 40% 11% 23% I2 55% 33% 51% I3 5% 56% 26%
Validation of Behavioural Patterns
- 4.1
- The next step was to validate the patterns that we had previously identified on experimental data through an ABM[2]. All simulation parameters were settled accordingly. The model included behavioural algorithms that were aimed to reproduce the behavioural patterns described in the third section, as well as experimental conditions.
- 4.2
- We modelled 64 agents who were matched with player A, B, and C which followed the same fixed behaviour as the experiment. As in the experiment, at each run of the simulation, the agents were called on to take two decisions: action (i.e., random exploration, hint driven exploration or exploitation) and information (i.e., first best, other best, lower value or higher value). The agents' behaviour was fixed over the simulation and distributed according to data in Table 2. Since the model was based on behavioural algorithms with probabilistic features, we ran 1000 simulations of the same model and averaged the results with different random number generators.
- 4.3
- Simulation results closely replicated the lab experiment behavioural patterns. Table 3 summarises the comparison of experimental and simulated data and shows that average value and standard deviation from the subjects' population at the end of the game/simulation were quite similar.
Table 3: Comparison of experimental and simulated results. Endowment refers to the average amount of ECU cumulated over time by the subjects/agents. BestDiscovered refers to the best yield discovered by subjects/agents. FinalProfit is the profit achieved at the end of the game/simulation. Experiment Simulation Average Standard Deviation Average Standard Deviation Endowment 981.88 292.932 944.6487 275.72832 Best Discovered 88.03 11.506 85.4917 5.57511 Final Profit 1862.19 309.881 1799.5653 286.87753 - 4.4
- The validity of the replication was further corroborated when we looked at the dynamics of the main variables previously taken into account, e.g., final profit, endowment, and best security discovered. The experiment and simulation results are compared in figures 1, 2 and 3. The values and dynamics of these variables were quite similar. The slight difference may have been due to the fact that, while averaged simulation data were generated from a fixed behaviour of agents over time, experimental data were averaged from the heterogeneous behaviour of subjects spread over rounds. The Pearson correlation coefficient of the variables in question further corroborated this similarity: final profit = 0.999; Endowment = 0.971; Best discovered security = 0.999.
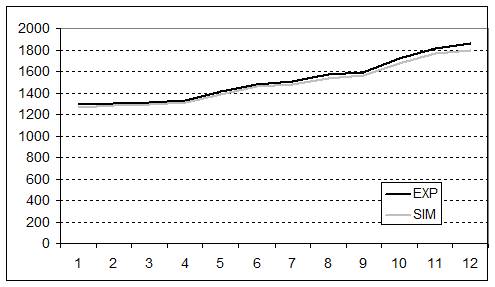
Figure 1. Dynamics of final profit over time in the experiment and in the simulation. The x axis represents the number of experiment rounds/simulation cycles (1-12 simulation cycles = 6-17 experiment rounds). The y axis represents the average final profit achieved by subjects/agents in ECU currency. 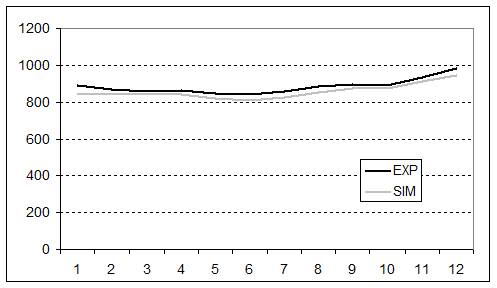
Figure 2. Dynamics of endowment over time in the experiment and in the simulation. The x axis represents the number of experiment rounds/simulation cycles (1-12 simulation cycles = 6-17 experiment rounds). The y axis represents the average endowment achieved by subjects/agents in ECU currency. 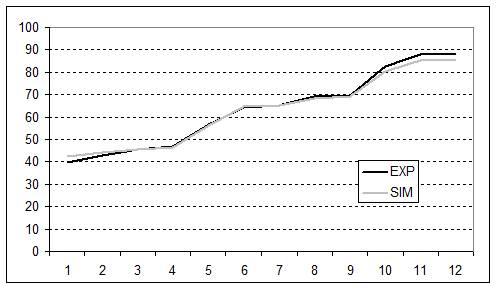
Figure 3. Dynamics of best discovered security over time in the experiment and in the simulation. The x axis represents the number of experiment rounds/simulation cycles (1-12 simulation cycles = 6-17 experiment rounds). The y axis represents the best discovered security achieved by subjects/agents in ECU currency yields. - 4.5
- In conclusion, the simulation exercise unequivocally shows that the analytic abstraction we used by identifying, recognizing and synthesizing behavioural patterns on experimental data did not mean significant information loss of what really happened during the experiment. This step gave us well controlled experimental evidence to build further simulations for analytical purposes.
The Model
- 5.1
- The following step was to build an experimental-data model to understand the impact of reputation mechanisms on the exploration capability at a system level. The model was embedded in the experimental patterns to combine theoretical analyses and robust evidence, to link micro evidence and macro consequences, and to provide scenario analyses at the system level. The agent behaviour followed the experimental data and was fixed as before (see Table 4). The model consisted of 100 agents who had to improve their profit by moving within an uncertain environment of security yields. Endowment and final profit were calculated by the same function as the experiment.
Table 4: Distribution of agents in the ABM according to experimental clusters. A1 A2 A3 Total I1 12.50% 1.56% 12.50% 26.56% I2 17.19% 4.69% 28.13% 50.00% I3 1.56% 7.81% 14.06% 23.44% Total 31.25% 14.06% 54.69% 100.00% - 5.2
- We included scarcity of resources in the model, so that agents were allowed to explore the space only if they had enough resources to do so. Unlike the experiment, we assumed variability of yields each round and not a fixed sequence. Unlike the experiment, the possibility space included one million securities of unknown yields[3]. Yields were randomly distributed across space according to a function that was squeezed toward zero, so that there were many low yield securities and fewer high yield securities[4]. Unlike the experiment, the model was based on a direct interaction among paired agents. Agents were randomly paired at the beginning of each simulation run. There were 495 interactions , so that on average, agents interacted 5 times with each other. In the model, agents had an initial endowment of 1000 ECU and the exploration cost was fixed at 8000 ECU. This was kept so high to reduce exploration frequency and to leave agents enough time to make judgements on others, as though the time scale of cognitive evaluations were more frequent than that of space exploration. Simulation runs were repeated 1000 times to average results. The simulation parameters are shown in Table 5.
