
Riccardo Boero and Flaminio Squazzoni (2005)
Does Empirical Embeddedness Matter? Methodological Issues on Agent-Based Models for Analytical Social Science
Journal of Artificial Societies and Social Simulation
vol. 8, no. 4
<https://www.jasss.org/8/4/6.html>
For information about citing this article, click here
Received: 02-Oct-2005 Accepted: 02-Oct-2005 Published: 31-Oct-2005

 Abstract
Abstract
|
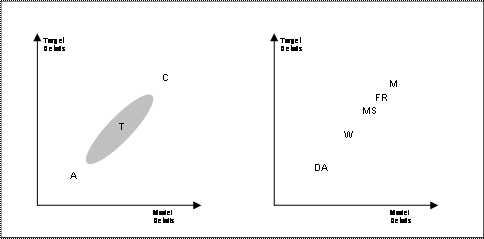
| Figure 1. A representation of ABMs taxonomy according to target and model richness of empirical detail (on the left), and the example of fish markets (on the right) |
2As Coser stressed (Coser 1977), there are different kinds of “ideal types” in the Weberian means, three at least. The first is historical routed ideal types, such as the well known cases of “the protestant ethics” or “capitalism”. The second one refers to abstract concepts of social reality, such as “bureaucracy”, while the third one refers to a rationalised typology of social action. This last is the case of economic theory and rational choice theory. These are different possible meanings of the term “ideal type”. In our view, the first two meanings refer to a heuristic theoretical constructs that aim at understanding empirical reality, while the third one refers to “pure” theoretical (as well as normative) aims. Such a redundancy in the meaning of the term has been strongly criticised. According to our taxonomy, typifications include just the first two meanings of the Weberian “ideal type”, while the third meaning refers to what we call abstractions.
3The choice of the research path to effectively address the scholar's question and the choice of the kind of ABM to be exploited in such attempt are out of the scope of the present work. We just want to further underline that the introduction of the ABMs taxonomy is intended to shed light on the relationship between models and empirical data and that such classification does not represent a bound to the flexibility of research paths.
4For a good introduction to Anasazi, see Stuart 2000 and Morrow and Price 1997.
5The model is based on Sugarscape platform developed by Epstein and Axtell 1996.
6Most of these efforts have been supported by the findings of a previous survey on the ground, called “Long House Valley Project”, realised by a multidisciplinary team from Museum of Northern Arizona, Laboratory of Tree-Riding Research of the Arizona University and Southwestern Anthropological Research Group. The result has been a database which has been translated and integrated into the Anasazi model.
7It is also important to consider that in the 200 A.D. to 1450 A.D. period, in the area, the only technological innovation introduced has been a more efficient way to grind the maize.
8Even if the case of the water demand model allows to show how the stakeholder involvement has brought into the model relevant qualitative data, which were unknowable for the model maker before, it is worth outlining that, in many cases, such an involvement could allow the model maker to access also quantitative data that, in other ways, were unknowable, for instance, because they weren't a common knowledge, or they were protected from outside access. This may be a common situation when, for example, the model target includes a firm or a corporate actor.
AXELROD R (1984) The Evolution of Cooperation. New York: Basic Books.
AXELROD R (1997) The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration. Princeton, New Jersey: Princeton University Press.
AXELROD R (1998) Advancing the Art of Simulation in the Social Sciences. Complexity, 3, 2. pp. 16-22.
AXELROD R, RIOLO R L and COHEN M D (2002) Beyond Geography: Cooperation with Persistent Links in the Absence of Clustered Neighborhoods. Personality and Social Psychology Review, 6, 4. pp. 341-346.
AXTELL R (1999) Why Agents? On the Varied Motivations for Agent Computing in the Social Sciences. Center on Social and Economic Dynamics, Working Paper No. 17. http://www.brookings.edu/es/dynamics/papers/agents/agents.
AXTELL R, AXELROD R, EPSTEIN J M, and COHEN M D (1996) Aligning Simulation Models: A Caste Study and Results. Computational and Mathematical Organization Theory, 1, 2. pp. 123-141.
BARBERA F (2004) Meccanismi sociali. Elementi di sociologia analitica. Bologna: il Mulino.
