
Monojit Choudhury, Anupam Basu and Sudeshna Sarkar (2006)
Multi-Agent Simulation of Emergence of Schwa Deletion Pattern in Hindi
Journal of Artificial Societies and Social Simulation
vol. 9, no. 2
<https://www.jasss.org/9/2/2.html>
For information about citing this article, click here
Received: 05-Aug-2005 Accepted: 11-Dec-2005 Published: 31-Mar-2006

 Abstract
Abstract
|
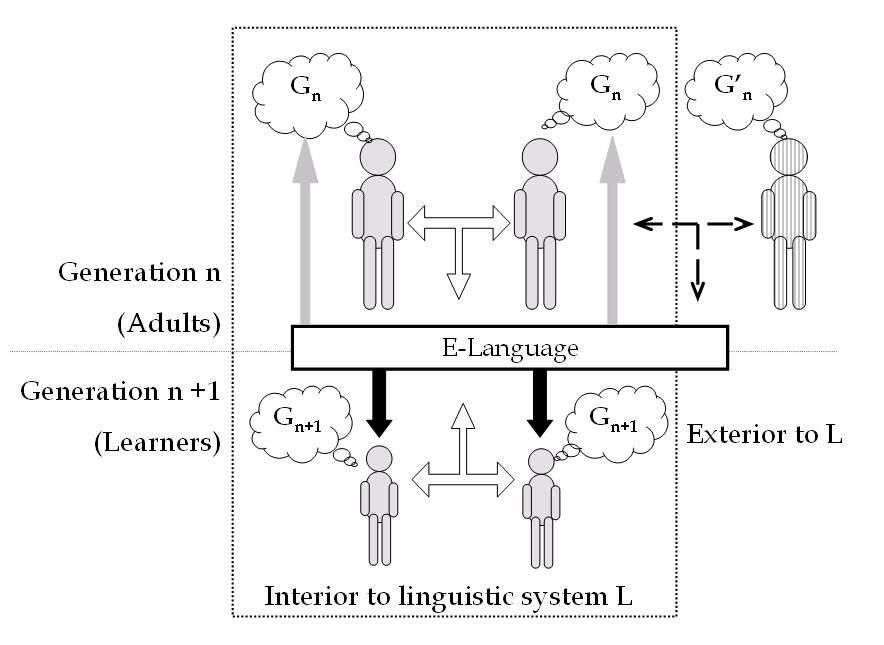
| Figure 1. Language transmission in an open linguistic system. One or combination of several factors (shown by arrows in the diagram) can be responsible for a language change - the case where the grammar Gn+1 is different from Gn. |
|
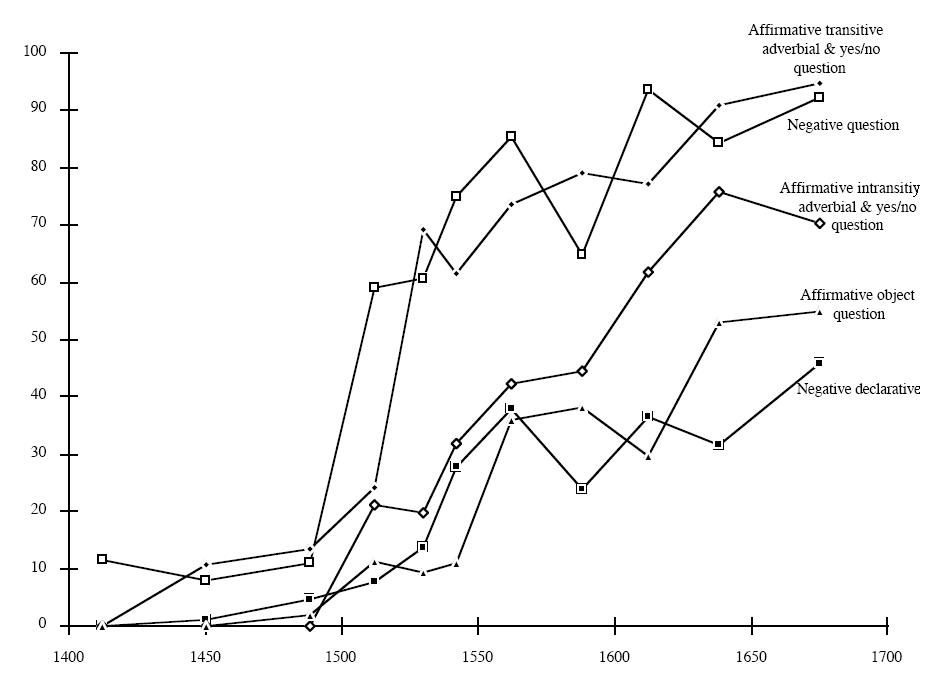
| Figure 2. The rise of periphrastic do. The horizontal axis denotes the date (in year) and the vertical axis denotes the percentage of usage of the new variant found in historical data. (Adapted from Ellegard (1953) as cited in Kroch (1989)) |
Some other observations on the course of language change include the gradualness both across the population and the lexicon (in case of sound changes), directionality etc (see Bhat 2001 for an overview).
