
Nils B. Weidmann and Luc Girardin (2005)
Technical Note: Evaluating Java Development Kits for Agent-Based Modeling
Journal of Artificial Societies and Social Simulation
vol. 8, no. 2
<https://www.jasss.org/8/2/8.html>
To cite articles published in the Journal of Artificial Societies and Social Simulation, reference the above information and include paragraph numbers if necessary
Received: 23-Feb-2005 Accepted: 24-Feb-2005 Published: 31-Mar-2005
 Abstract
Abstract| Table 1: Execution times for the Schelling model in milliseconds | |||||||
| Sun 1.4.2 Client | Sun 1.4.2 Server | Sun 1.5.0 Client | Sun 1.5.0 Server | JRockit 1.4.2 | JRockit 1.5.0 | IBM 1.4.2 | |
| Win XP | 4748 [103] | 3348 [111] | 3044 [68] | 2315 [92] | 4997 [221] | 3360 [470] | 3375 [87] |
| Linux FC 2 | 5108 [131] | 3772 [118] | 3038 [69] | 2393 [90] | 5072 [240] | 3384 [441] | 3564 [92] |
| Table 2: Execution times for the IPD model in milliseconds | |||||||
| Sun 1.4.2 Client | Sun 1.4.2 Server | Sun 1.5.0 Client | Sun 1.5.0 Server | JRockit 1.4.2 | JRockit 1.5.0 | IBM 1.4.2 | |
| Win XP | 4955 [45] | 3199 [102] | 4089 [86] | 3011 [103] | 2417 [240] | 2277 [441] | 2183 [109] |
| Linux FC 2 | 5253 [67] | 3250 [153] | 4229 [69] | 3108 [141] | 2668 [329] | 2466 [458] | 2245 [152] |
| Table 3: SciMark 2.0 benchmark scores | |||||||
| Sun 1.4.2 Client | Sun 1.4.2 Server | Sun 1.5.0 Client | Sun 1.5.0 Server | JRockit 1.4.2 | JRockit 1.5.0 | IBM 1.4.2 | |
| Win XP | 184.50 [0.28] | 428.71 [0.98] | 187.59 [0.23] | 437.46 [1.81] | 299.37 [0.84] | 307.26 [0.53] | 384.04 [0.45] |
| Linux FC 2 | 191.19 [0.87] | 423.94 [0.99] | 184.39 [0.85] | 426.10 [2.45] | 306.37 [1.93] | 297.80 [3.23] | 380.69 [2.71] |
|
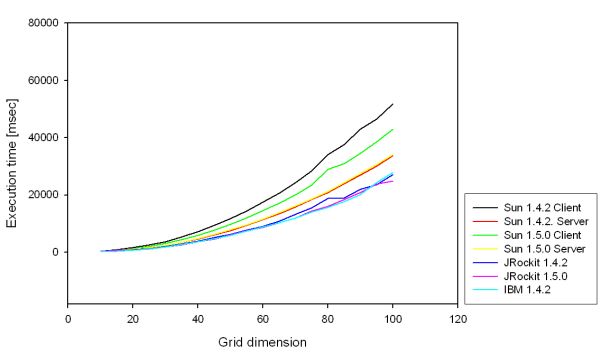
| Figure 1. Scaling behavior of the IPD under WinXP |
|
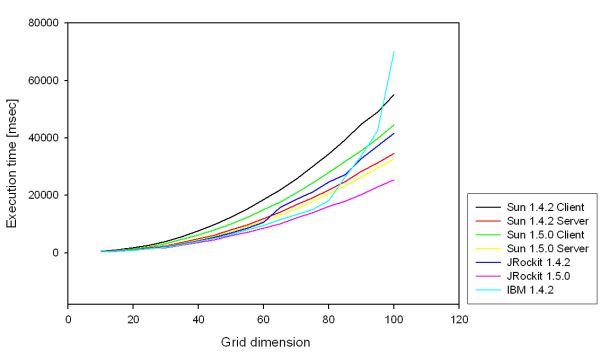
| Figure 2. Scaling behavior of the IPD under Linux FC2 |
2A 2.4 kernel was chosen because of stability considerations with our hardware configuration. Running the experiments on a 2.6 kernel could speed up execution; however, we do not expect major differences.
BEA SYSTEMS INC. (2005) 'BEA JRockit Website', http://www.bea.com/framework.jsp?CNT=index.htm&FP=/content/products/jrockit/.
COHEN, MICHAEL D, RIOLO, RICK L, and AXELROD, ROBERT (1999), The Emergence of Social Organization in the Prisoner's Dilemma: How Context-Preservation and Other Factors Promote Cooperation, SFI Working Papers, http://www.santafe.edu/research/publications/wpabstract/199901002.
IBM CORPORATION (2004) 'Java 2 Diagnostics Guide, Version 1.4.2', http://www.ibm.com/developerworks/java/jdk/diagnosis/diag142.pdf.
IBM CORPORATION (2005) 'IBM Java Website', http://www.ibm.com/developerworks/java/jdk/.
MICROSOFT CORPORATION (2005) 'Windows XP Home Page', http://www.microsoft.com/windowsxp/default.mspx.
POZO, ROLDAN and MILLER, BRUCE (2000) 'SciMark 2.0 Benchmark', http://math.nist.gov/scimark2/.
RED HAT INC. (2004) 'Fedora Project Website', http://fedora.redhat.com/.
REPAST DEVELOPERS GROUP (2005) 'RePast Home Page', http://repast.sourceforge.net.
SCHELLING, THOMAS C. (1978), Micromotives and Macrobehavior (New York: Norton).
SUN MICROSYSTEMS INC. (2002) 'The Java HotSpot(TM) Virtual Machine', http://java.sun.com/products/hotspot/docs/whitepaper/Java_Hotspot_v1.4.1/JHS_141_WP_d2a.pdf.
SUN MICROSYSTEMS INC. (2005) 'Java Technology Website', http://java.sun.com.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2005]