Table 5: The simulation parameters. Simulation Parameters Values Agents 100 Securities 1 million Standard deviation of yields' distribution 500 Initial Endowment 1000 ECU Exploration cost 8000 ECU Number of interactions 495 - 5.3
- At this point, we introduced seven simulation settings, summarized in Table 6. While the first three allowed us to investigate macro outcomes from micro experimental evidence, the latter allowed us to analyse some simple mechanisms for reputation formation. The assumption of the first setting (called "exploit_only") was that agents simply exploited the securities randomly distributed at the beginning of the simulation. In the second one (called "explore_only"), agents explored by a random search, when they had enough resources to do so. This presupposed two extreme ideal-typical behavioural strategies, i.e., pure exploitation and random exploration, and to observe their macro consequences. These first two settings were the basis against which the other settings were compared.
- 5.4
- In the third setting (called "always listen"), we assumed that agents communicated information as in the experiment, and that they took decisions according to the experimentally based algorithms presented above. Partners were always considered as trustworthy. Agents could decide to explore new solutions by a random search or to exploit already known solutions. If they decided to follow an informer's hint, they did so regardless of who sent it. This meant that agents did not evaluate the trustworthiness of informers. They simply trusted informers whenever their hints contained some new information.
- 5.5
- In the last four settings, agents interacted by forming a personal judgment on the trustworthiness of the informers. Agents were now capable of recognising other agents they had met before, to form an opinion about their trustworthiness, and to remember it for future encounters. The difference between these four settings depended on two issues: (i) how agents evaluated unknown partners or partners for whom the amount of positive feedbacks equalled the negative ones; (ii) the possibility of sharing experience about partners' trustworthiness with others. The general rule for feedback of partners' trustworthiness was that, when agents met a partner who proved to be unreliable, they recorded the cheater in their memory. Agents constantly up-dated their memory according to a very simple rule: (i) they calculated the sum of true/false information that the agent had already transmitted; (ii) if the sum of true information was higher than the total average, this agent was considered as trustworthy.
- 5.6
- In the setting called "individual_J_pos", agents explored partners' trustworthiness without sharing any personal experience with others and with a "positive attitude" towards unknown partners. The assumption was that, whenever paired agents had never meet before, partners were considered trustworthy and the information they transmit reliable, until evidence proved the contrary. However, in the setting called "individual_J_neg", agents considered unknown partners as unreliable, and the same thing happened when positive past experiences equalled negative ones. In these settings, agents made use only of their personal past experience to evaluate a partners' trustworthiness to reduce the risk of being cheated. The last two settings, called "collective_J_pos" and "collective_J_neg", added a social reputation layer to detect trustworthiness. We introduced a memory at the system level that allowed agents to share their personal experiences: In this case, the agents' image (trustworthy/cheater) were made public, homogeneous and available for all agents. The difference of "collective_J_pos" and "collective_J_neg" was the same as the difference of "individual_J_pos" and "individual_J_neg": in the former, the attitude towards unknown partners was positive, whereas in the latter was negative.
- 5.7
- The design of these simulation settings was for a twofold analytical purpose. Firstly, we wanted to understand the impact of reputation on the exploration capability of the system. Although reputation naturally embarks false information and nourishes potential "lemons" within the system, the social sharing of individual experience could guarantee exploration capability at the system level which could be more effective and efficient than exploration/exploitation strategies of atomistic individuals. Secondly, we wanted to capture and develop our experimental evidence on the relevance of detecting trustworthiness as an uncertain environment exploration scaffold.
Table 6: The simulation settings. Simulation Settings Rules Base settings 1 "exploit_only" Pure exploitation: agents can only exploit securities randomly distributed at the beginning of the simulation 2 "explore_only" Pure exploration: agents can only explore via a random search, when they have enough resources to do so No trustworthiness evaluation 3 "listen_always" No trustworthiness evaluation: agents communicate information as observed in the experiment and trust everybody Trustworthiness evaluation at the individual level 4 "individual_J_pos" Agents explore partners' trustworthiness without sharing any personal experience with others and with a "positive attitude" towards unknown partners (presumption of partner trustworthiness) 5 "individual_J_neg" Agents explore partners' trustworthiness without sharing any personal experience with others and with a "negative attitude" towards unknown partners (presumption of partner untrustworthiness) Trustworthiness evaluation is shared at the system level (reputation) 6 "collective_J_pos" Agents know the partners' reputation (trustworthy/cheater) if any and follow a "positive attitude" towards unknown partners (presumption of partner trustworthiness) 7 "collective_J_neg" Agents know the partners' reputation (trustworthy/cheater) if any and follow a "negative attitude" towards unknown partners (presumption of partner untrustworthiness)
Simulation Results
- 6.1
- Simulation results focused on the impact of these factors on some relevant aggregate variables, such as the agents' final profit, their exploration capabilities and their resource stock. Figure 4 shows values and dynamics of the "best discovered security" and of the "agents' endowment " in the first two simulation settings (the base settings). The "best discovered security" was a proxy for the space exploration capabilities of the system. As expected, while the "exploit_only" setting implied incremental accumulation of resources but no space exploration capability, "explore_only" led to the accumulation of resources, given the agents' continuous space exploration. It is worth noting that the convex shape of the dynamics was due to the particular shape of the spatial distribution of the securities. As expected, the uncertainty of the environment results was a systemic trade-off between the expense of exploration and its necessity. Exploitation strategies allowed agents to increase their final profit at the end of the simulation, but prevented the system from finding better solutions.
