
Keiki Takadama, Yutaka L. Suematsu, Norikazu Sugimoto, Norberto E. Nawa and Katsunori Shimohara (2003)
Cross-Element Validation in Multiagent-based Simulation: Switching Learning Mechanisms in Agents
Journal of Artificial Societies and Social Simulation
vol. 6, no. 4
To cite articles published in the Journal of Artificial Societies and Social Simulation, please reference the above information and include paragraph numbers if necessary
<https://www.jasss.org/6/4/6.html>
Received: 13-Jul-2003 Accepted: 13-Jul-2003 Published: 31-Oct-2003
 Abstract
Abstract
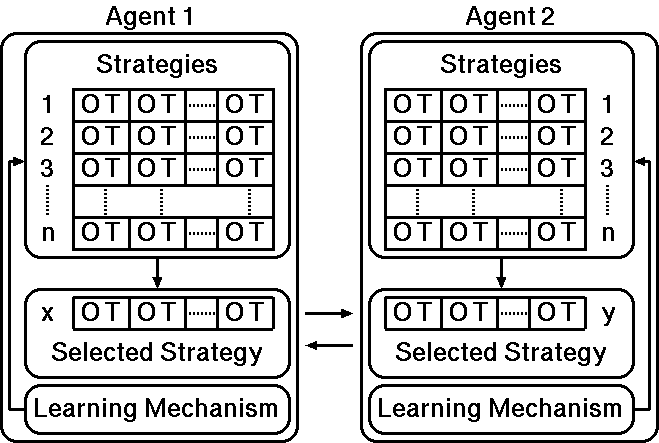
Figure 1. ES- and LCS-based agents
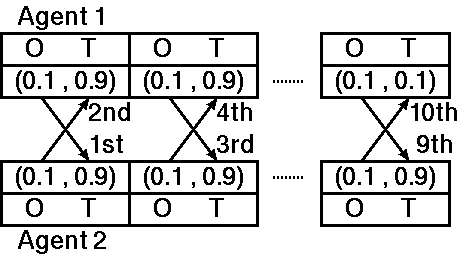
Figure 2. Example of a negotiation process (ES- and LCS-based agents)
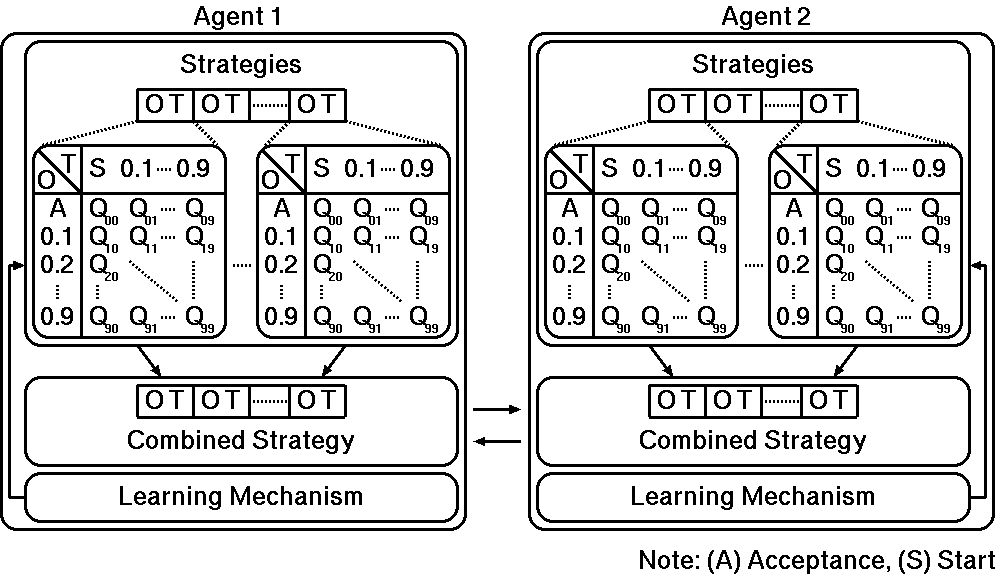
Figure 3. RL-based agents
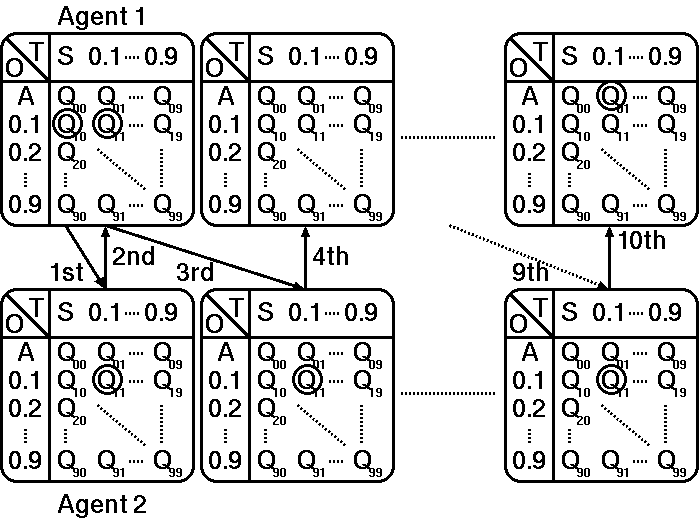
Figure 4. Example of a negotiation process (RL-based agents)
Q(t,o)=Q(t,o)+&alpha[r+&gamma maxo'&isin O(t') Q(t',o')-Q(t,o)] .... (1)
Table 1. Parameters in simulations
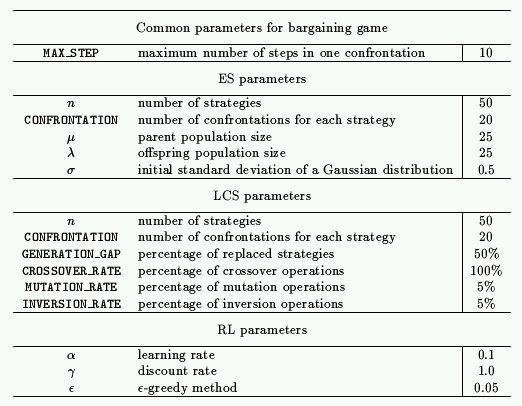
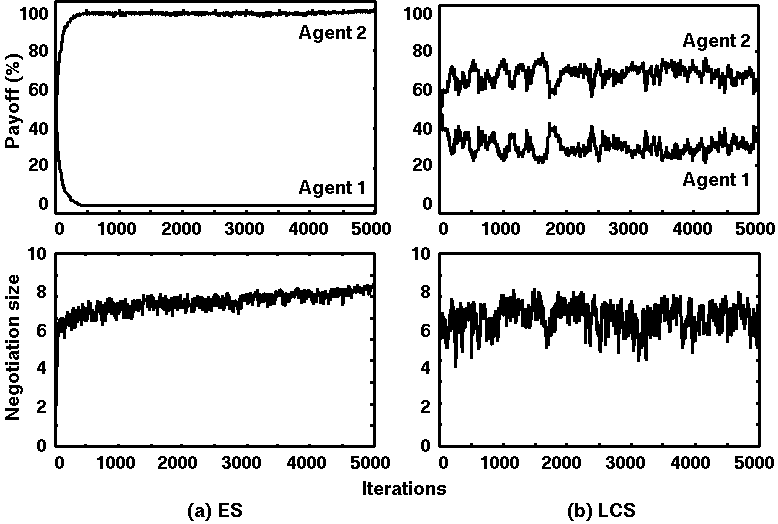
Figure 5. Simulation results of ES vs. LCS:
Average values over 10 runs at 5000 iterations