BARRETEAU O, BOUSQUET F, ATTONATY J M (2001) Role-Playing Games for Opening the Black Box of Multi-Agent Systems: Method and Lessons of Its Application to Senegal River Valley Irrigated Systems. Journal of Artificial Societies and Social Simulation, Vol. 4, No. 2 . https://www.jasss.org/4/2/5.html.
BELUSSI F and GOTTARDI G (Eds.) (2000) Evolutionary Patterns of Local Industrial Systems: Towards a Cognitive Approach to Industrial Districts. Aldershot Brookfield Singapore Sidney: Ashgate.
BELUSSI F, GOTTARDI G, RULLANI E (2003) The Tecnological Evolution of Industrial Districts. Boston/Dordrecht/New York/London: Kluwer Academic Publishers.
BOERO R, CASTELLANI M, SQUAZZONI F (2004) "Cognitive Identity and Social Reflexivity of the Industrial District Firms. Going Beyond the 'Complexity Effect' with an Agent-Based Computational Prototype. In (Eds), Lindermann G, Modt D, Paolucci M, Regulated Agent-Based Social Systems. Berlin Heidelberg: Springer Verlag. pp. 48-69.
BORRELLI F, PONSIGLIONE C, IANDOLI L and ZOLLO G (2005) Inter-Organizational Learning and Collective Memory in Small Firms Clusters: An Agent-Based Model. Journal of Artificial Societies and Social Simulation, Vol. 8, No. 3. https://www.jasss.org/8/3/4.html.
BOUDON R (1979) "Generative Models as a Research Strategy". In (Eds) Merton R K, Coleman J S, and Rossi P H, Qualitative and Quantitative Social Research: Papers in Honor of Paul F. Lazarfield. New York: The Free Press. pp. 51-64.
BOUSQUET F et AL. (2003) "Multi-Agent Systems and Role Games: Collective Learning Processes for Ecosystem Management". In Janssen M A (Ed.), Complexity and EcoSystem Management. The Theory and the Practice of Multi-Agent Systems. Cheltenham UK, Northampton, Massachussets: Edward Elgar. pp. 243-280.
BRENNER T (2001) Simulating the Evolution of Localized Industrial Clusters-An Identification of the Basic Mechanisms. Journal of Artificial Societies and Social Simulation, Vol. 4, No. 3. http://www-soc.surrey.ac.uk/JASSS/4/3/4.html.
BRENNER T and MURMANN J P (2003) The Use of Simulations in Developing Robust Knowledge about Causal Processes: Methodological Considerations and an Application to Industrial Evolution. Papers on Economics and Evolution 0303. Max Planch Institute.
BRUCH E E and MARE R D (2005), Neighborhood Choice and Neighborhood Change. California Center for Population Research, Working Paper Series, CCPR-007-04.
BRUSCO S, MINERVA T, POLI I and SOLINAS G (2002) Un automa cellulare per lo studio del distretto industriale. Politica Economica, 18. pp. 147-192.
BURTON R M (1998) "Validating and Docking: An Overview, Summary and Challenge". In Prietula M, Carley K and Gasser L (Eds.), Simulating Societies: Computational Models of Institutions and Groups. Cambridge, Massachusetts: AAAI/MIT Press.
CARLEY K M (2002) "Simulating Society: The Tension between Transparency and Veridicality". In Macal C and Sallach D. (Eds.), Proceedings of the Agent 2002 Conference on Social Agents: Ecology, Exchange and Evolution. Arbonne, Illinois: Argonne National Laboratory. pp. 103-114.
CARLSON L et AL (2002) "Empirical Foundations for Agent-Based Modeling: How Do Institutions Affect Agents' Land-Use Decision Processes in Indiana?". In Macal C and Sallach D. (Eds.), Proceedings of the Agent 2002 Conference on Social Agents: Ecology, Exchange and Evolution. Arbonne, Illinois: Argonne National Laboratory. pp. 133-148.
CASTI J (1994) Complexification. Explaining a Paradoxical World through the Science of Surprise. New York: Harper Collins.