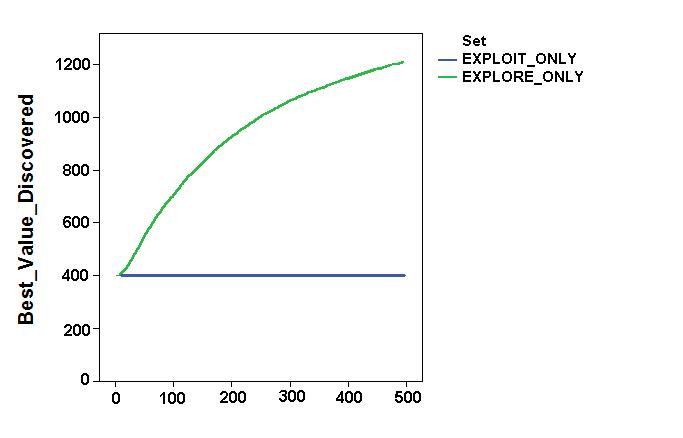
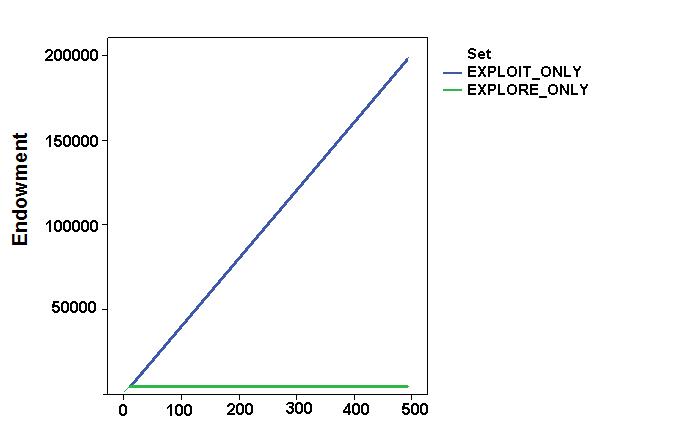
Figure 4. Dynamics of space exploration (top) and agent endowments (bottom) in the base simulation settings. - 6.2
- Figure 5 shows a comparison of values and dynamics of "final profit" in the "explore_only" and the "listen_always" settings. The evidence is that "listen_always" setting allowed agents to gain more profit than the "explore_only" setting. In this case, as in the experiment, agents' behaviour consisted of a mix of exploitation, random exploration and informer driven exploration. Although agents were not capable of evaluating partners' trustworthiness, trusting everybody (also false hints), communication and information sharing guaranteed better systemic consequences than atomistic strategies.
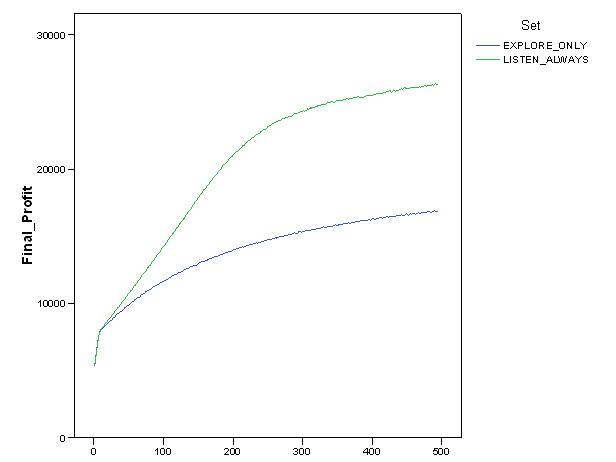
Figure 5. Dynamics of final profit of agents in "explore_only" and "listen_always" simulation settings. - 6.3
- This evidence was further corroborated by comparison with other settings. Figure 6 shows the value and dynamics of "final profit" in "explore_only", "individual_J_pos" and "collective_J_pos" settings, i.e., when more sophisticated cognitive capabilities (i.e., "individual_J_pos"), and reputation social mechanisms (i.e., "collective_J_pos" ) are added to the partner's trustworthiness' detection. Results confirmed that a reputation mechanism which allows agents to share cognitive evaluation on partners' trustworthiness guaranteed sound systemic outcomes. This is not a trivial result, in particular since there is no general law or undisputed experimental evidence that clearly demonstrates that reputation mechanisms allow agents to cope with uncertain environments better than other simple micro atomistic mechanisms. Other interesting evidence is that personal past-experience ("individual_J_pos") and shared past-experience ("collective_J_pos") generated about the same results (see Figure 6). The point is that the possibility to socially share evaluations on partners' trustworthiness does not significantly increase the efficacy of the exploration capabilities at a macro level, nor does the increased frequency of information.
- 6.4
- In "individual_J_pos", we assumed that each agent was able to evaluate other interacting agents just after completing the interaction with everybody. The process of reputation formation was therefore slow and plodding. On the contrary, in "collective_J_pos" we assumed that information on agents was available to everybody from the end of the first interaction. Data on resources and on the exploration of the search space not graphically reported here, confirmed that the positive result of final profit was due to reputation mechanisms introduced in these two last settings to guarantee exploration of the search space and accumulation of resources.
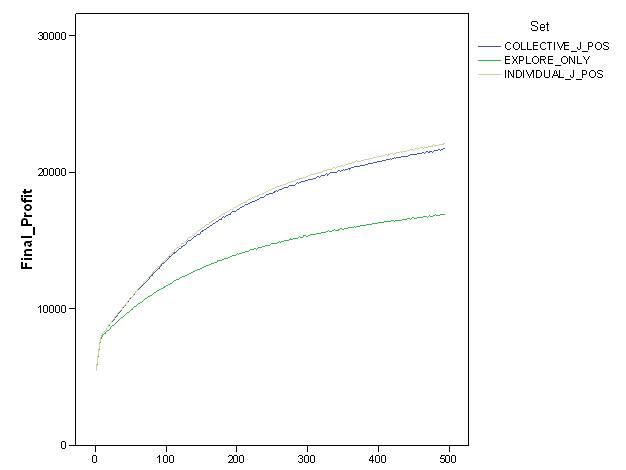
Figure 6. Dynamics of final profit of agents in "explore_only", "individual_J_pos" and "collective_J_pos" simulation settings. - 6.5
- In addition, we verified if these comparative results could be strongly influenced by the rule of "presumed innocence" which characterised the first dyadic interaction with unknown partners. Figure 7 shows the comparison of values and dynamics of "final profits" for the relevant simulation settings. The figure indicates that a "negative" attitude towards unknown partners further improved systemic outcomes[5]. A "negative" attitude allowed agents to gain even higher final profits than the idealtipic case of the "listen_always" settings introduced before. By comparing space exploration and endowment of agents in the "individual_J_pos" and "collective_J_pos" settings, Figure 8 shows that this improvement was almost definately due to increased accumulation of resources, while the attitude towards unknown partners did not significantly affect the exploration of space. The left part of the figure suggests a counter-intuitive argument. Although the difference was not statistically significant, the positive attitude seemed to guarantee a "better" exploration of the search space which is stable over time. This result contrasts with the idea that a negative approach towards unknown partners protected agents from following wrong suggestions expressed by unreliable agents.