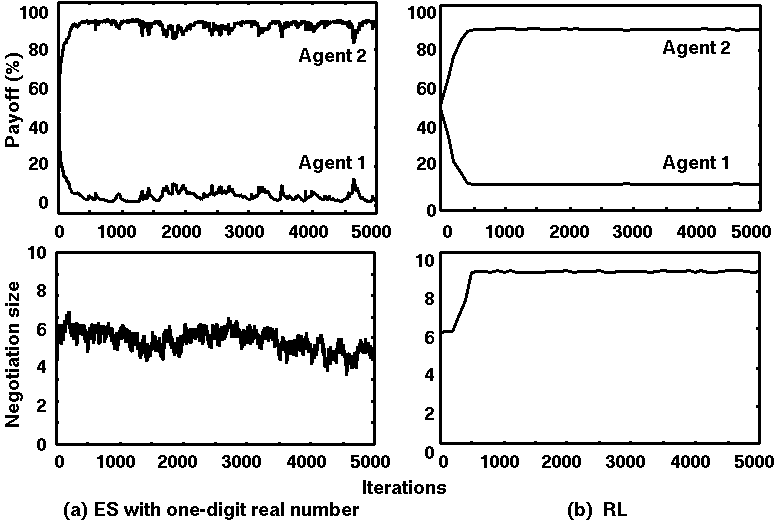
Figure 6. Simulation results of ES with one decimal digit vs. RL:
Average values over 10 runs at 5000 iterations
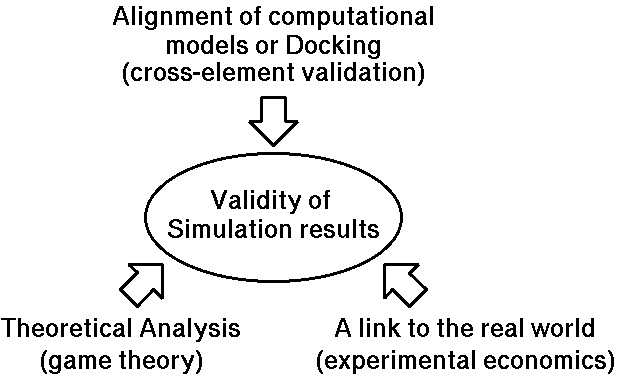
Figure 7. Three approaches to the validity of simulation results
ARTHUR, W. B., Holland, J. H., Palmer, R., and Tayler, P. (1997), "Asset Pricing Under Endogenous Expectations in an Artificial Stock Market," in W. B. Arthur, S. N. Durlauf, and D. A. Lane (Eds.), The Economy as an Evolving Complex System II, Addison-Wesley, pp. 15-44.
AXELROD, R. M. (1997), The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration, Princeton University Press.
AXTELL, R., Axelrod, R., Epstein J., and Cohen, M. D. (1996), "Aligning Simulation Models: A Case Study and Results," Computational and Mathematical Organization Theory (CMOT), Vol. 1, No. 1, pp. 123-141.
BÄCK, T., Rudolph, G., and Schwefel, H. (1992), "Evolutionary Programming and Evolution Strategies: Similarities and Differences," The 2nd Annual Evolutionary Programming Conference, pp. 11-22.
BINMORE, K., Shaked. A., and Sutton, J. (1985), "Testing Non-cooperative Bargaining Theory: A Preliminary Study," American Economic Review, Vol. 75, No. 5, pp. 1178-1180.
