
Gary Polhill and Luis Izquierdo (2005)
Lessons Learned from Converting the Artificial Stock Market to Interval Arithmetic
Journal of Artificial Societies and Social Simulation
vol. 8, no. 2
<https://www.jasss.org/8/2/2.html>
To cite articles published in the Journal of Artificial Societies and Social Simulation, reference the above information and include paragraph numbers if necessary
Received: 17-Dec-2004 Accepted: 08-Feb-2005 Published: 31-Mar-2005
 Abstract
AbstractA (with minimum a1, maximum a2) and B (b1, b2), the greater-than operation, for example, can be interpreted in two ways akin to modal logic (Kripke 1963). A is possibly-greater-than B if there exists a member of A's interval that is greater than a member of B's interval, i.e. if a2 > b1. A is necessarily-greater-than B if all members of A's interval are greater than all members of B's interval, i.e. if a1 > b2. It is not always clear which of these two should be used. For example consider a piece of code using floating point arithmetic:
if(A > B)
{
/* do something */
}
else
{
/* do something else */
}
A and B, each with consequences that may not make sense in the set of actions following the condition:
if(A possibly > B)
{
/* but A possibly <= B */
}
else
{
/* OK */
}
or:
if(A necessarily > B)
{
/* OK */
}
else
{
/* but A possibly > B */
}
To get round this problem, the Interval class stores the floating point arithmetic result (e.g. a_fp and b_fp, for A and B above) as well as the interval arithmetic result. The default replacement comparison operators return the result of comparing a_fp and b_fp, but make a check using the intervals and issue a warning if the comparison result could be wrong. For example, when checking if A > B, the result returned is the comparison of a_fp > b_fp. If this comparison is True, then a warning is issued if A is possibly ≤ B; if False, then a warning is issued if A is possibly > B. This deals with the two 'buts' in the conversion example above, and also allows a warning to be generated if the floating point arithmetic result has sufficient error in it that the program would potentially be following a different branch in the code if it were using real numbers.
if(X > 0)
/* X is known independently to be positive or zero */
{
Y = Z / X;
}
else
{
/* Set Y to some other value */
}
The default greater-than operator works as described above, the test depending on a comparison of x_fp with zero. Although X is known by the programmer to be positive or zero, this is not reflected in the code anywhere (there being no unsigned double datatype), meaning that x1 could be ≤ 0, and x_fp > 0. The Interval class will issue a warning in the comparison operation, but the result will nonetheless be that Y is divided by a range containing zero.
The way to deal with these problems is to use one of the interval comparison operators instead, in this case:
if(X necessarily > 0)
{
Y = Z / X;
}
else
{
/* set Y to some other value */
}
This, however, will have an effect on the behaviour of the model if floating point errors accumulate sufficiently, as the more stringent requirement that x1 > 0 means that we should expect the consequent to be evaluated less often than when requiring that x_fp > 0.
|
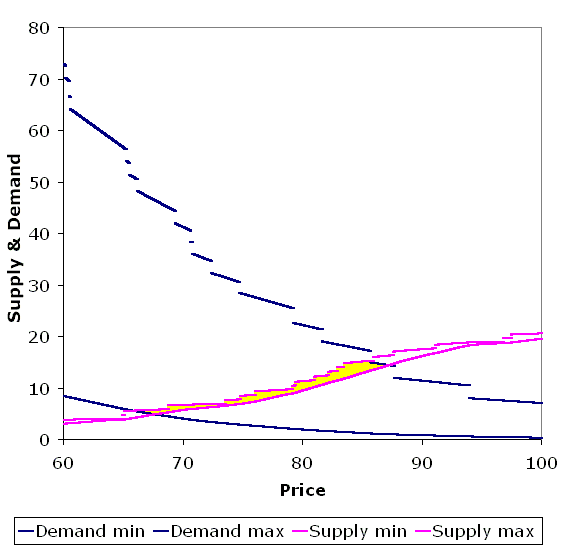
| Figure 1. Uncertainty in the demand of agents for the risky stock after just seven cycles of trading in one run of the interval arithmetic ASM. The yellow region shows where the supply and demand ranges intersect, meaning that the price to clear the market could be anywhere between 67 and 87. |
|
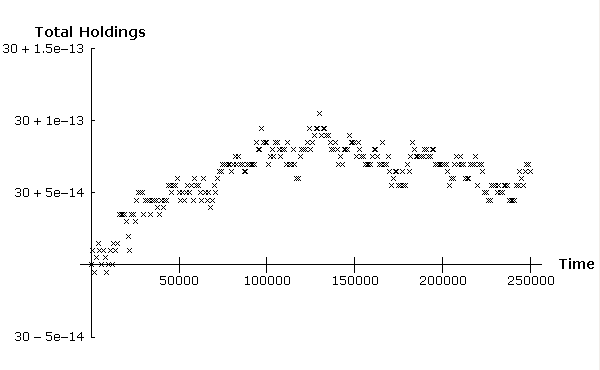
| Figure 2. Graph showing the total holding of shares in the floating point arithmetic version of the ASM every 1000 cycles over a period of 250000 cycles. A negligible deviation from the correct constant value of 30 is observed. |
|
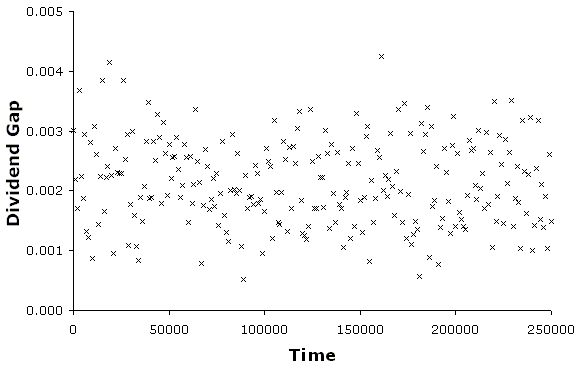
| Figure 3. A scatter graph of difference between the maximum and the minimum of the dividend interval (the dividend gap) in the interval arithmetic version of the ASM every 1000 time steps. |
#include <ieeefp.h>
/* ... */
int main(int argc, char **argv) {
/* variable declarations */
fpsetmask(FP_X_INV, FP_X_IMP, FP_X_DZ, FP_X_UFL, FP_X_OFL);
The fpsetmask() function[2] ensures that a floating point signal (SIGFPE) will be generated whenever an issue has arisen with a floating point operation. According to the POSIX standard (IEEE and Open Group 2004), the default action on receiving SIGFPE is to abort. With this line of code at the beginning of the main function, if the program runs without aborting, it is unquestionably free of floating point errors. This is so trivial to implement there is little excuse for not doing it.