| α → Φ / VCC? __ CV |
|
Condition: Deletion should not violate the phonotactic constraints. Convention: The rule applies from left to right. |
| Table 1: Schwa deletion patterns in Hindi and the application of Ohala's rules. The ITRANS encoding has been used. '-' represents syllable breaks | ||
| Written form | Possibilities after Ohala's rule | Possibilities after application of the convention |
| bachapana | bach-pan, ba-chap-na | bach-pan |
| bachapanA | ba-chap-nA, bach-pa-nA | bach-pa-nA |
| sundarI | sun-drI | sun-drI |
|
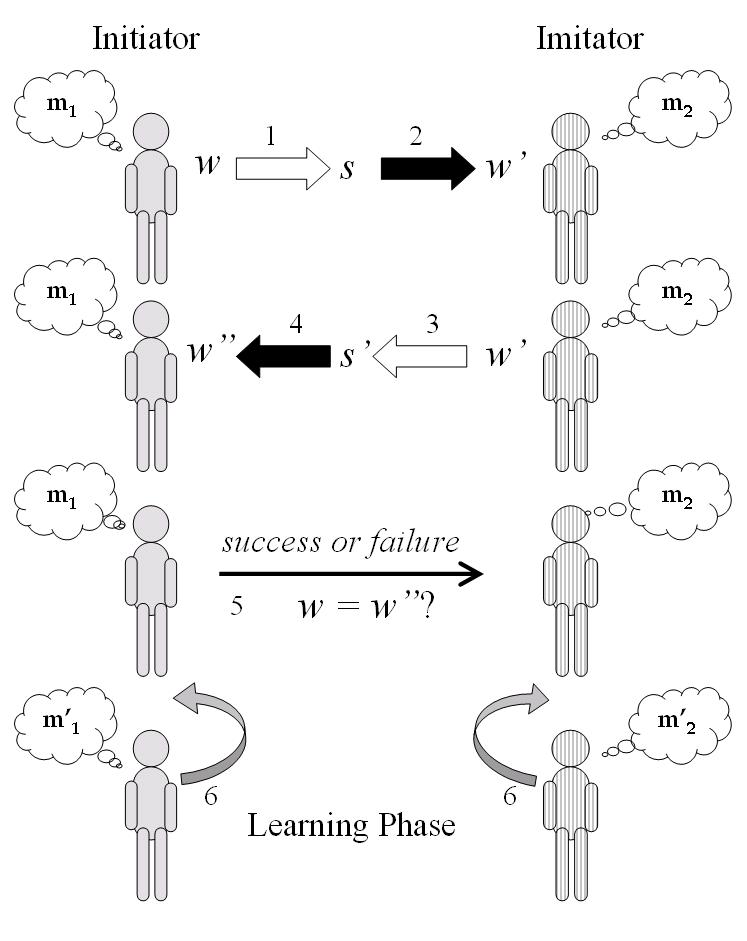
| Figure 3. Schematic representation of an imitation game. The arrows represent events, which are numbered according to their occurrence and oriented according to the direction of information flow. The thick white and black arrows represent the process of articulation and perception respectively. The thin black arrow represents extra-linguistic communication and the gray arrows represent learning. |
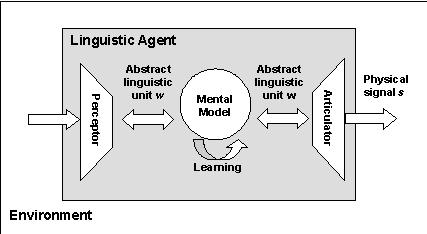
|
| Figure 4. The architecture of a linguistic agent |
M: Mental model of the agent (a set of mental states)
A: The articulator model (or actuator)
P: The perceptor model (or sensor)
L: M → M is the learning algorithm that maps a mental state to another mental state
ri(hara) = <h,1> <a,2> <r,1.5> <a,0> ,
ri(mara) = <m,1> <a,2> <r,1.5> <a,2> ,
ri(amara) = <a,2> <m,1> <a,1.3> <r,1.5> <a,0.5> ,
ri(krama) = <k,0.5> <r,1.5> <a,1.6> <m,0.5> <a,0>
This particular state can also be represented as ri(W) or simply Ri. We can have another mental state mj ( also rj(W) or Rj) that looks like
rj(hara) = <h,1> <a,2> <r,1.5> <a,0> ,
rj(mara) = <m,1> <a,2> <r,1.5> <a,0> ,
rj(amara) = <a,2> <m,1> <a,1.3> <r,1.5> <a,0.5> ,
rj(krama) = <k,0.5> <r,1.5> <a,1.6> <m,0.5> <a,0>
An agent can reach mental state mi from a mental state mj by learning to delete the schwa at the end of the word mara, thus reducing the duration of the word final a from 2 (long) to 0 (complete deletion). Note that as we allow the durations to assume any arbitrary value between 0 and 2, it leads to the possibility of an infinite number of mental states. However, by restricting the durations to a finite set of values (say 0 for deleted, 1 for short and 2 for long), we can restrict the number of mental models to a finite value (for this example, with 3 possible values for duration we have 319 possible mental states that comprise M).
Assumption 1: The signal is represented as a sequence of phonemes and phoneme-to-phoneme transitions.
Justification: Analysis of speech signals show that there are steady states corresponding to the phonemes (especially the vowels and other sonorants), and between two phonemes there is a significant portion of the signal that represents phoneme-to-phoneme transition. This is a result of co-articulation and provides important cues for perception. Several concatenative speech synthesis systems utilize this fact and use diphones as the basic unit of synthesis (see Dutoit 1997 for an overview of such systems). This has been chosen as the representation scheme, because considering our objective, which is phone deletion, lower-level representations (for example formant-based as used in de Boer 2001) make the system computationally intensive without providing us any extra representational power. On the other hand, a syllable-level representation, which can provide a useful abstraction, calls for a definition of syllabification — a quite controversial concept (see Jusczyk and Luce 2002 for a general overview on issues related to human perception).