CIOFFI-REVILLA C and GOTTS N M (2003) Comparative Analysis of Agent-Based Social Simulations: GeoSim and FEARLUS models. In Proceedings, International Workshop M2M: "Model to Model" Workshop on Comparing Multi-Agent Based Simulation Models. Marseille, France, March 31-April 1, 2003, pp. 91-110.
COLEMAN J (1990) Foundations of Social Theory. Cambridge, MA: Harvard University Press.
CONTE R and PAOLUCCI M (2002) Reputation in Artificial Societies. Social Beliefs for Social Order. Dordrecht: Kluwer Academic Publishers.
COSER L A (1977) Masters of Sociological Thought: Ideas in Historical and Social Context. New York: Harcourt Brace Jovanovich.
DAL FORNO A and MERLONE U (2004) From Classroom Experiments to Computer Code. Journal of Artificial Societies and Social Simulation, Vol. 7, No. 3. https://www.jasss.org/7/3/2.html.
DEAN S J, GUMERMAN G J, EPSTEIN J M, AXTELL R, SWEDLUND A C, PARKER M T, MCCARROLL S (2000) Understanding Anasazi Culture Change Through Agent-Based Modeling. In (Eds.) Kohler T A, Gumerman G J, Dynamics in Human and Primate Societies. Agent-Based Modeling of Social and Spatial Processes. Santa Fe Institute Studies in the Sciences of Complexity, New York: Oxford University Press. pp. 179-205.
DUFFY J (2004) Agent-Based Models and Human Subject Experiments, in K.L. Judd and L. Tesfatsion (Eds.) Handbook of Computational Economics vol. 2, Elsevier, Amsterdam, forthcoming.
EDMONDS B and HALES D (2003) Replication, Replication, Replication: Some Hard Lessons from Model Alignment. Journal of Artificial Societies and Social Simulation, Vol. 6, No. 4. https://www.jasss.org/6/4/11.html.
EDMONDS B and MOSS S (2005) From KISS to KIDS: An 'Anti-Simplistic' Modelling Approach. In (Eds) Davidsson P et al., Multi Agent Based Simulation, Lectures Notes in Artificial Intelligence, 3415, Heidelberg: Springer-Verlag. pp. 130-144.
ELIAS N (1939) The Civilizing Process. Oxford, Blackwell, 1994.
ELIAS N (1969) The Court Society. New York, Pantheon, 1983.
ELIASSON G and TAYMAZ E (2000) Institutions, Entrepreneurship, Economic Flexibility and Growth - Experiments on an Evolutionary Micro-to-Macro Model. In (Eds) Cantner U, Hanusch H and Klepper S, Economic Evolution, Learning, and Complexity, Heidelberg: Springer-Verlag. pp. 265-286.
ELSTER J (1979) Ulysses and the Sirens: Studies in Rationality and Irrationality. Cambridge: Cambridge University Press.
ELSTER J (1998) "A Plea for Mechanisms". In (Eds.) Hedstrom P and Swedberg R, Social Mechanisms. An Analytical Approach to Social Theory. Cambridge: Cambridge University Press. pp. 45-73.
ELSTER J (2000) Ulysses Unbound. Studies in Rationality, Precommitment and Constraints. Cambridge: Cambridge University Press.
EPSTEIN J M (1999) Agent-Based Models and Generative Social Science. Complexity, 4, 5. pp. 41-60.
EPSTEIN J M and AXTELL R (1996) Growing Artificial Societies. Social Science from the Bottom-Up. Cambridge, Massachusetts: The MIT Press.
ETIENNE M, LE PAGE C and COHEN M (2003) A Step-by-Step Approach to Building Land Management Scenarios Based on Multiple Viewpoints on Multi-Agent System Simulations. Journal of Artificial Societies and Social Simulation, Vol. 6, No. 2. https://www.jasss.org/6/2/2.html.
FIORETTI G (2001) Information Structure and Behaviour of a Textile Industrial District. Journal of Artificial Societies and Social Simulation, Vol. 4, No. 4. https://www.jasss.org/4/4/1.html.
GILBERT N (2002) "Varieties of Emergence". In (ed) Sallach D, Social Agents: Ecology, Exchange, and Evolution. Agent 2002 Conference. University of Chicago and Argonne National Laboratory. pp. 41-54.
