
Ron Sun and Isaac Naveh (2004)
Simulating Organizational Decision-Making Using a Cognitively Realistic Agent Model
Journal of Artificial Societies and Social Simulation
vol. 7, no. 3
<https://www.jasss.org/7/3/5.html>
To cite articles published in the Journal of Artificial Societies and Social Simulation, reference the above information and include paragraph numbers if necessary
Received: 14-Nov-2003 Accepted: 01-Apr-2004 Published: 30-Jun-2004
 Abstract
Abstract
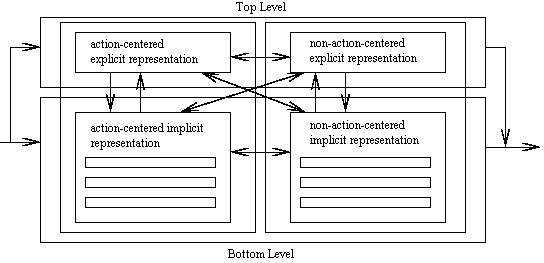
|
| Figure 1. The CLARION architecture |
|
|
where x is the current state, a is one of the actions, r is the immediate feedback, and γmaxb Q(y,b) is set to zero for the organizational design task that was tackled in this paper, because we rely on immediate feedback in this particular task (details below). Δ Q(x, a) provides the error signal needed by the backpropagation algorithm and then backpropagation takes place. That is, learning is based on minimizing the following error at each step:
|
|
where i is the index for an output node representing the action ai. Based on the above error measure, the backpropagation algorithm is applied to adjust internal weights of the network.
|
|
where A and B are two different rule conditions that lead to the same action a, and c1 and c2 are two constants representing the prior (by default, c1 = 1, c2 = 2). Essentially, the measure compares the percentages of positive matches under different conditions A and B.
|
|
where C is the current condition of a rule (matching the current state and action), all refers to the corresponding match-all rule (with the same action as specified by the original rule but an input condition that matches any state), and C' is a modified condition equal to C plus one input value. If the above holds, the new rule will have the condition C' with the highest IG measure. The generalization threshold (denoted thresholdGEN above) determines how readily an agent will generalize a rule.
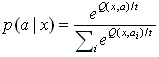
|
where x is the current state, a is an action, and t controls the degree of randomness (temperature) of the process. (This method is also known as Luce's choice axiom (Watkins 1989). It is found to match psychological data in many domains.)
| Table 1: Human and simulation data for the organizational design task. D indicates distributed information access, while B indicates blocked information access. All numbers are percent correct | ||||
| Agent/Org. | Team (B) | Team (D) | Hierarchy (B) | Hierarchy (D) |
| Human | 50.0 | 56.7 | 46.7 | 55.0 |
| Radar-SOAR | 73.3 | 63.3 | 63.3 | 53.3 |
| CORP-P-ELM | 78.3 | 71.7 | 40.0 | 36.7 |
| CORP-ELM | 88.3 | 85.0 | 45.0 | 50.0 |
| CORP-SOP | 81.7 | 85.0 | 81.7 | 85.0 |
| Table 2: Simulation data for agents running for 4,000 cycles. The human data from Carley et al (1998) are reproduced here for ease of comparison. Performance for CLARION is computed as percentage correct over the last 1,000 cycles | ||||
| Agent/Org. | Team (B) | Team (D) | Hierarchy (B) | Hierarchy (D) |
| Human | 50.0 | 56.7 | 46.7 | 55.0 |
| CLARION | 53.2 | 59.3 | 45.0 | 49.4 |
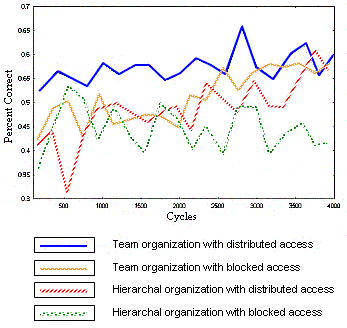
|
| Figure 2. Training curves for different combinations of organizational structure and data access |
|
|
The rule should be read as follows: if input #4 is equal to 1, 2 or 3, and the other inputs are equal to 3, then select action 3 (hostile aircraft).