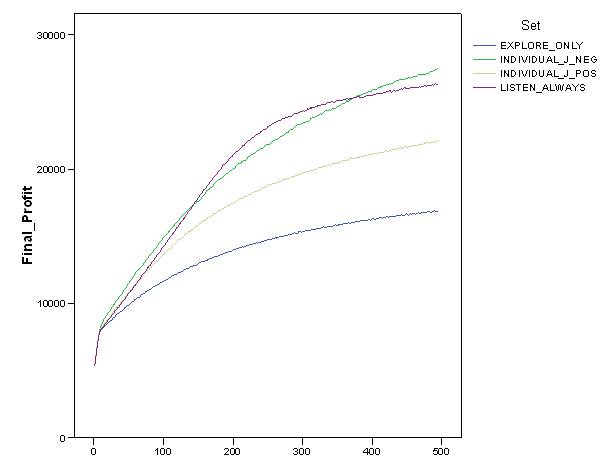
Figure 7. Dynamics of final profit of agents in "explore_only", "listen_always", "individual_J_pos" and "individual_J_neg" simulation settings. 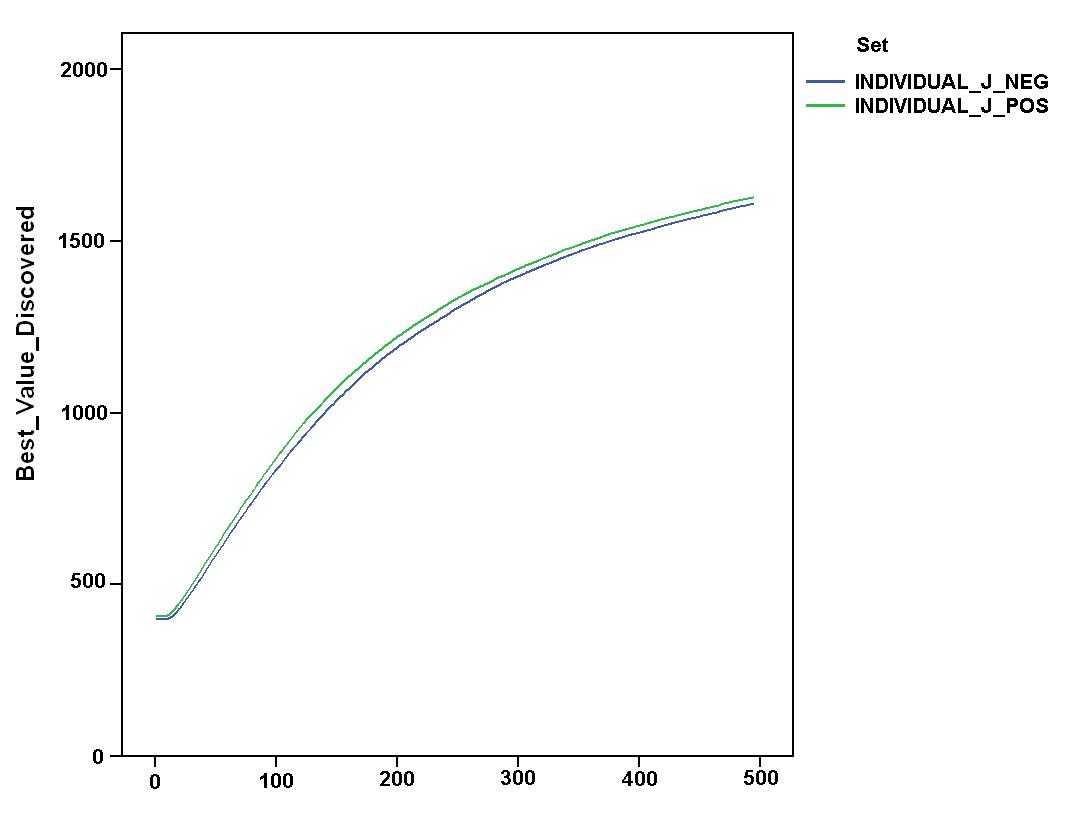
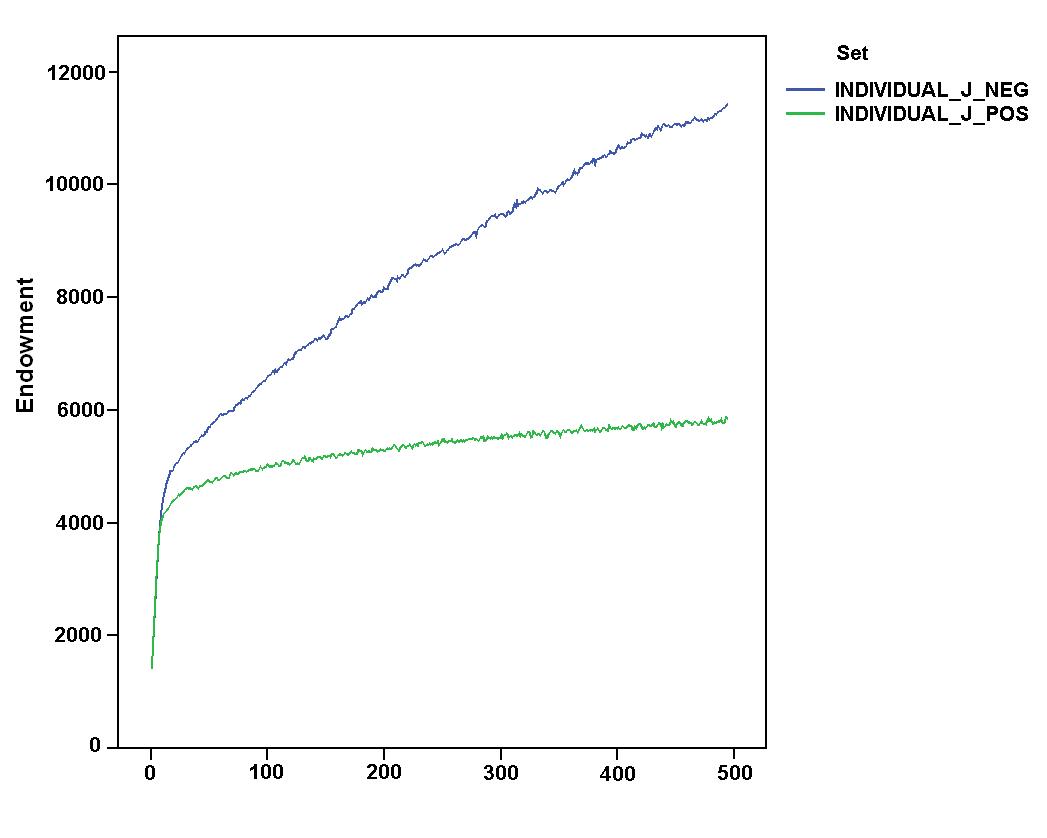
Figure 8. Dynamics of space exploration (top) and endowment of agents (bottom) in "individual_J_pos" and "individual_J_neg" simulation settings. - 6.6
- In order to check this issue, we measured the average number of wrong suggestions followed by agents over time (from now on referred to as "lemons"). As reported in Figure 9 and 10, where we compared the value and dynamics of these lemons in "individual_J_neg" and "collective_J_pos" and "neg" settings, the average number of lemons in the system was very low and tended to decrease over time, being less than 1 in 100 choices. Indeed, although there were 100 agents on each time step, not all information across the system was bad and became lemons. The fact that lemons decreased over time is, again, a not trivial outcome, This is because reputation was capable of decreasing lemons in the system.
- 6.7
- Another piece of evidence was that the number of lemons in the "individual_J_neg" setting was, in the first part of the simulation, higher than in the second. We could argue that the "negative" approach does not avoid lemons but quite the opposite, when agents have incomplete information about partners.