BINMORE, K., Shaked, A., and Sutton, J. (1988), "A Further Test of Noncooperative Bargaining Theory: Reply," American Economic Review, Vol. 78, No. 4, pp. 837-839.
BURTON, R. M. and Obel, B. (1995), "The Validity of Computational Modes in Organization Science: From Model Realism to Purpose of the Model," Computational and Mathematical Organization Theory (CMOT), Vol. 1, No. 1, pp. 57-71.
CARLEY, K. M. and Svoboda, D. M. (1996), "Modeling Organizational Adaptation as a Simulated Annealing Process," Sociological Methods and Research, Vol. 25, No. 1, pp. 138-168.
CARLEY, K. M. and Gasser, L. (1999), "Computational and Organization Theory," in Weiss, G. (Ed.), Multiagent Systems - Modern Approach to Distributed Artificial Intelligence -, The MIT Press, pp. 299-330.
DEGUCHI, H. (2003), "Economics as Complex Systems," Springer, to appear.
EPSTEIN, J. M. and Axtell, R. (1996), Growing Artificial Societies, MIT Press.
FRIEDMAN, D. and Sunder, S. (1994), Experimental Methods: A Primer for Economists, Cambridge University Press.
GOLDBERG, D. E. (1989), Genetic Algorithms in Search, Optimization, and Machine Learning, Addison-Wesley.