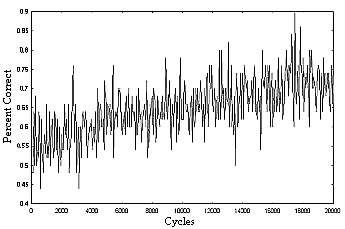
|
| Figure 3. Training curve (team organization, distributed access) |
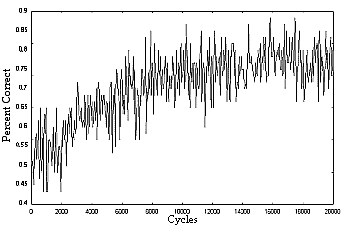
|
| Figure 4. Training curve (team organization, blocked access) |
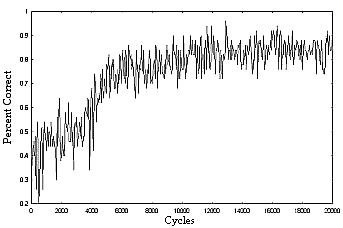
|
| Figure 5. Training curve (hierarchal organization, distributed access) |
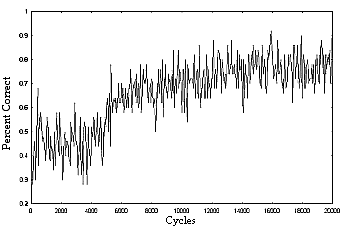
|
| Figure 6. Training curve (hierarchal organization, blocked access) |
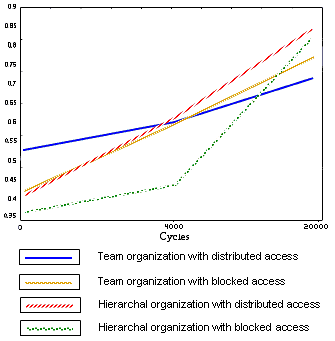
|
| Figure 7. A comparison of performance under different combinations of structure and organization after 100, 4,000 and 20,000 training cycles |
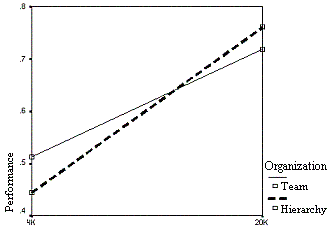
|
| Figure 8. The effect of organization on performance over time |
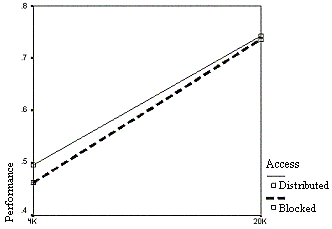
|
| Figure 9. The effect of information access on performance over time |
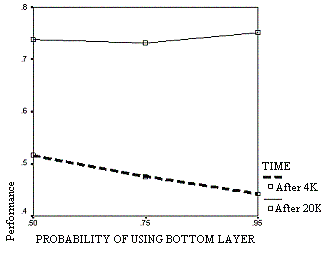
|
| Figure 10. The effect of probability of using the bottom level on performance over time |
|
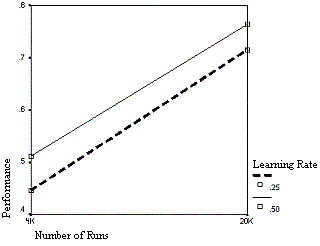
| Figure 11. The effect of learning rate on performance over time |
|
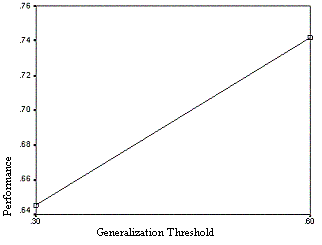
| Figure 12. The effect of generalization threshold on the final performance |
|
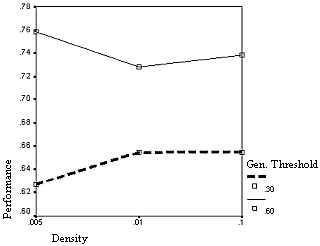
| Figure 13. The interaction of generalization threshold and density with respect to the final performance |
|
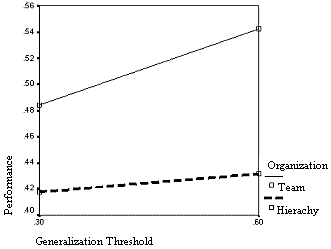
| Figure 14. The interaction of generalization threshold and organization with respect to initial performance |
| Table 3: Simulation results for general parameters of the model. Only statistically significant interactions are shown (for main effects, NS = not significant). Time is computed as a repeated-measures variable at 4,000 and 20,000 cycles | |||
| F | df | p | |
| Effect of probability of bottom level usage (PROB_BL) | 11.73 | 2, 24 | < 0.001 |
| Effect of learning rate | 32.47 | 2, 24 | < 0.001 |
| Effect of temperature | 2.89 | 1, 24 | NS |
| Interaction of PROB_BL and time | 12.37 | 2, 24 | < 0.001 |
| Table 4: Simulation results for parameters related to RER learning | |||
| F | df | p | |
| Effect of RER positivity threshold | .229 | 1, 24 | NS |
| Effect of RER density | .094 | 2, 24 | NS |
| Effect of RER generalization threshold | 15.91 | 1, 24 | < 0.001 |
| Interaction of density and generalization threshold | 2.93 | 2, 24 | < 0.05 |
| Interaction of generalization threshold and organization after 4,000 cycles | 5.93 | 1, 24 | < 0.05 |
2 The following parameters were used for all agents: Temperature = 0.05; Learning Rate = 0.5; Probability of Using Bottom Level = 0.75; RER Positivity Criterion = 0.0; Density = 0.01; Generalization Threshold = 4.0. See Section 2 for a description of the cognitive parameters.