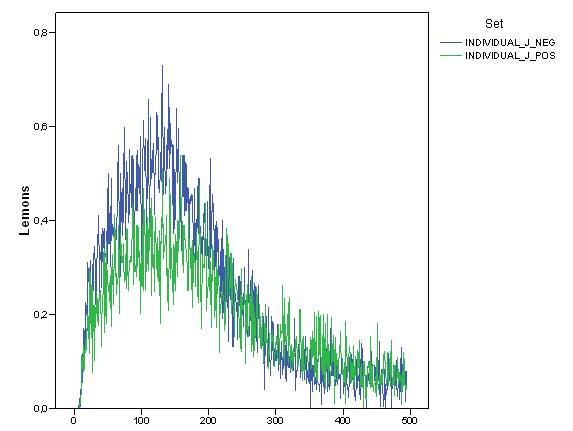
Figure 9. Dynamics of the average number of lemons in "individual_J_pos" and "individual_J_neg" simulation settings. 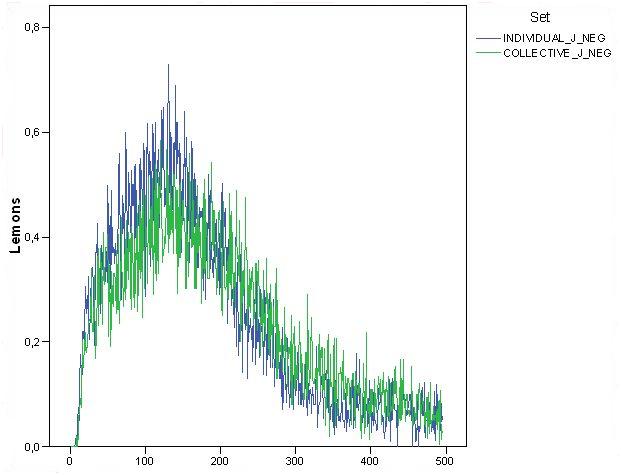
Figure 10. Dynamics of the average number of lemons in "individual_J_neg" and "collective_J_neg" simulation settings. - 6.8
- Figure 11 shows the distribution of information that informers transmitted in the "individual_J_neg" setting. This result confirms the very slight effect of sharing experience among agents: the number of lemons in the system was very similar when individual experience was not shared. Furthermore, these results shed light on some minor dynamic changes that occurred in the system when reputation was introduced. In the case of "individual-J_neg", true and false suggestions across the system significantly changed, decreasing the number of hints where a very low yield security was presented as very good (i.e., the case labelled "Higher_Low"). This was compensated in turn by more true hints about solutions which were good even if not the best ones found so far (i.e., the data series called "Other_Best").