Assumption 2: Articulatory model has an inherent bias for schwa deletion, but not deletion of other vowels or consonants.
Justification: During casual speech, several articulatory phenomena are observed including vowel and consonant deletion, epenthesis, metathesis, assimilation and dissimilation. We refer to these as articulatory errors because such effects are unintentional, involuntary, and above all lead to the deviation from the correct pronunciation[4]. Nevertheless, the objective of the current work is to investigate the schwa deletion pattern and not general vowel deletion, or other types of sound changes. Incorporating these extra factors can further complicate the model leading to masking and interference of different factors. Moreover, we do not make any claims here regarding the emergence of the schwa deletion; we only claim that the model explains the specific pattern observed in Hindi schwa deletion. The investigation of the emergence of schwa deletion and other phonological phenomena is beyond the scope of the current work.
Assumption 3: Duration of consonants is 0.
Justification: Vowels and consonants can be placed on the sonority hierarchy (Clements 1990), which reflects their ability to form syllables and the possibility to be pronounced for a prolonged period. Thus, vowels placed at the top of the sonority scale almost always form the syllable nucleus and have a longer duration, whereas stops placed at the lower end of the scale can never form syllable nucleus and can never be lengthened. Nonetheless, several consonants, especially the sonorants can be lengthened as well as used as the syllable nucleus. Thus, the assumption that all the consonants have 0 duration is clearly incorrect. However, let us try to understand the objective of the current work. We want to model the deletion of the schwas. When a schwa gets deleted, the consonants which were part of the syllable have now to be placed within other syllables. For example, if both the schwas of the word ha-ra (- indicates syllable boundary) are deleted the resulting word hr is not pronounceable, whereas deletion of only one of the schwas gives rise to the patterns hra or har both of which are well formed. If we assume that the consonants have durations of their own, and can be perceived even without the transitions, in our model we have no way to claim that hr is unpronounceable. To the contrary, the assumption that consonants have no duration allows us to model the syllables around the vowels, even though there is no explicit reference to the syllables. In fact by assigning the duration of the transitions on the basis of the neighboring vowel duration, we capture the fact that a syllable, including its onset and rime, is perceptible only if it is of sufficiently large duration (see below for details on the perceptor model).