3 If we raise the threshold above a certain point, performance dips and an overall U-shaped curve is observed. The same is true for other parameters.
ANDERSON J R (1993) Rules of the Mind. Hillsdale, NJ: Lawrence Erlbaum Associates.
ANDERSON J R and Lebiere C (1998) The Atomic Components of Thought. Mahwah, NJ: Lawrence Erlbaum Associates.
AXTELL R, Axelrod J and Cohen M (1996) Aligning Simulation Models: A Case Study and Results. Computational and Mathematical Organization Theory, 1(2), pp. 123-141.
BERRY D and Broadbent D (1988) Interactive Tasks and the Implicit-Explicit Distinction. British Journal of Psychology, 79, pp. 251-272.
BEST B J and Lebiere C (2003) Teamwork, Communication, and Planning in ACT-R: Agents Engaging in Urban Combat in Virtual Environments. Proceedings of the IJCAI 2003 Workshop on Cognitive Modeling of Agents and Multi-Agent Interactions (Ron Sun, ed.). Acapulco, Mexico.
BOYER P and Ramble C (2001) Cognitive Templates for Religious Concepts: Cross-Cultural Evidence for Recall of Counter-Intuitive Representations. Cognitive Science, 25, pp. 535-564.
CARLEY K M (1992) Organizational Learning and Personnel Turnover. Organizational Science, 3(1). pp. 20-46.
CARLEY K M and Lin Z (1995) Organizational Designs Suited to High Performance Under Stress. IEEE - Systems Man and Cybernetics, 25(1). pp. 221-230.
CARLEY K M and Prietula M J (1992) Toward a Cognitively Motivated Theory of Organizations. Proceedings of the 1992 Coordination Theory and Collaboration Technology Workshop. Washington D.C.
CARLEY K M, Prietula M J, and Lin Z (1998) Design Versus Cognition: The interaction of agent cognition and organizational design on organizational performance. Journal of Artificial Societies and Social Simulation, 1(3), https://www.jasss.org/1/3/4.html
CARLEY K M and Svoboda D M (1996) Modeling Organizational Adaptation as a Simulated Annealing Process. Sociological Methods and Research, 25(1), pp. 138-168.
CASTELFRANCHI C (2001) The Theory of Social Functions: Challenges for Computational Social Science and Multi-Agent Learning. Cognitive Systems Research, special issue on the multi-disciplinary studies of multi-agent learning (ed. Ron Sun), 2(1), pp. 5-38.
CECCONI F and Parisi D (1998) Individual Versus Social Survival Strategies. Journal of Artificial Societies and Social Simulation, 1(2), https://www.jasss.org/1/2/1.html
COWARD L A and Sun R (in press) Criteria for an Effective Theory of Consciousness and Examples of Preliminary Attempts at Such a Theory. Consciousness and Cognition.
EDMONDS B and Moss S (2001) "The Importance of Representing Cognitive Processes in Multi-Agent Models." In Dorffner G, Bischof H, and Hornik K (Eds.). Artificial Neural Networks--ICANN'2001. Springer-Verlag: Lecture Notes in Computer Science, 2130, pp. 759-766.
GILBERT N and Doran J (1994) Simulating Societies: The Computer Simulation of Social Phenomena. London, UK: UCL Press, London.
GOLDSPINK C (2000) Modeling Social Systems as Complex: Towards a Social Simulation Meta-Model. Journal of Artificial Societies and Social Simulation, 3(2), https://www.jasss.org/3/2/1.html
HUTCHINS E (1995) How a Cockpit Remembers Its Speeds. Cognitive Science, 19, pp. 265-288.
JENSEN F V (1996). An Introduction to Bayesian Networks. NY: Springer-Verlag.
KAHAN J and Rapoport A (1984) Theories of Coalition Formation. Mahwah, NJ: Erlbaum.
KLAHR D, Langley P, and Neches R (eds.) (1987) Production System Models of Learning and Development. Cambridge, MA: MIT Press.
LEVY S (1992) Artificial Life. London: Jonathan Cape.
LOUIE M A, Carley K M, Haghshenass L, Kunz J C, and Levitt R E (2003) Model Comparisons: Docking ORGAHEAD and SimVision. NAACSOS conference proceedings. PA: Pittsburgh.
