
Emerging Artificial Societies Through Learning
Journal of Artificial Societies and Social Simulation
vol. 9, no. 2
<https://www.jasss.org/9/2/9.html>
For information about citing this article, click here
Received: 02-Sep-2005 Accepted: 10-Dec-2005 Published: 31-Mar-2006

 Abstract
Abstract| Table 1: Properties encoded in the genome of the agent | |||
| Name | Type | Value | Additional comments |
| Metabolism | real | [0,1] | Determines how how much food is converted into energy |
| OnsetTimeAdulthood | int | [15,25] | Reaching the adult age the agent becomes fertile |
| OnsetTimeElderdom | int | [55,65] | Reaching elderdom the agent loses fertility. |
| Socialness | real | [0,1] | The degree to which an agent wants to interact with other agents. |
| FollowBehaviour | real | [0,1] | The degree to which an agent wants to follow its parents |
| MaxVisionDistance | real | [0,1] | How far an agent can see. |
| InitialSpeed | real | [0,1] | Initial distance an agent can walk per time step |
| InitialStrength | real | [0,1] | Initial weight an agent can lift. |
| MaxShoutDistance | real | [0,1] | The maximal reach of an agent''s shout |
|
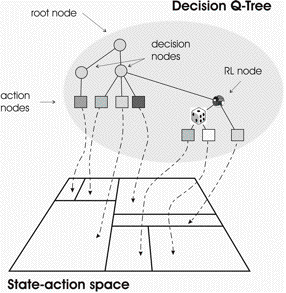
| Figure 1. DQTs are decision trees with the following features: (1) nodes can denote rules, indices of states, and actions, (2) decisions can be stochastic (denoted by the dice), (3) nodes are assumed to have values (denoted by the gray levels of the nodes). Special cases of DQTs among others are: decision trees, the action-state value tables of reinforcement learning, and Bayesian decision networks. DQTs have large compression power in state-action mapping and suit evolutionary algorithms. DQT partitions of the state-action space can be overlapping. |
|
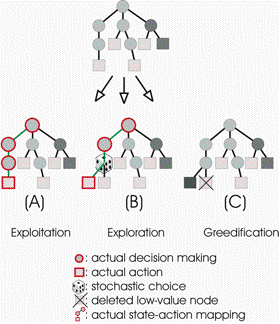
| Figure 2. (A) exploitation using DQT, (B) exploration and (C) "greedification" of a DQT. The value of each node is shown by the depth of the grey shading. |
| Table 2: An example scheme for playing a language game between a speaker and hearer. The game may take up to 5 time steps t. See the text for details. | ||
t | Speaker | Hearer |
| n | Perceive context | |
| Categorisation/DG | ||
| Target selection | ||
| Produce utterance | ||
| Update memory1 | ||
| Send message | ||
| n + 1 | Receive message | |
| Perceive context | ||
| Categorisation/DG | ||
| Interpret utterance | ||
| Update memory1 | ||
| Respond | ||
| n + 2 | Evaluate effect | |
| n + 3 | Evaluate effect | |
| n + 4 | Update memory2 | Update memory2 |
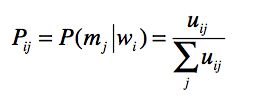 |
(1) |
When an association is used, its co-occurrence frequency uij is incremented. This update is referred to in Table 3 as 'update memory1'. The association scores σi j are calculated based on the agents' evaluation of the success of the game. If the game is a success, the association is reinforced according to Eq. (2), otherwise it is inhibited using Eq. (3).
| σi j = η σi j + 1 - η | (2) |
| σi j = η σi j | (3) |
where η is a learning parameter (typically η=0.9).
| strL(αij + (1 - σij)Pij | (4) |
This equation has the neat property that if the association score is low (i.e. the agent is not confident about the association's effectiveness), the influence of the a posterior probability is large, and when the association score is high, the influence of the a posterior probability is low. (For a case study using this combined model, consult Vogt & Divina 2005).
2This motivation does not have to be 'hard-coded' or built in; it too can be evolved, since agents that have no 'motivation' to survive are also likely to fail to reproduce. Hence there will be evolutionary pressure in favour of agents that behave in ways that make them appear to be motivated for survival.
3We call it the 'NewTies' agent to distinguish this agent design from others that may be introduced into the environment. As noted later, the intention is to make the environment open so that other agent designs may be trialled.
BANZHAF, W., Nordin, P., Keller, R.E., & Francone, F.D. (1998). Genetic Programming: An Introduction. San Francisco: Morgan Kaufmann.
BLOOM, P. (2000). How children learn the meanings of words. Cambridge, MA: MIT Press.
CANGELOSI, A. and D. Parisi (2002). Simulating the evolution of language. London, Springer.