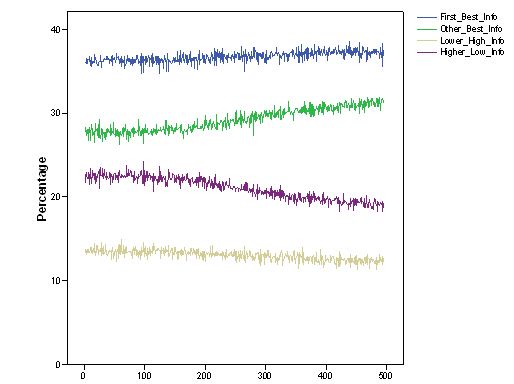
Figure 11. Dynamic distribution of the type of information transmitted in "individual_J_neg" simulation settings. - 6.9
- Finally, a relevant question is whether there was a significant relation between the economic performance of agents and the choice they made about what they transmitted to partners. Although the experimental and the simulation data introduced in the fourth section undoubtedly showed that whatever agents decided to do with information did not directly depend upon their personal wealth, we reasonably expected that some indirect relation mediated by systemic outcomes could occur. Figure 12 shows the dynamics of agents' "final profit" depended on the type of information they transmitted in the "individual_J_neg" setting. It is not surprising that at the beginning of the simulation, the average level of final profit was similar for all types of information. Only at the end of the time period did slight differences start to appear which could be interpreted as potential long run developments. The explanatory hypothesis is that communicating the best solution correlated with lower final profit, while the opposite was true when cheating was predominant (i.e., when a low yielding solution was presented as a very good one).
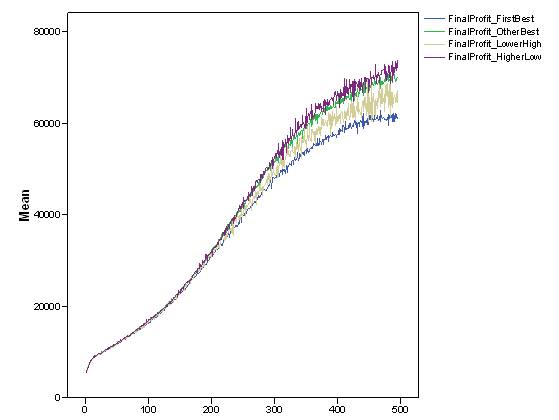
Figure 12. Dynamics of the average final profit of agents according to the type of information they have transmitted in the "individual_J_neg" simulation settings. - 6.10
- In conclusion, it is worth emphasizing that these comparative results may have been strongly influenced by the random dyadic interaction among agents. Thus, the first aim of further simulations should be to explore less rigid and exogenous interaction rules, e.g., allowing agents to exploit trustworthiness as a means to choose partners. This would be to understand whether these rules have a strong impact on the resulting dynamics. A second development could be to introduce a further simulation setting where the agent's reputation is not made public and available for all but is conditioned by third-party mediated interaction. This would add a further step to understand the relevance of reputation mechanisms in uncertain environments.
Concluding Remarks
- 7.1
- Recently, interest has been growing in reputation and trust in many disciplines (e.g., Buskens and Raub 2002; Milinski et al. 2002; Keser 2003; Kuwabara 2005; Resnick et al. 2006; Piazza and Bering 2008; Boero et al. 2009a, 2009b). Many computational models are available that investigate these issues (e.g., Conte and Paolucci 2002; Lam and Leung 2006; Luke Teacy et al. 2006; Paolucci and Sabater 2006; Hahn et al. 2007). As such, this paper is peculiar in that it introduces an experimental data-driven ABM where reputation is investigated starting from lab data on agent behaviour (e.g., Boero and Squazzoni 2005; Janssen and Ostrom 2006). Rather than following a pre-constituted theoretical framework from which generic assumptions are derived, we have studied the impact of reputation on exploration capabilities of agents in uncertain environments by observing human decisions in a lab experiment. This guaranteed an evidence-based rather than an abstracted theoretical model.
- 7.2
- Our main analytical result is that reputation mechanism allows social agents to cope with uncertain environments better than atomistic strategies. As already mentioned, this is not a trivial result, nor it is a self-explainable undisputed evidence. In particular, regarding the literature on exploration vs. exploitation in uncertain environments (e.g., March 1988, 1994; Holmqvist 2004;Sidhu, Volberda and Commandeur 2004), where social information is not seriously taken into account, our results show that the inclusion of a reputation mechanism can positively affect the exploration capabilities of agents, even if information is subjected to lemons.
- 7.3
- This could corroborate recent evidence about the relevance of reputation for the evolution of social groups (e.g., Dunbar 1996; Subiaul et al. 2008). The relevance of the interaction with unknown partners mediated by third parties for the emergence of trust and cooperation, and the enlargement of social circles which characterized the evolution of the social life have been crucial factors for improving the human capability to develop complex organizations and achieve complex goals. These factors might have aided the evolution of complex cognitive systems capable of exploiting and managing complicated sources of information, like humans (e.g., Subiaul et al. 2008).
Appendix
- 8.1
- In this appendix we reported the pseudo-code of agents' behaviour as it was modelled in our computer simulation. Naming conventions are usual: conditional statements start with an "if" instruction and execute the following code only if the condition in brackets is satisfied; if this is not the case, the code that follows the eventual instruction "else" is executed. The instruction "p" means probability, i.e., the condition in brackets is satisfied with a certain probability, and the instruction "partner trustworthy" is satisfied if the evaluation about the partner's trustworthiness is positive.
- 8.2
- In pseudo-code of information transmission decisions, agent decisions were as follows: "FIRST_BEST", i.e., communicating the true information about the maximum-yield security discovered; "OTHER_BEST", i.e., communicating the true information about a non maximum-yield security discovered; "HIGHER_LOW", i.e., communicating false information about the maximum-yield security discovered (i.e., communicating a lower yield); and "LOWER_HIGH", i.e., communicating false information (i.e., higher yields) for lower yielding discovered securities.