signal() function:
#include <signal.h> /* ... */ signal(SIGFPE, SIG_IGN); // ignore SIGFPE /* offending unimportant line(s) of code */ signal(SIGFPE, SIG_DFL); // handle SIGFPE
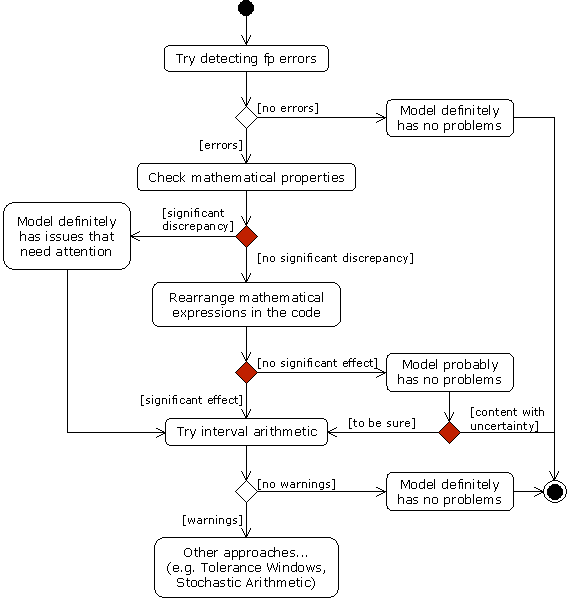
|
| Figure 4. Suggested flow of activity for investigating possible floating point number representation issues in a model. Red decisions (diamonds) represent a judgement of the investigator. |
2Note that on Cygwin, the ieeefp.h functions are not implemented. An implementation is provided for Intel CPUs at http://www.macaulay.ac.uk/fearlus/floating-point/download.html.
GOTTS, N M, Polhill, J G and Law, A N R (2003), Aspiration levels in a land use simulation. Cybernetics & Systems 34, pp. 663-683
EDMONDS, B and Hales, D (2003), Replication, replication and replication: Some hard lessons from model alignment. Journal of Artificial Societies and Social Simulation 6 (4), https://www.jasss.org/6/4/11.html.
HIGHAM, N J. (2002), Accuracy and Stability of Numerical Algorithms. 2nd ed. Philadelphia: Society for Industrial and Applied Mathematics
IEEE (1985), IEEE Standard For Binary Floating-Point Arithmetic. IEEE 754-1985, New York, NY: Institute of Electrical and Electronics Engineers
IEEE and Open Group (2004), The Open Group Base Specifications Issue 6, IEEE Std 1003.1. 2004 ed. http://www.unix.org/single_unix_specification/
JOHNSON, P (2002), Agent-based modeling: What I learned from the Artificial Stock Market. Social Science Computer Review 20, pp. 174-186
KNUTH, D E (1998), The Art of Computer Programming. Vol. 2. Semi-Numerical Algorithms. 3rd ed. Boston: Addison-Wesley
KRIPKE, S (1963), Semantical considerations on modal logic. Acta Philosophica Fennica 16, 83-94
LEBARON, B, Arthur, W B and Palmer, R (1999), Time series properties of an artificial stock market. Journal of Economic Dynamics & Control 23, pp. 1487-1516
PAJARES, J, Pascual, J A, Hernandez, C, and Lopez, A (2003) A behavioural, evolutionary and generative framework for modelling financial markets. Presented at the First Conference of the European Social Simulation Association, Groningen, The Netherlands, 18-21 Sept 2003. Conference proceedings available online.
POLHILL, J G, Gotts, N M and Law, A N R (2001), Imitative versus nonimitative strategies in a land use simulation. Cybernetics & Systems 32, pp. 285-307
POLHILL, J G, Izquierdo, L R, and Gotts, N M (2005), The ghost in the model (and other effects of floating point arithmetic). Journal of Artificial Societies and Social Simulation, https://www.jasss.org/
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2005]