Assumption 4: The duration of the schwas are reduced randomly, without considering the context.
Justification: The inherent bias towards fast speech is modeled through the tendency to reduce the duration of the schwas, but the articulator model does not accomplish this randomly. The duration is reduced by a fixed and predetermined amount d (which is an input to the simulation experiments) and a probability pr (also an input). The randomness is with respect to the context in which the schwa is deleted. Stating it in another way, all the schwas in a word are equally likely to be deleted. This is a desired feature because we want to examine the emergence of the schwa deletion context and therefore, should refrain from providing any initial bias in the system towards deletion in certain contexts and not in others. We shall see that even without any initial context specific bias, the context for schwa deletion clearly emerges in the simulation experiments.
| Table 2: Computation of perception probabilities. perc denote the probability of perceiving a phoneme from a given unit | |||||||
| Phoneme p | Left transition | Realization | Right transition | Prob (p is perceived) | |||
| perc | ~perc | perc | ~perc | perc | ~perc | ||
| a | 0 | 1 | 0.9 | 0.1 | 0.9 | 0.1 | 1 - (1×0.1×0.1) = 0.99 |
| m | 0.9 | 0.1 | 0 | 1 | 0.65 | 0.35 | 1 - (0.1×1×0.35) = 0.96 |
| a | 0.65 | 0.35 | 0.65 | 0.35 | 0.65 | 0.35 | 1 - (0.35)<sup>3</sup> = 0.96 |
| r | 0.65 | 0.35 | 0 | 1 | 0.15 | 0.85 | 1 - (0.35×1×0.85) = 0.7 |
| a | 0.15 | 0.85 | 0.15 | 0.85 | 0 | 1 | 1 - (0.85×0.85×1) = 0.23 |
| Table 3: The cost matrix for calculating minimum edit distance between the perceived string of phoneme v and a word w in the mental lexicon. Φ stands for null or no phoneme. The case where schwa in w is aligned with nothing in v (last row, 2nd column) corresponds to a case of schwa deletion, which is penalized by t — the duration of the schwa according to the current mental state of the listener | |||
| w: | Phoneme p (other than schwa) | Schwa (Duration = t) | Φ |
| v | |||
| Phoneme p (other then schwa) | 0 (if match) 2 (otherwise) | 2 | 2 |
| Schwa | 2 | 0 | 2 |
| Φ | 2 | t | NA |
| Table 4: Minimum distance alignment | |||||
| w | a | m | a | r | a (0.5) |
| v | a | m | a | r | Φ |
| cost | 0 | 0 | 0 | 0 | 0.5 |
| Table 5: Cost of alignment of amar with the different words in mental states Ri and Rj | ||
| Words | Cost of alignment | |
| Ri | Rj | |
| hara | 4 | 4 |
| mara | 4 | 2 |
| amara | 0.5 | 0.5 |
| krama | 6 | 6 |
Assumption 5: A phoneme that has not been correctly perceived is assumed to be deleted.
Justification: A phoneme that is not perceived correctly can be substituted for a similar sounding phoneme. For example, "par" can be heard as "bar", because /p/ and /b/ are similar sounding in the sense that both of them are labial stops. To incorporate this feature in our model, we need to define realistic phoneme-phoneme substitution probabilities, which are indeed considered while designing speech recognition systems. Firstly, this makes the perception model quite computationally intensive, increasing the simulation time significantly. Secondly, this reduces the chances of successful communication. Note that in reality the context (surrounding words) provides extensive clues for recognizing a word, which is completely absent in our model due to its limited scope. Thirdly, the only parameter considered here is phoneme and signal duration, which has a direct implication on deletion. The idea is not to deny the effect of a whole lot of other parameters on general human perception, but to focus specifically on the durational effects — which is arguably the most crucial factor in schwa deletion (Ohala 1983, Choudhury et al 2004).
