
Thomas Brenner (2001)
Simulating the Evolution of Localised Industrial Clusters - An Identification of the Basic Mechanisms
Journal of Artificial Societies and Social Simulation
vol. 4, no. 3,
To cite articles published in the Journal of Artificial Societies and Social Simulation, please reference the above information and include paragraph numbers if necessary
<https://www.jasss.org/4/3/4.html>
Received: 13-Oct-00 Accepted: 29-May-01 Published: 30-Jun-01
| Table 1: Influence of several local circumstances on the state of firms | |||||||
| human capital | spillovers | co-operation | synergies | public opinion | local policies | Venture Capital | |
| innovation | a qualified labour force is more innovative | create innovation and increases diffusion | joint R&D leads to more innovation | - | - | - | - |
| productivity | qualified labour is more productive | - | joint projects increase productivity | mutually increase productivity | - | support for firms increases their producti-vity | - |
| start-up | qualified people are more likely to found a firm | - | - | - | a positive expectation increases the number of start-ups | - | start-ups require venture capital |
|
|
| (2.1) |
where kq denotes the share of experienced labour force (or human capital) that is available in the region; au (0 < au < 1), the productivity of inexperienced labour divided by the productivity of experienced labour; Cp,qn(t) the co-operative activities; Mqn(t) the mutual profits of firms in the region; Pqn(t) the political support (the dynamics of these aspects will be discussed below); and α-βLn(t) determines whether there are economies of scale. α < 1 is assumed, so that there are never diseconomies of scales for very small sizes of firms. However, if firms increase in size diseconomies might develop (dependent on the value of β). This reflects the fact that the dependence of the production costs on the size of a firm is usually found to be s-shaped.
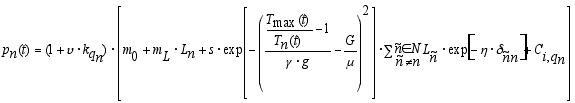
|
| (2.2) |
v (>0) is a parameter that determines the increase of the innovativeness of firms due to a higher human capital. s (>0) is a parameter that denotes the strength of the influence that spillovers from other firms have on the innovativeness of a firm. Furthermore, spillovers are assumed to be highest if the technological gap between the technology of the firm and the most advanced technology Tmax(t) used by some other firm equals G (> 0). Firms are assumed to profit most from spillovers if they are technologically behind by an amount of G. If the quotient Tmax(t)/Tn(t) is less or more than G the effect of spillovers decreases. gu (>0) determines how much the spillovers decrease for other technological gaps (this aspect of the modelling is taken from Caniëls 1999). In addition, the effect of spillovers decreases with the spatial distance δñn between the firms. η (>0) determines the strength of this effect. The distance between two firms is given by
| δñn={[(xqñ - xqn)2 + (yqñ - yqn) 2]} |
| (2.3) |
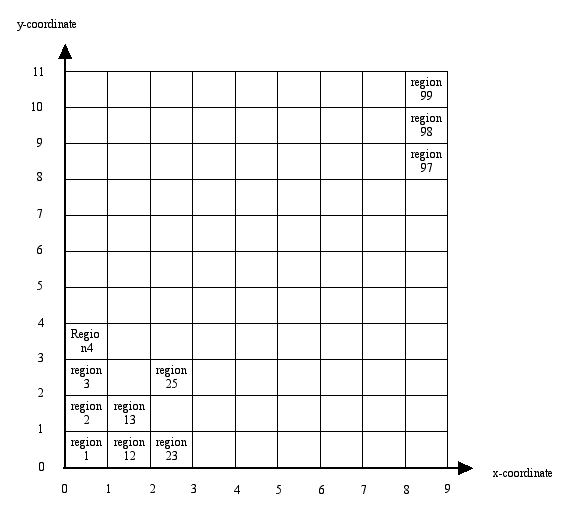
where xq denotes the x-coordinate of region q and yq its y-coordinate (coordinates are taken in the middle of a region). In the simulations the regions are assumed to be located as given in Figure 1.
|
| Figure 1. Location of the 99 regions |
| Tn(t+1) = (1+γ) Tn(t) |
| (2.4) |
|
|
| (2.5) |
where Lq(t) denotes the employment of all firms in region q. The dynamics of Kq(t), Vq(t) and Fq(t) are given below. The technology used by a start-up firm equals the average technology used by all existing firms. The initial technology of the first firm is set to 1. The initial number of employment is randomly determined. It ranges between zero and Linit.