GÜTH, W., Schmittberger, R., and Schwarze, B. (1982), "An Experimental Analysis of Ultimatum Bargaining," Journal of Economic Behavior and Organization, Vol. 3, pp. 367-388.
HAGHSHENASS, L., Levitt, R. E., Kunz, J. C., Mahalingam, A., and Zolin, R. (2002), "A Study on the Comparison of VDT and ORGAHEAD," The CASOS (Computational Analysis of Social and Organizational System) Conference 2002.
HOLLAND, J. H. (1975), Adaptation in Natural and Artificial Systems, University of Michigan Press.
HOLLAND, J. H., Holyoak, K. J., Nisbett, R. E., and Thagard, P. R. (1986), Induction, The MIT Press.
KAGEL, J. H. and Roth, A. E. (1995), Handbook of Experimental Economics Princeton University Press.
LEVITT, R. E., Cohen, G. P., Kunz, J. C., Nass, C. I., Chirstiansen, T. R., and Jin, Y. (1994), "The Virtual Design Team: Simulating How Organization Structure and Information Processing Tools Affect Team Performance", in K. M. Carley and J. Prietula (Eds.): Computational Organization Theory, Lawlence-Erlbaum Assoc., pp. 1-18.
LOUIE, M. A., Carley, K. M., Levitt, R. E., Kunz, J. C., and Mahalingam, A. (2002), "Docking the Virtual Design Team and ORGAHEAD," The CASOS (Computational Analysis of Social and Organizational System) Conference 2002.
MOSS, S. and Davidsson, P. (2001), Multi-Agent-Based Simulation, Lecture Notes in Artificial Intelligence, Vol. 1979, Springer-Verlag.
MUTHOO, A. (1999), Bargaining Theory with Applications , Cambridge University Press.
MUTHOO, A. (2000), "A Non-Technical Introduction to Bargaining Theory," World Economics, pp. 145-166.
NEELIN, J., Sonnenschein, H., and Spiegel, M. (1988), "A Further Test of Noncooperative Bargaining Theory: Comment," American Economic Review, Vol. 78, No. 4, pp. 824-836.
NYDEGGER, R. V. and Owen, G. (1974), "Two-Person Bargaining: An Experimental Test of the Nash Axioms," International Journal of Game Theory, Vol. 3, No. 4, pp. 239-249.
OLIVER, J. R. (1996), "On Artificial Agents for Negotiation in Electronic Commerce," Ph.D. Thesis, University of Pennsylvania.
OSBORNE, M. J. and Rubinstein, A. (1994), A Course in Game Theory, MIT Press.
ROTH, A. E., Prasnikar, V., Okuno-Fujiwara, M., and Zamir, S. (1991), "Bargaining and Market Behavior in Jerusalem, Ljubljana, Pittsburgh, and Tokyo: An Experimental Study," American Economic Review, Vol. 81, No. 5, pp. 1068-1094.
RUBINSTEIN, A. (1982), "Perfect Equilibrium in a Bargaining Model," Econometrica, Vol. 50, No. 1, pp. 97-109.
SMITH, S. F. (1983), "Flexible Learning of Problem Solving Heuristics through Adaptive Search," The 8th International Joint Conference on Artificial Intelligence (IJCAI '83), pp. 422-425.
Ståhl, I. (1972), Bargaining Theory, Economics Research Institute at the Stockholm School of Economics.
SUTTON, R. S. and Bart, A. G. (1998), Reinforcement Learning - An Introduction -, The MIT Press.
TAKADAMA, K. and Shimohara, K. (2002), "The Hare and The Tortoise - Cumulative Progress in Agent-Based Simulation -," in A. Namatame, T. Terano, and K. Kurumatani (Eds.), Agent-based Approaches in Economic and Social Complex Systems, The IOS Press, pp. 3-14.
TAKADAMA, K., Sugimoto, N., Nawa, N. E., and Shimohara, K. (2003), "Grounding to Both Theory and Real World by Agent-Based Simulation: Analyzing Learning Agents in Bargaining Game," NAACSOS (North American Association for Computational Social and Organizational Science) Conference 2003 .
WATKINS, C. J. C. H. and Dayan, P. (1992), "Technical Note: Q-Learning," Machine Learning, Vol. 8, pp. 55-68.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2003]