| Table 6: Two runs of the experiment with different lexica | ||||||
| Words | Emergent pronunciation | Correct pronunciation | Words | Emergent pronunciation | Correct pronunciation | |
| hara | hra | har | mara | mar | mar | |
| amara | mar | amar | amara | amar | amar | |
| Case 6a | Case 6b | |||||
| Table 7: Time taken for simulation. The values reflect the real time and not the exact system time and are therefore dependent on system load. Machine specs: Pentium 4, 1.6 GHz | ||||
| Vocabulary size | Games played | Time req. (in secs) | Time req. (in secs) per million games | Time req. (in secs) per million games per word |
| 8 | 3M | 290 | 96.67 | 12.08 |
| 8 | 2M | 200 | 100 | 12.5 |
| 1800 | 55000 | 680 | 12363 | 6.87 |
| Table 8: The observations averaged over the language model of all the agents for the normalized lexicon. The parameters for this typical experiment were: N = 4, ksn = ksm = 0.7, psn = 0.6, psm =0.2, pfn = 0.6, pfm = 0.0, d = 0.01. Games required for convergence: 70 million | ||||
| Words | Vowel duration (in order of occurrence in the word) | Emergent Pronunciation | Pronunciation in standard Hindi | Number of errors |
| karaka | 1.99, 1.49, 0.00 | ka-rak | ka-rak | 0 |
| karakA | 2.00, 0.00, 2.00 | kar-kA | kar-ka | 0 |
| karAka | 2.00, 2.00, 0.00 | ka-rAk | ka-rAk | 0 |
| karAkA | 0.00, 2.00, 2.00 | krA-kA | ka-rA-kA | 1 |
| kAraka | 2.00, 1.99, 2.00 | kA-ra-ka | kA-rak | 1 |
| kArakA | 2.00, 0.50, 2.00 | kAr-kA | kAr-kA | 0 |
| kArAka | 2.00, 2.00, 0.00 | kA-rAk | kA-rAk | 0 |
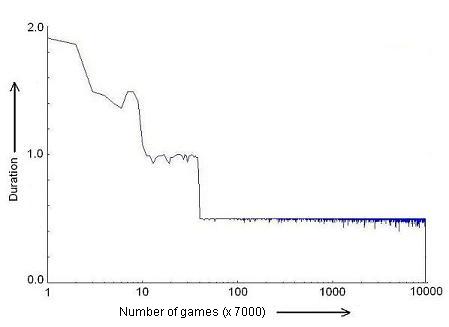
|
| Figure 5. The average duration of a schwa vs. the number of games. The plot is for the final schwa of the word karAka. The number of games is 7000 times the number shown in the plot. The scale is logarithmic |
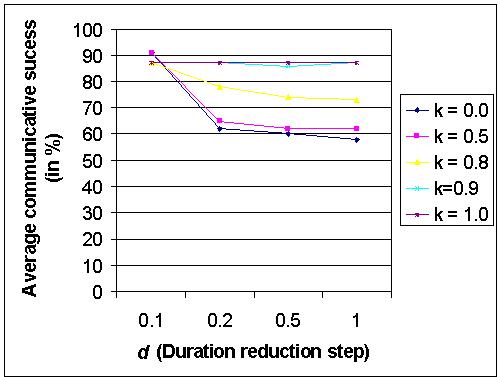
|
| Figure 6. The dependence of average communication success rate on d (duration reduction step) and learning threshold k (=ksn= ksm). Other simulation parameters: vocabulary size = 7, N = 4, psn = 0.6, psm =0.2, pfn = 0.6, pfm = 0.0, number of games=300000 |
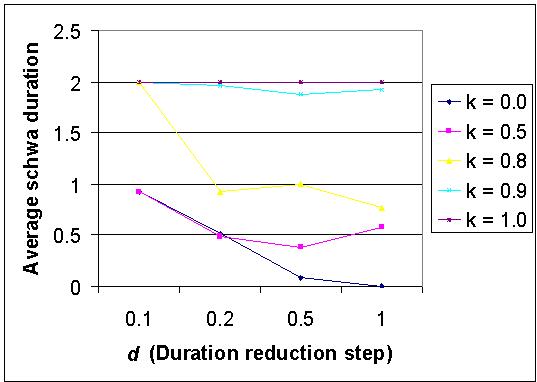
|
| Figure 7. The dependence of average schwa duration on d (duration reduction step) and learning threshold k (=ksn= ksm). Other simulation parameters: vocabulary size = 7, N = 4, psn = 0.6, psm =0.2, pfn = 0.6, pfm = 0.0, number of games=300000. The expected duration according to Ohala's rule is 1.07 |
The d vs. average schwa duration curve (Figure 7) however presents a slightly different scenario. It is clear that when k is small (0.5 or below), all the schwas are deleted leading to complete communication failure (as reflected in Figure 6). However, when k is very close to 1, the system becomes too strict to allow schwa deletion and the original pronunciations are retained. Such a system has very high communicative success rate (as reflected in Figure 6), but fails to facilitate the emergence of schwa deletion. For moderate values of k (between 0.5 and 1), a schwa deletion pattern emerges that is closer to the one observed in Hindi.