|
|
| (2.6) |
where φ (>0) is a parameter. Spin-offs are often located near to the firm in which the founder has worked before. In this approach it is assumed that the likelihood for the spin-off firm to be located in a certain region decreases exponentially with the distance from the originating firm. The probability for the spin-off firm ñ to be located in region q is given by
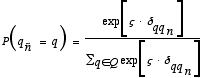
|
| (2.7) |
where δqqn is defined analogously to δnñ (see Equation (2.3)) and ςς(>0) is a parameter that characterises the geographical stickiness of spin-offs.
|
|
| (2.8) |
where D (>0), b (>0) and ρ (>0) are parameters. For a constant wage and interest rate, the production costs are proportional to the inverse productivity. Assuming that firms use markup-pricing, their price is also proportional to the inverse productivity. Thus, the productivity might be used in the demand function as it is done in Equation (2.8). The last term on the right-hand side of Equation (2.8) represents the impact that other firms have on the demand faced by firm n. Yñ(t) denotes the sales of firm ñ at time t. These sales reduce the demand for the products of firm n by ρρ Yñ(t) . Thus, ρ denotes the heterogeneity of the goods. For ρ = 0 the goods are completely different and the demand for the product of one firm does not depend on the behaviour of other firms. If ρ = 1, the goods are identical and an increase of sales by one firm does automatically mean a decrease by the same amount of sales of other firms. All firms are assumed to supply the same market, so that the location of firms does not influence the demand for its products.
|
|
| (2.9) |
|
|
| (2.10) |
where N(t) is the number of firms at time t. This equation looks quite similar to the demand function that is usually applied in oligopoly theory (one might redefine the parameters such that the equation looks more convenient). The only real difference is the dependence on the number of firms N(t) which has to be explicitly considered here because this number changes over time endogenously. In the simulations Equation (2.8) is used to calculate the demand for each firm.
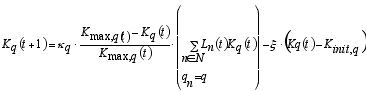
|
| (2.11) |
where κq (>0) is a parameter that denotes the speed of the accumulation of human capital.
|
|
| (2.12) |
where Iq(t) is the opinion in the population of region q with respect to the industry. The dynamics of Iq(t) are given below.
|
|
| (2.13) |
|
|
| (2.14) |
|
|
| (2.15) |
φ (>0) is a parameter that determines the speed of learning about the advantages of co-operation.
|
|
| (2.16) |
where µ (>0) represents the overall effect of synergies and χ (>0) determines the local stickiness of synergies.
|
|
| (2.17) |
where fm (0<fm<1) is a parameter that determines the decay of the memory about founding and close down events. The opinion Fq(t) of the local population with respect to founding a firm influences the number of start-ups and spin-offs as modelled in the Equations (2.5) and (2.6).
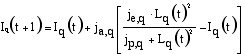
|
| (2.18) |
ja,q, je,q and jp,q are parameters of the region q. For small numbers of employees the dependence has a quadratic form. This reflects the aspect that industries are only recognised if they reach a certain level of employment. For larger numbers the opinion levels off, meaning that it is not able to increase above je,q which denotes the maximal effect of this aspect. Furthermore, the public opinion is assumed not to reach this value immediately, but to slowly develop in the direction of this value. The opinion about an industry influences the maximal human capital in a region according to Equation (2.12).
|
|
| (2.19) |
where Lpol (>0) is a parameter. Pq(t) influences the productivity of all firms of the industry in region q according to Equation (2.1).
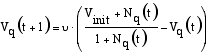
|
| (2.20) |
where v (>0) is a parameter and Nq(t) is the number of firms in the considered industry in region q. If the number of firms is very high, the value of Vq(t) converges to one. If, instead, no firm of the considered industry is located in region q, the value of Vq(t) converges to Vinit. The speed with which the availability of venture capital adapts to a new situation is given by v.