GILBERT N and TROITZSCH K G (1999) Simulation for the Social Scientist. Buckingham Philadelphia: Open University Press.
GOLDTHORPE J H (2000) On Sociology. Oxford: Oxford University Press.
GOTTS N M, POLPHILL J G and LAW A N R (2003a) Agent-Based Simulation in the Study of Social Dilemmas. Artificial Intelligence Review, 19. pp. 3-92.
GOTTS N M, POLHILL J G and LAW A N R (2003b) Aspiration levels in a land use simulation. Cybernetics & Systems, 34 (8). pp. 663-683
GOTTS N M, POLHILL J G, LAW A N R and IZQUIERDO L R (2003) Dynamics of Imitation in a Land Use Simulation. In Proceedings of the AISB '03 Second International Symposium on Imitation in Animals and Artifacts, 7-11 April 2003, University of Wales, Aberystwyth. pp. 39-46.
GOULD S J and ELDREDGE N (1972) Punctuated Equilibria : The Tempo and Mode of Evolution Reconsidered. Paleobiology, 3. pp. 115-151.
GUMERMAN G J, SWEDLUND A C, DEAN J S, EPSTEIN J M (2002) The Evolution of Social Behavior in the Prehistoric American Southwest. Santa Fe Institute, Working Paper.
GUMERMAN G J and KOHLER T A (1996) Creating Alternative Cultural Histories in the Prehistoric Southwest : Agent-Based Modeling in Archeology. Santa Fe Institute, Working Paper.
HEDSTRÖM P and SWEDBERG R (1998) (eds), Social Mechanisms: An Analytical Approach to Social Theory, Cambridge, Cambridge University Press.
HOFFMANN R (2000) Twenty Years on: The Evolution of Cooperation Revisited. Journal of Artificial Societies and Social Simulation, Vol. 3, No. 2 . https://www.jasss.org/3/2/forum/1.html.
IZQUIERDO L R, GOTTS N M and POLHILL J G (2003) FEARLUS-W: An Agent-Based Model of River Basin Land Use and Water Management. Paper presented at "Framing Land Use Dynamics: Integrating knowledge on spatial dynamics in socio-economic and environmental systems for spatial planning in western urbanized countries", International Conference 16-18 April 2003, Utrecht University, The Netherlands.
JACKSON D, HOLCOMBE M, RATNIEKS F (2004) Coupled Computational Simulation and Empirical Research into Foraging Systems of Pharaoh's Ant (Monomorium Pharaonis). Biosystems, 76. pp. 101-112.
KING G, VERBA S and KEOHANE R O (1994) Designing Social Inquiry: Scientific Inference in Qualitative Research. Princeton: Princeton University Press.
KIRMAN A P and VRIEND N (2000) "Evolving Market Structure: A Model of Price Dispersion and Loyalty for the Marseille Fish Market". In Delli Gatti D, Gallegati M and Kirman A P (Eds.), Interaction and Market Structure. Berlin Heidelberg: Springer Verlag.
KIRMAN A P and VRIEND N (2001) Evolving market structure: an ACE model of price dispersion and loyalty. Journal of Economic Dynamics and Control, 25. pp. 459-502.
LANE D A (2002) "Complexity and local interactions: Towards a theory of industrial districts". In (Eds.) Quadrio Curzio A and Fortis M, Complexity and Industrial Clusters: Dynamics and Models inTheory and Practice. Berlin: Springer Verlag.
MACY M and WILLER (2002) From Factors to Actors: Computational Sociology and Agent-Based Modelling. American Sociological Review, 28. pp. 143-166.
MAHONEY J (2001) Beyond Correlational Analysis: Recent Innovations in Theory and Method. Sociological Forum, 16, 3. pp. 575-593.
MANSON S M (2003) "Validation and Verification of Multi-Agent Systems". In Janssen M A (Ed.), Complexity and EcoSystem Management. The Theory and the Practice of Multi-Agent Systems. Cheltenham UK, Northampton, Massachussets: Edward Elgar. pp. 58-69.