| Table 9: Different variants of a word that emerged during a simulation. The number of agents speaking that variant is given in the parentheses. Simulation parameters: N = 10, vocabulary size = 7, d = 0.1, psn = 0.6, psm =0.2, pfn = 0.6, pfm = 0.0, ksn= ksn= 0.9, number of games=3M | |
| Words | Variants |
| kArakA | kArkA (10) |
| karakA | krakA (4), krkA (3), karkA (2), karakA (1) |
| kAraka | kArk (10) |
| karAkA | krAkA (10) |
| karaka | karka (6), karak (4) |
| karAka | karAk (5), karAka (3), krAk (1), krAka (1) |
| kArAka | kArAk (10) |
| Table 10: The results for 10 different runs under the same parameter settings. Simulation parameters: N = 4, vocabulary size = 7, d = 0.1, psn = 0.6, psm =0.2, pfn = 0.6, pfm = 0.0, ksn= ksn= 0.9, number of games=3M | ||
| Random seed | Average Commu- nicative success (%) | Average schwa duration |
| 1 | 78.19 | 0.85 |
| 2 | 76.77 | 0.92 |
| 3 | 76.78 | 0.85 |
| 4 | 78.73 | 0.73 |
| 5 | 76.39 | 0.92 |
| 6 | 78.63 | 0.92 |
| 7 | 78.00 | 1.27 |
| 8 | 76.77 | 1.15 |
| 9 | 77.16 | 0.81 |
| 10 | 75.18 | 0.73 |
2Although the generative model of language is the most popular view in synchronic linguistics, there are other views on language and language models (e.g. empiricism, memetics, functionalist views, optimality theory etc.)
3The "?" in the left context "VCC?" of the rule implies that the final C is optional.
4Once, the process of deletion or epenthesis etc. becomes a part of the regular phonology of a language, these are no longer articulatory errors, and rather learnt pronunciation rules. But the reason why we observe them initially is due to general tendencies of the human articulation process towards such effects (Ohala 1989).
BAILEY, C.-J. (1973). Variation and linguistic theory. Washington, DC: Center for Applied Linguistics.
BHAT, D.N.S. (2001) Sound Change. Motilal Banarsidass, New Delhi
BRISCOE, T. (2000). Macro and micro models of linguistic evolution. In Proceedings of the 3rd International Conference on Language and Evolution.
BODIK P. (2003) "Language Change in Multi-generational Community", in Proceedings of CALCI-03, Elfa
CANGELOSI, A., and PARISI, D. (2001). How nouns and verbs differentially affect the behavior of artificial organisms. In J. D. Moore & K. Stenning (Eds.), Proceedings of the 23rd Annual Conference of the Cognitive Science Society (pp. 170-175). London: Erlbaum.
CANGELOSI, A. and PARISI, D. (Eds.) (2002) Simulating the Evolution of Language, London: Springer Verlag
CHEN, M., and WANG, W. (1975). Sound change: actuation and implementation. Language 51(2):255-281.
CHOMSKY, N. (1995) The minimalist program. MIT Press, Cambridge, MA
CHOPDE, A. (2001) "ITRANS version 5.30: A package for printing text in Indian languages using English-encoded input", Available at http://www.aczoom.com/itrans/
CHOUDHURY, M. and BASU, A. (2002) "A Rule Based Algorithm for Schwa Deletion in Hindi" Proc Int Conf Knowledge-Based Computer Systems, Navi Mumbai, pp. 343 — 353
CHOUDHURY M., BASU A. and SARKAR S. (2004) "A Diachronic Approach for Schwa Deletion in Indo-Aryan languages" In proceedings of SIGPHON'04, Barcelona, Spain, pp 20 — 26
CHRISTIANSEN, M. H. and DALE, R. (2003) "Language evolution and change". In M.A. Arbib (ed), Handbook of brain theory and neural networks (2nd ed.), pp 604-606. Cambridge, MA: MIT Press.
CLARK, R. and ROBERTS, I. (1993) "A Computational Model of Language Learnability and Language Change." Linguistic Inquiry, 24:299-345.