MAHER M L, Smith G J and Gero J S (2003) Design Agents in 3D Virtual Worlds. Proceedings of the IJCAI 2003 Workshop on Cognitive Modeling of Agents and Multi-Agent Interactions (Ron Sun, ed.). Acapulco, Mexico.
MANDLER J (1992) How to Build a Baby. Psychology Review, 99(4), pp. 587-604.
MOSS S (1999) Relevance, Realism and Rigour: A Third Way for Social and Economic Research. CPM Report No. 99-56. Manchester, UK: Center for Policy Analysis, Manchester Metropolitan University.
PALMERI T J (1997) Exemplar Similarity and the Development of Automaticity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23, pp. 324-354.
PHELAN S and Zhiang Lin (2001) Promotion Systems and Organizational Performance: A Contingency Model. Computational and Mathematical Organization Theory, 7(3), pp. 207-232.
PROCTOR R and Dutta A (1995) Skill Acquisition and Human Performance. Thousand Oaks, CA: Sage Publications.
RABINER L (1989) A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77(2), pp. 257-286.
REBER A (1989) Implicit Learning and Tacit Knowledge. Journal of Experimental Psychology: General, 118(3), pp. 219-235.
ROSENBLOOM P, Laird J, Newell A, and McCarl R (1991) A preliminary analysis of the SOAR architecture as a basis for general intelligence. Artificial Intelligence, 47(1-3), pp. 289-325.
RUMELHART D and McClelland J (Eds.) (1986) Parallel Distributed Processing I. Cambridge, MA: MIT Press.
SCHACTER D (1990) Toward a Cognitive Neuropsychology of Awareness: Implicit Knowledge and Anosagnosia. Journal of Clinical and Experimental Neuropsychology, 12(1), pp. 155-178.
SEGER C (1994) Implicit Learning. Psychological Bulletin, 115(2). pp. 163-196.
SMITH J D and Minda J P (1998) Prototypes in the Mist: The Early Epochs of Category Learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, pp. 1411-1436.
SMOLENSKY P (1988) On the Proper Treatment of Connectionism. Behavioral and Brain Sciences, 11(1), pp. 1-74.
STADLER M and Frensch P (1998) Handbook of Implicit Learning. Thousand Oaks, CA: Sage Publications.
STANLEY W, Mathews R, Buss R, and Kotler-Cope S (1989) Insight Without Awareness: On the Interaction of Verbalization, Instruction and Practice in a Simulated Process Control Task. Quarterly Journal of Experimental Psychology, 41A(3), pp. 553-577.
SUN R (1995) Robust Reasoning: Integrating Rule-Based and Similarity-Based Reasoning. Artificial Intelligence, 75(2), pp. 241-296.
SUN R (1997) Learning, Action, and Consciousness: A Hybrid Approach Towards Modeling Consciousness. Neural Networks, special issue on consciousness, 10(7), pp. 1317-1331.
SUN R (2001) Cognitive Science Meets Multi-Agent Systems: A Prolegomenon. Philosophical Psychology, 14(1), pp. 5-28.
SUN R (2002) Duality of the Mind. Mahwah, NJ: Lawrence Erlbaum Associates.
SUN R, Merrill E, and Peterson T (1998) A Bottom-Up Model of Skill Learning. Proceedings of 20th Cognitive Science Society Conference, pp. 1037-1042. Mahwah, NJ: Lawrence Erlbaum Associates.
SUN R, Merrill E, and Peterson T (2001) From Implicit Skills to Explicit Knowledge: A Bottom-Up Model of Skill Learning. Cognitive Science, 25(2), pp. 203-244.
SUN R and Peterson T (1998) Autonomous Learning of Sequential Tasks: Experiments and Analyses. IEEE Transactions on Neural Networks, 9(6), pp. 1217-1234.
TAKADAMA K, Suematsu Y L, Sugimoto N, Nawa N E, and Shimohara K (2003) Cross-Element Validation in Multiagent-Based Simulation: Switching Learning Mechanisms in Agents. Journal of Artificial Societies and Social Simulation, 6(4), https://www.jasss.org/6/4/6.html
WATKINS C (1989) Learning with Delayed Rewards. PhD Thesis, Cambridge University, Cambridge, UK.
WEST R L, Lebiere C, and Bothell D J (2003) Cognitive Architectures, Game Playing, and Interactive Agents. Proceedings of the IJCAI 2003 Workshop on Cognitive Modeling of Agents and Multi-Agent Interactions (Ron Sun, ed.). Acapulco, Mexico.
WILLINGHAM D, Nissen M and Bullemer P (1989) On the Development of Procedural Knowledge. Journal of Experimental Psychology: Learning, Memory and Cognition, 15, pp. 1047-1060.
YE M and Carley K M (1995) Radar-Soar: Towards An Artificial Organization Composed of Intelligent Agents. Journal of Mathematical Sociology, 20(2-3), pp. 219-246.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2004]