MERTON R K (1949) Social Theory and Social Structure. New York: Free Press.
MORROW B H and PRICE V B (1997) Anasazi Architecture and American Design. Albuquerque: University of New Mexico Press.
MOSS S (1998) Critical Incident Management: An Empirically Derived Computational Model. Journal of Artificial Societies and Social Simulation, Vol. 1, No. 4. https://www.jasss.org/1/4/1.html.
MOSS S and EDMONDS B (2004) Towards Good Social Science. Centre for Policy Modelling Report.
MOSS S and EDMONDS B (2005) Sociology and Simulation: Statistical and Qualitative Cross-Validation. American Journal of Sociology, 110, 4. pp. 1095-1131.
PANCS R and VRIEND R J (2003) Schelling's Spatial Proximity Model of Segregation Revisited. University of London, Department of Economics, Working Paper No. 487.
PAWSONS R and TILLEY N (1997), Realistic Evaluation. London, Sage.
POLHILL J G, GOTTS N M and LAW A N R (2001) Imitative and nonimitative strategies in a land use simulation. Cybernetics & Systems, 32 (1-2). pp. 285-307.
POLHILL J G, IZQUIERDO L R and GOTTS N M (2005) The Ghost in the Model (and Other Effects of Floating Point Arithmetic). Journal of Artificial Societies and Social Simulation, Vol. 8, No. 1. https://www.jasss.org/8/1/5.html.
PRIETULA M K, CARLEY K and GASSER L (1998) Simulating Organizations: Computational Models of Institutions and Groups. Cambridge, Massachusetts: The MIT Press.
PYKA A and AHRWEILER P (2004) "Applied Evolutionary Economics and Social Simulation", Journal of Artificial Societies and Social Simulation, Vol. 7, No. 2. https://www.jasss.org/7/2/6.html.
RAGIN C C (1987) The Comparative Method: Moving Beyond Qualitative and Quantitative Strategies. Berkley: University of California Press.
SAWYER R K (2003) Artificial Societies. Multi-Agent Systems and the Micro-Macro Link in Sociological Theory. Sociological Methods and Research, Vol. 31, No. 3. pp. 325-363.
SCHELLING T (1971) Dynamic Models of Segregation. Journal of Mathematical Sociology, 1. pp.143-186.
SQUAZZONI F and BOERO R (2002) Economic Performance, Inter-Firm Relations and "Local Institutional Engineering" in an Agent-Based Computational Prototype of Industrial Districts. Journal of Artificial Societies and Social Simulation, Vol. 5, No. 1.https://www.jasss.org/5/1/1.html.
SQUAZZONI F and BOERO R (2005) "Towards an Agent-Based Computational Sociology. Good Reasons to Strengthen a Cross Fertilization Between Complexity and Sociology". In Stoneham (Ed.), Advance in Sociology Research II, New York: NovaScience Publishers. pp. 103-133.
STAME N (2004) Theory-Based Evaluation and Types of Complexity. Evaluation, vol. 10, 1. pp. 58-76.
STUART D E (2000) Anasazi America. Albuquerque: University of New Mexico Press.
TROITZSCH K G (2004) "Validating Simulation Models". Proceedings of 18th European Simulation Multiconference on Networked Simulation and Simulation Networks, SCS Publishing House. pp. 265-270.
WARE J (1995) George Gumerman: The Long View. Santa Fe Institute Bulletin, Winter.
WEBER M (1904) Objectivity of Social Science and Social Policy. In The Methodology of the Social Sciences. Edward Shils and Henry Finch (Eds.), 1949, New York: Free Press.
WERKER C and BRENNER T (2004) Empirical Calibration of Simulation Models. ECIS Working Paper 04.013.
WILLER D and WEBSTER M (1970) Theoretical Concepts and Observables. American Sociological Review, 35. pp. 748-757.
ZACHARIA and MAES (2000). Trust management through reputation mechanisms. Applied Artificial Intelligence, 14. pp. 881-907.
ZHANG J (2003) Growing Silicon Valley on a Landscape: an Agent-Based Approach to High-Tech Industrial Clusters. Journal of Evolutionary Economics, 13. pp. 529-548.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2005]