CLEMENTS, G. N. (1990). "The role of the sonority cycle in core syllabification." In: J. Kingston and M. Beckman (eds.), Papers in Laboratory Phonology I: Between the Grammar and the Physics of Speech, 283-333. Cambridge: Cambridge University Press
DE BOER, B. (2001) The Origins of Vowel Systems. Oxford University Press.
DRAS, M., HARRISON, D. and KAPICIOGLU, B. (2002) "Emergent Behavior in Phonological Pattern Change." Proceedings of Artificial Life VIII, 390--393. Sydney, Australia
DUTOIT T. (1997) An Introduction to Text-To-Speech Synthesis. Kluwer Academic Publishers
ELLEGARD, A. (1953). The auxiliary do: the establishment and regulation of its use in English. Stockholm: Almqvist & Wiksell.
FONTAINE, C. (1985) Application de m´ethodes quantitatives en diachronie: l'inversion du sujet en francais. Master's thesis, Universite du Qu´ebec `a Montreal.
FONTANA, J. M. (1993). Phrase structure and the syntax of clitics in the history of Spanish. PhD thesis, University of Pennsylvania.
HARE, M., and ELMAN, J. L. (1995). Learning and morphological change. Cognition, 56:61-98.
HARRISON, D., DRAS, M. and KAPICIOGLU, B. (2002) "Agent-Based Modeling of the Evolution of Vowel Harmony." in Proceedings of North East Linguistic Society 32 (NELS32), 217--236. New York, NY, USA
HAUSER, M. D., CHOMSKY, N., and FITCH, W. T. (2002) "The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?" Science, 298:1569 — 1579.
JUSCZYK, P. W. and Luce, P. A (2002) "Speech Perception and Spoken Word Recognition: Past and Present." Ear & Hearing. 23(1):2-40.
JURAFSKY, D. and MARTIN, J. H. (2000) Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, Prentice Hall
KE, J., OGURA, M., and WANG, W. S-Y. (2003) "Modeling evolution of sound systems with genetic algorithm" Computational Linguistics, 29(1):1 — 18
KIRBY, S. (2001). "Spontaneous evolution of linguistic structure -an iterated learning model of the emergence of regularity and irregularity." IEEE Transactions on Evolutionary Computation, 5(2):102-110.
KISHORE, S.P. and BLACK, A. (2003) "Unit size in unit selection speech synthesis" Proc of Eurospeech, Geneva, Switzerland.
KLEIN, S. (1966) "Historical Change in Language using Monte Carlo Techniques." Mechanical Translation and Computational Linguistics 9:67-82.
KLEIN, S. (1974). "Computer Simulation of Language Contact Models", in Toward Tomorrows Linguistics. R. Shuy and C-J. Bailey (eds), Georgetown: Georgetown University Press, pp 276-290.
KLEIN, S., KUPPIN, M. A., and KIRBY, A. (1969) Meives Monte Carlo simulation of language change in Tikopia and Maori. In the Proceedings of the International Conference on Computational Linguistics (COLING)
KROCH, A. S. (1989). "Reflexes of grammar in patterns of language change," Language Variation and Change 1:199-244
KROCH, A. S. (2001). "Syntactic change," in Mark Baltin and Cris Collins (eds.), The Handbook of Contemporary Syntactic Theory, Blackwell, Oxford, pp. 699-729.
KROCH, A. and TAYLOR, A. (1997) "Verb movement in Old and Middle English: dialect variation and language contact" in van Kemenade, A. and N. Vincent (ed.), Parameters of Morphosyntactic Change, Cambridge University Press, pp. 297- 325
LABOV W. (1972). Sociolinguistic Patterns. Philadelphia: University of Pennsylvania Press
LILJENCRANTS, J. and LINDBLOM, B. (1972). "Numerical simulation of vowel quality systems: the role of perceptual contrast". Language, 48:839 — 862.
LIGHTFOOT, D. (1991) How to Set Parameters: Arguments from Language Change. MIT Press/Bradford Books.
LIGHTFOOT, D. (1999) The development of language: Acquisition, change and evolution. Blackwell: Oxford.
LIVINGSTONE, D. and FYFE, C. (1999) "Modelling the Evolution of Linguistic Diversity". In D. Floreano, J. Nicoud and F. Mondada, (eds), ECAL99, pp 704-708. Berlin: Springer-Verlag.