| Table 2: The ranges for all parameters of the model | ||||||
| Parameter | lower bound | upper bound | parameter | lower bound | upper bound | |
| Linit | 2 | 30 | g | 0 | 10 | |
| α | 1 | 1.3 | η | 0 | 4 | |
| β | 0 | 0.01 | cc | 0 | 0.1 | |
| D | 10000 | 500000 | φφ | 0.00001 | 0.1 | |
| B | 0 | D | pmax,c | 0.00001 | 0.1 | |
| ρ | 0.7 | 1 | ca | 0.0003 | 0.02 | |
| λ | 0.00001 | 0.003 | ac | 0.00001 | 0.01 | |
| εq | 0.00003 | 0.05 | mc | 0.00001 | 0.01 | |
| φ | 0.000003 | 10/D | µ | 0.00001 | 0.01 | |
| ς | 0 | 4 | χ | 0 | 4 | |
| Kinit | 0 | 50 | ja,q | 0.000001 | 0.1 | |
| Kmax,q | 50 | 10000 | je,q | 0.001 | 5 | |
| κq | 0.001 | 0.03 | jp,q | 50 | 10000 | |
| ξ | 0.00004 | 0.002 | f + | 0 | 0.01 | |
| au | 0 | 1 | f - | 0 | 0.02 | |
| γγ | 0.000001 | 0.1 | fm | 0.001 | 0.1 | |
| M0 | 0.0003 | 0.03 | Lpol | 50 | 10000 | |
| ML | 0.0000015 | 0.00003 | π | 0.00001 | 0.1 | |
| S | 0.0000015 | 0.00003 | Vinit | 0.01 | 1 | |
| G | 1 | 100 | v | 0.000001 | 0.01 | |
 after 20 years, the gini-coefficient g for the geographic distribution of employment after 20 years (see Krugman 1991afor a detailed discussion of the gini-coefficient and its calculation), the correlations C1, C2 and C3 between on the one hand the distribution after 5 years (1800 simulation steps), 10 years (3600 simulation steps) and 15 years (5400 simulation steps) and on the other hand the distribution after 20 years (7200 simulation steps). The correlation variables contain some information about the convergence of the processes. Correlation variables of about 1 imply that there are nearly no changes of the firm and employment distribution during the last 15 years of a simulation. This means that the processes have already converged to the final state after 5 years. If, instead, the correlation variables are all approximately zero, no convergence has occurred within the first 15 years of simulation. In addition to these four variables a corrected gini-coefficient
after 20 years, the gini-coefficient g for the geographic distribution of employment after 20 years (see Krugman 1991afor a detailed discussion of the gini-coefficient and its calculation), the correlations C1, C2 and C3 between on the one hand the distribution after 5 years (1800 simulation steps), 10 years (3600 simulation steps) and 15 years (5400 simulation steps) and on the other hand the distribution after 20 years (7200 simulation steps). The correlation variables contain some information about the convergence of the processes. Correlation variables of about 1 imply that there are nearly no changes of the firm and employment distribution during the last 15 years of a simulation. This means that the processes have already converged to the final state after 5 years. If, instead, the correlation variables are all approximately zero, no convergence has occurred within the first 15 years of simulation. In addition to these four variables a corrected gini-coefficient 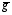 is defined. The gini-coefficient that is defined in the literature does not take in the account the total number of firms that are distributed in space. If there is a huge number of firms, the gini-coefficient can take any value between 0 and 0.49495. If, instead, there are only two firms, the gini-coefficient is always greater than 0.48989. Thus, if the number of firms increases due to the variation of a parameter, the value of the gini-coefficient should be expected to decrease. Such a decrease would not imply that the geographic concentration of the industry decreases, but might be the result of the higher number of firms. The corrected gini-coefficient is defined such that it takes into account this fact. For each number of firms the gini-coefficient
is defined. The gini-coefficient that is defined in the literature does not take in the account the total number of firms that are distributed in space. If there is a huge number of firms, the gini-coefficient can take any value between 0 and 0.49495. If, instead, there are only two firms, the gini-coefficient is always greater than 0.48989. Thus, if the number of firms increases due to the variation of a parameter, the value of the gini-coefficient should be expected to decrease. Such a decrease would not imply that the geographic concentration of the industry decreases, but might be the result of the higher number of firms. The corrected gini-coefficient is defined such that it takes into account this fact. For each number of firms the gini-coefficient 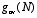 can be calculated for a random distribution of N firms of equal size between the 99 regions. is defined as
can be calculated for a random distribution of N firms of equal size between the 99 regions. is defined as
|
|
| (3.1) |
is one if all firms are located in the same region and zero if the firms are randomly distributed over the regions. For a uniform distribution becomes negative. These characteristics hold independent of the number of firms.