CHOUINARD, M. M., & Clark, E. V. (2003). Adult reformulations of child errors as negative evidence. Journal of Child Language, 30(3), 637--669.
CLARK, E. V. (1993). The lexicon in acquisition: Cambridge University Press.
CLARK, H. H. (1996). Using Language: Cambridge University Press.
DABEK, F, Brunskill, E, Kaashoek, F, Karger, D, Morris, R, Stoica, I, et al. (2001). Building peer-to-peer systems with CHORD, a distributed lookup service. Paper presented at the Proceedings of the 8th Workshop on Hot Topics in Operating Systems (HotOS VIII).
GILBERT, Nigel. (2005). Agent-based social simulation: dealing with complexity. from http://www.complexityscience.org/NoE/ABSS-dealing%20with%20complexity-1-1.pdf
GILBERT, Nigel, & Troitzsch, Klaus G. (2005). Simulation for the social scientist (Second ed.). Milton Keynes: Open University Press.
GONG, T., Ke, J., Minett, J. W., & Wang, W. S. Y. (2004). A computational framework to simulate the co-evolution of language and social structure. Paper presented at the Artificial Life IX Proceedings of the Ninth International Conference on the Simulation and Synthesis of Living Systems.
GOPNIK, A., & Meltzoff, A. N. (1997). Words, Thoughts, and Theories (Learning, Development, and Conceptual Change). Cambridge, MA.: MIT Press.
HAYKIN, S. (1999). Neural networks: {A} comprehensive foundation (2nd edition ed.). Upper Saddle River, NJ: Prentice-Hall.
HOLLAND, John, H., Booker, Lashon, B., Colombetti, Marco, Dorigo, Marco, Goldberg, David, E., Forrest, Stephanie, et al. (2000). What Is a Learning Classifier System? Springer-Verlag.
HUTCHINS, E, & Hazlehurst, B. (1995). How to invent a lexicon: the development of shared symbols in interaction. In G. N. Gilbert & R. Conte (Eds.), Artificial Societies. London: UCL Press.
KING, Leslie J. (1985). Central Place Theory: Sage.
KOVACS, Tim. (2002). Two Views of Classifier Systems. Paper presented at the Fourth International Workshop on Learning Classifier Systems - IWLCS-2001, San Francisco, California, USA.
MALINOWSKI, B. (1922 [1978]). Argonauts of the Western Pacific. London: Routledge and Kegan Paul.
MARKMAN, E. (1989). Categorization and naming in children. Cambridge, Ma.: MIT Press.
PREMACK, D., & Woodruff, G. (1978). Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4), 515--526.
QUINE, W. V. O. (1960). Word and object: Cambridge University Press.
SMITH, Andrew, D. M. (2003). Intelligent Meaning Creation in A Clumpy World Helps Communication. Artificial Life, 9(2), 559--574.
SMITH, Andrew. D. M. (2005). Mutual Exclusivity: Communicative Success Despite Conceptual Divergence. Paper presented at the Language Origins: perspectives on evolution, Oxford.
SMITH, Bruce. (1995). The Emergence of Agriculture. New York: Scientific American Library.
STEELS, L. (1996). Emergent adaptive lexicons. Paper presented at the From Animals to Animats 4, Cambridge, MA.
STEELS, L. (1997). Language Learning and Language Contact. Paper presented at the Workshop Notes of the ECML/MLnet Familiarization Workshop on Empirical Learning of Natural Language Processing Tasks, Prague.
STEELS, L., & Kaplan, F. (1999). Situated Grounded Word Semantics. Paper presented at the Proceedings of IJCAI 99.
SUTTON, R., & Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge: MIT Press.
TOMASELLO, M. (1999). The cultural origins of human cognition: Harvard University Press.
VOGT, P. (2003). Anchoring of semiotic symbols. Robotics and Autonomous Systems, 43(2), 109--120.
VOGT, P. (2005). The emergence of compositional structures in perceptually grounded language games. Artificial Intelligence167(1-2):206 - 242.
VOGT, P., & Divina, F. (2005). Language evolution in large populations of autonomous agents: issues in scaling. Paper presented at the Proceedings of AISB 2005, Hatfield, UK.
VOGT, P., & Coumans, H. (2003). Investigating social interaction strategies for bootstrapping lexicon development. Journal for Artificial Societies and Social Simulation, 6(1) https://www.jasss.org/6/1/4.html.
VOGT, P., & Smith, A. D. M. (2005). Learning colour words is slow: a cross-situational learning account. Behavioral and Brain Sciences 28(4): 509-510.
WOOLDRIDGE, M., & Jennings, N. R. (1995). Intelligent Agents: Theory and Practice. In Knowledge Engineering Review, 10(2), 1-62.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2006]