LUPYAN, G. and MCCLELLAND, J.L. (2003). "Did, Made, Had, Said: Capturing Quasi-Regularity in Exceptions". Presented at the 25th Annual Conference of the Cognitive Science Society. Available at http://www.cnbc.cmu.edu/~glupyan/LandM-cogsci2003.pdf
MISRA, B. G. (1967) "Historical Phonology of Standard Hindi: Proto Indo European to the present" PhD Dissertation, Cornell University
NARASIMHAN, B., SPROAT, R., and KIRAZ, G. (2004). "Schwa-deletion in Hindi Text-to-Speech Synthesis," International Journal of Speech Technology, 7(4):319-333
NIYOGI, P (2002) "The Computational Study of Diachronic Linguistics." In D. Lightfoot (ed), Syntactic Effects of Morphological Change. Cambridge University Press
NIYOGI, P. (2006) The Computational Nature of Language Learning and Evolution. Cambridge, MA: MIT Press.
NIYOGI, P. and BERWICK, R. C. (1998) The Logical Problem of Language Change: A Case Study of European Portuguese. Syntax: A Journal of Theoretical, Experimental, and Interdisciplinary Research, 1.
OHALA, M. (1983) Aspects of Hindi Phonology. MLBD Series in Linguistics, Motilal Banarsidass, New Delhi.
OHALA, J. (1989). "Sound change is drawn from a pool of synchronic variation". In L.E. Breivik & E.H. Jahr (Eds.), Language change: Contributions to the study of its causes. Berlin: Mouton de Gruyter
OUDEYER, P.-Y. (1999). "Self-organization of a lexicon in a structured society of agents." In D. Floreano, J.-D. Nicoud, & F. Mondada (Eds.), Advances in artificial life: The Fifth European Conference (ECAL '99) 1674:725-729). Berlin: Springer.
OUDEYER, P-Y. (2005) "The Self-Organization of Speech Sounds", Journal of Theoretical Biology, 233(3): 435- 449
PARISI, D. and CANGELOSI, A. (2002) "A Unified Simulation Scenario for Language Development, Evolution, and Historical Change." In A. Cangelosi and D. Parisi (eds), Simulating the Evolution of Language, pp 255-276. London: Springer Verlag
PERFORS, A. (2002) "Simulated Evolution of Language: a Review of the Field" Journal of Artificial Societies and Social Simulation, 5(2).
ROBERTS, I. (2001) "Language change and learnability". In S. Bertolo (Ed.), Parametric Linguistics and Learnability: a Self Contained Tutorial for Linguists, Cambridge University Press
RUSSELL, S. J and NORVIG, P (2003) Artifical Intelligence: A Modern Approach. Prentice Hall, Upper Saddle River, New Jersey, second edition.
SCHWARTZ, J. L., BOEK, L. J., VALLEHE, N. and ABRY, C. (1997) "The dispersion-focalization theory of vowel systems", Journal of Phonetics, 25, 255 — 286
SMITH A. D. M. (2005). "Mutual Exclusivity: Communicative Success Despite Conceptual Divergence". In Maggie Tallerman, editor, Language Origins: Perspectives on Evolution. Oxford University Press.
SMITH, K. and HURFORD, J. R. (2003) "Language Evolution in Populations: Extending the Iterated Learning Model" in W. Banzhaf, T. Christaller, J. Ziegler, P. Dittrich and J. T. Kim (eds.) Advances in Artificial Life: Proceedings of the 7th European Conference on Artificial Life, pp. 507-516.
STEELS, L. (1997) "The synthetic modeling of language origins" Evolution of Communication, 1(1):1 — 34
STEELS, L. (2001) "Language games for autonomous robots" IEEE Intelligent systems, pp 16 — 22
TURNER, H. (2002) "An Introduction to Methods for Simulating the Evolution of Language" In Angelo Cangelosi and Domenico Parisi, editors, Simulating the Evolution of Language, pp 29 — 50. London: Springer Verlag.
WANG, W. S-Y. and Minett, J. W. (2005) The invasion of language: emergence, change and death. Trends in Ecology and Evolution, 20(5):263-269
WAGNER, K., REGGIA, J. A., URIAGEREKA, J., and WILKINSON, G. S. (2003) Progress in the simulation of emergent communication and language. Adaptive Behavior, 11(1):37--69.
WEINREICH, U., LABOV, W. and HERZOG, M. (1968). "Empirical foundations for a theory of language change" In W. P. Lehmann & Y. Malkeil (eds.), Directions for historical linguistics: A symposium. Austin: University of Texas Press. 95-188
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2006]