Table A.1: The pseudo-code of the behaviour of I1 subjects. if (p = 0.75)
FIRST_BEST;
else {
if (p = 0.75) LOWER_HIGH;
else HIGHER_LOW;
}Table A.2: The pseudo-code of the behaviour of I2 subjects. if (partner trustworthy){
if (p = 0.25) FIRST_BEST;
else OTHER_BEST;
} else {
if (p = 0.75) {
if (p = 0.25) FIRST_BEST;
else OTHER_BEST;
} else {
if (p = 0.25) LOWER_HIGH;
else HIGHER_LOW;
}
}Table A.3: The pseudo-code of the behaviour of I3 subjects. if (p = 0.25){
if (p = 0.25) FIRST_BEST;
else OTHER_BEST;
} else {
if (p = 0.25) LOWER_HIGH;
else HIGHER_LOW;
}
In the pseudo-code of decision data on securities, rules were as follows: "EXPLOITING", i.e., exploiting the maximum-yield security discovered; "EXPLORING", i.e., exploring the securities environment by a random search; and "LISTENING", i.e., exploring the securities environment by following the informers' hints.Table A4: The pseudo-code of the behaviour of A1 subjects. if (p = 0.75) {
if (p = 0.25) EXPLORING;
else LISTENING;
} else EXPLOITING;Table A5: The pseudo-code of the behaviour of A2 subjects. if (partner trustworthy){
if (P = 0.75) {
if (p = 0.75) EXPLORING;
else LISTENING;
} else EXPLOITING;
} else {
if (p = 0.5) {
if (p = 0.75) EXPLORING;
else LISTENING;
} else EXPLOITING;
}Table A6: The pseudo-code of the behaviour of A3 subjects. if (partner trustworthy){
if (p = 0.75) LISTENING;
else EXPLOITING;
} else {
if (p = 0.25) LISTENING;
else EXPLOITING;
}
Acknowledgements
- Financial support was provided by a FIRB 2003 grant (Strategic Program on Human, Economic and Social Sciences) from the Italian Ministry for the University and the Scientific Research [SOCRATE Research Project, coordinated by Rosaria Conte, Protocol: RBNE03Y338_002]. A preliminary version of this paper has been presented at the Fifth European Social Simulation Conference, University of Brescia, September 2008 and at the ICORE 2009-International Conference on Reputation. Theory and Methodology, Gargonza, Italy, March 2009. We thank two anonymous ESSA 2008 reviewers, four anonymous ICORE 2009 reviewers and two anonymous JASSS referees for very helpful remarks and suggestions. We thank Robert Coates for the linguistic revision of the text. Usual disclaimers apply.
Notes
-
1 We used both AIC and BIC as clustering criteria with SPSS statistical software. AIC stands for the Akaike Information Criterion and is a goodness-of-fit measure that is recommended to compare models with different numbers of latent variables. BIC stands for the Bayesian Information Criterion and is recommended when the sample size is large or the number of parameters in the model is small. The two-step clustering analysis works as follows: in the first step of the cluster analysis, the AIC or BIC for each number of clusters within a specified range is calculated and used to find the initial estimate for the number of clusters. In the second step, the initial estimate is refined by finding the largest increase in distance between the two closest clusters in each hierarchical clustering stage. In our case, there was no difference between AIC and BIC in the clustering outcome.
2 Our ABM was written in Java and exploited certain features of the JAS Library (jaslibrary.sourceforge.net). To access to the codes and/or have further detail, please write to the authors.
3 Since experimental evidence shows that increasing the size of stakes does not influence the subjects' behavior (e.g., Camerer and Hogarth 2003; Cameron 1999; Camerer 2003), our assumption to increase the size of securities in the simulation model to enlarge the exploration space did not invalidate our analysis.
4 The random yield draw was carried out by exploiting a random numbers generator that followed a probability distribution calculated as the modulus of a Gaussian function with mean value at 0.0 and standard deviation managed as one of the parameters of the simulation. The choice for such a shape was to model the space of yields so as to have most of them very close to 0, and just a few with a very high value.
5 To simplify the readability of the figure, the data of "collective_J_neg" simulation settings is not reported, since it confirmed the preceding results: the sharing of past experience did not have a significant impact on systemic outcomes and did not change the improvement caused by negative attitudes towards unknown partners.
References
-
AKERLOF, GA (1970) The Market for Lemons: Quality Uncertainty and the Market Mechanism. Quarterly Journal of Economics, 84, 3, 488-500 [doi:10.2307/1879431]
BARRERA, D and V Buskens, V (2009) 'Third-Party Effects on Trust in an Embedded Investment Game.' In K. Cook, C. Snijders, V. Buskens, and C. Cheshire (eds) Trust and Reputation, New York: Russell Sage: forthcoming
BEUNZA, D and D Stark (2003) The Organisation of Responsiveness: Innovation and Recovery in the Trading Rooms of Lower Manhattan. Socio-Economic Review, 1, 135-164 [doi:10.1093/soceco/1.2.135]
BOERO, R and F Squazzoni (2005) Does Empirical Embeddedness Matter? Methodological Issues on Agent-Based Models for Analytical Social Science. JASSS, 8(4)6: https://www.jasss.org/8/4/6.html
BOERO, R, G Bravo, M Castellani and F Squazzoni (2009a) Reputational Cues in Repeated Trust Games. Journal of Socio-Economics, 38, 871-877 [doi:10.1016/j.socec.2009.05.004]
BOERO, R, G Bravo, M Castellani and F Squazzoni (2009b) Pillars of Trust: An Experimental Study on Reputation and Its Effects. Sociological Research Online, 14, 5: http://www.socresonline.org.uk/14/5/5.html [doi:10.5153/sro.2042]
BURT, R (2005) Brokerage and Closure: An Introduction to Social Capital. Oxford: Oxford University Press
BUSKENS, V and W Raub (2002) Embedded Trust: Control and Learning. Advances in Group Processes, Vol. 19, 167-202 [doi:10.1016/S0882-6145(02)19007-2]
CALLON, M (Ed.) (1998) The Laws of Markets. Oxford: Blackwell Publishers
CAMERER, CF (2003) Behavioural Game Theory. Experiments in Strategic Interaction. New York/Princeton: Russell Sage Foundation/Princeton University Press
CAMERER, CF and RM Hogarth (2003) The Effect of Financial Incentives in Economics Experiments: A Review and Capital-Labor Production Framework. Journal of Risk and Uncertainty, 18, 7-42
CAMERON, LA (1999) Raising the Stakes in the Ultimatum Game: Experimental Evidence from Indonesia. Economic Inquiry, 27, 47-59 [doi:10.1111/j.1465-7295.1999.tb01415.x]
CONTE, R and M Paolucci (2002) Reputation in Artificial Societies: Social Beliefs for Social Order. Dordrecht: Kluwer Academic Publishers [doi:10.1007/978-1-4615-1159-5]
CORTEN, R and C Cook (2008) 'Cooperation and Reputation in Dynamic Networks'. In Paolucci M. (ed) Proceedings of the First International Conference on Reputation: Theory and Technology - ICORE 09, Gargonza, Italy
DUNBAR, RIM (1996) Grooming, Gossip and the Evolution of Language. Cambridge, MA: Harvard University Press
DURLAUF, SN and H Young-Peyton (Eds.) (2001) Social Dynamics. Cambridge, MA: The MIT Press
GRANOVETTER, M (1974) Getting A Job: A Study of Contacts and Careers. Harvard: Harvard University Press
GUI, B and R Sudgen (Eds.) (2005) Economics and Social Interaction. Accounting for Interpersonal Relations. Cambridge: Cambridge University Press [doi:10.1017/CBO9780511522154]
FEHR, E and H Gintis (2007) Human Motivation and Social Cooperation: Experimental and Analytical Foundations. Annual Review of Sociology, 33, 43-64 [doi:10.1146/annurev.soc.33.040406.131812]
FISCHBACHER, U (2007) z-Tree. Zurich Toolbox for Readymade Economic Experiments. Experimental Economics, 10, 171-178 [doi:10.1007/s10683-006-9159-4]
HAHN, C, B Fley, M Florian, D Spresny and K Fischer (2007) Social Reputation: A Mechanism for Flexible Self-Regulation in Multiagent Systems. JASSS 10(1)2 https://www.jasss.org/10/1/2.html.
HOLMQVIST, M (2004) Experiential Learning Processes of Exploration and Exploitation Within and Between Organizations: An Empirical Study of Product Development. Organization Science, 15, 1, 70-81 [doi:10.1287/orsc.1030.0056]
JANSSEN, M and E Ostrom (2006) Empirically Based, Agent-Based Models. Ecology and Society, 24, 33-60
KESER, C (2003) Experimental games for the design of reputation management systems. IBM Systems Journal, 42, 498-506 [doi:10.1147/sj.423.0498]
KNORR CETINA, KD and A Preda (Eds.) (2004) The Sociology of Financial Markets. Oxford: Oxford University Press
KUWABARA, K (2005) Affective Attachment in Electronic Markets: A Sociological Study of eBay. In Nee V. and Swedberg R. (eds), The Economic Sociology of Capitalism. Princeton: Princeton University Press, 268-288
LAM, KM and HF Leung (2006) A Trust/Honesty Model with Adaptive Strategy for Multiagent Semi-Competitive Environments. Autonomous Agents and Multi-Agent Systems, 12, 293-359 [doi:10.1007/s10458-005-4984-y]
LUKE TEACY, WT, J Patel, NR Jennings and M Luck (2006) TRAVOS: Trust and reputation in the context of inaccurate information sources. Autonomous Agents and Multi-Agent Systems, 12, 293-359 [doi:10.1007/s10458-006-5952-x]
MARCH, J (1988) Decisions and Organizations. Oxford: Basil Blackwell
MARCH, J (1994) A Primer on Decision Making: How Decisions Happen. New York: The Free Press
MILINSKI, M, and B Rockenbach (2007) Spying on others evolves. Science, 317, 464-4656 [doi:10.1126/science.1143918]
MILINSKI, M, D Semmann, and H-J Krambeck (2002a) Donors to charity gain both indirect reciprocity and political reputation. Proceedings of the Royal Society 269, 881-883 [doi:10.1098/rspb.2002.1964]
MILINSKI, M, D Semmann, and H-J Krambeck (2002b) Reputation Helps Solve the Tragedy of the Commons. Nature, 415, 424-426 [doi:10.1038/415424a]
PAOLUCCI, M and J Sabater (2006) Introduction to the Special Issue on Reputation in Agent Societies. JASSS, 9(1)16 https://www.jasss.org/9/1/16.html
PIAZZA, J and Bering, J M (2008) Concerns about Reputation via Gossip Promote Generous Allocations in an Economic Game. Evolution and Human Behavior, 29, 172-178 [doi:10.1016/j.evolhumbehav.2007.12.002]
RAUB, W and J Weesie (1990) Reputation and Efficiency in Social Interactions: An Example of Network Effects. The American Journal of Sociology, 96, 3, 626-654 [doi:10.1086/229574]
RESNICK, P, R Zeckhauser, J Swanson and K Lockwood (2006) The Value of Reputation on e-Bay. A Controlled Experiment. Experimental Economics, 9, 2, 79-101 [doi:10.1007/s10683-006-4309-2]
SABATER, J and C Sierra (2005) Review on Computational Trust and Reputation Models. Artificial Intelligence Review, 24, 33-60 [doi:10.1007/s10462-004-0041-5]
SELTEN, R (1998) Features of Experimentally Observed Bounded Rationality. European Economic Review, 42: 413-436 [doi:10.1016/S0014-2921(97)00148-7]
SIDHU, JS, HV Volberda and HR Commandeur (2004) Exploring Exploration Orientations and Its Determinants: Some Empirical Evidence. Journal of Management Studies, 41, 6, 913-932 [doi:10.1111/j.1467-6486.2004.00460.x]
SOMMERFELD, RD, H-J Krambeck, D Semmann, and M Milinski (2007) Gossip as an alternative for direct observation in games of indirect reciprocity. PNAS 104(44), 17435-17440 [doi:10.1073/pnas.0704598104]
SOMMERFELD, RD, H-J Krambeck and M Milinski (2008) Multiple gossip statements and their effect on reputation and trustworthiness. Proceedings of the Royal Society B. 275, 2529-2536 [doi:10.1098/rspb.2008.0762]
SUBIAUL, F, J. Vonk, S. Okamoto-Barth, J. Barth (2008) Do Chimpanzees Learn Reputation by Observation? Evidence from Direct and Indirect Experience with Generous and Selfish Agents. Animal Cognition 11(4) 611 - 623. [doi:10.1007/s10071-008-0151-6]
WILLIAMSON, OE (1979) Transaction Cost Economics: The Governance of Contractual Relations. Journal of Law and Economics, 22, 233-261. [doi:10.1086/466942]