, g, Ci (C1, C2 and C3 generally lead to the same results, so that the average for these three variable is given below), and is calculated, using regression analysis. This analysis identifies all linear impacts. For each parameter 20 such analyses are conducted for different values of all other parameters. Then, it is calculated how often the studied parameter has a significant positive or significant negative impact on each of the variables. The results are given in the Tables 3 and 4.
| Table 3: Influences of the parameters on the variables that characterise the result of the simulation runs. The first value of each entry in the table denotes the number of runs in which significant (significance level: 0,01) positive impact is found. The second value denotes the number of runs in which a significant (significance level: 0,01) negative impact is found. | ||||||
| parameter | runs | N | | g | Ci | |
| Linit | 20 | 8/3 | 8/3 | 5/5 | 1/4,7 | 6/4 |
| α | 20 | 2/10 | 6/6 | 7/4 | 3/0,7 | 5/5 |
| β | 20 | 10/- | 2/4 | 1/7 | 0,7/2,7 | 1/5 |
| D | 20 | 8/- | 11/- | 1/7 | 3/2 | 1/- |
| b | 20 | -/1 | 2/1 | -/1 | 0,3/0,3 | -/1 |
| ρ | 20 | -/4 | 1/6 | 3/- | -/2,3 | 2/1 |
| λ | 20 | 2/10 | 13/1 | 15/- | 3,3/1 | 10/- |
| εq | 20 | 18/- | 13/- | -/17 | 2/7,3 | 1/12 |
| Φ | 20 | 13/- | 8/5 | 2/5 | 0,7/5,3 | 7/1 |
| ζ | 20 | 2/5 | 1/4 | 12/- | 3,7/- | 11/- |
| Kinit,q | 20 | 6/1 | 3/2 | -/7 | 0,3/3,7 | -/7 |
| Kmaxq | 20 | 4/5 | 5/3 | 10/1 | 5,3/0,3 | 10/- |
| κq | 20 | 3/5 | 5/6 | 8/2 | 5/1,7 | 8/2 |
| ξ | 20 | 2/4 | 3/4 | 3/2 | 0,3/1,3 | 1/2 |
| au | 20 | 4/2 | 9/2 | 3/5 | 2,3/2,7 | 4/5 |
| γ | 20 | 1/3 | -/6 | 8/- | 1,3/2,3 | 9/- |
| m0 | 20 | -/2 | -/3 | -/- | -/1 | -/- |
| mL | 20 | 2/3 | -/3 | 4/- | 1,3/- | 4/1 |
| s | 20 | -/1 | -/- | 1/- | 0,7/- | 1/- |
| g | 20 | -/- | -/- | -/- | 0,3/0,3 | -/- |
| G | 20 | -/1 | -/1 | 1/- | 0,3/- | -/- |
| η | 20 | -/- | -/- | -/- | -/- | -/- |
the impact of the parameters is analysed in more detail in the next section.
| Table 4: Influences of the parameters on the variables that characterise the results of the simulation runs. The first value of each entry in the table denotes the number of runs in which a significant (significance level: 0.01) positive impact is found. The second value denotes the number of runs in which a significant (significance level: 0.01) negative impact is found. | ||||||
| parameter | runs | N | | g | Ci | |
| cc | 20 | -/3 | -/7 | 9/- | 2/0,3 | 8/- |
| φ | 20 | -/- | -/- | -/- | -/- | -/1 |
| pmax,c | 20 | 1/- | 1/- | -/1 | -/0,3 | -/- |
| ca | 20 | 2/- | 1/2 | -/2 | 1,3/0,3 | -/2 |
| ac | 20 | 3/1 | 3/3 | 4/- | 0,7/1,3 | 4/- |
| mc | 20 | -/1 | -/- | -/- | -/- | 1/- |
| µ | 20 | 1/1 | 2/1 | 6/- | 1/0,7 | 6/- |
| χ | 20 | 2/- | 3/2 | 2/1 | 1/0,3 | 2/1 |
| ja,q | 20 | -/1 | -/1 | 1/- | 1/- | -/- |
| je,q | 20 | -/1 | -/1 | 1/1 | 0,3/- | 1/1 |
| jp,q | 20 | -/- | -/- | -/- | 0,7/- | -/- |
| f+ | 20 | -/- | -/- | -/- | -/- | -/- |
| f- | 20 | -/- | -/- | -/- | -/0,3 | -/1 |
| fm | 20 | 1/- | -/1 | -/1 | 1/- | -/- |
| Lpol | 20 | -/- | -/1 | 1/- | -/- | -/- |
| π | 20 | 2/1 | 1/1 | 3/- | 0,3/- | 2/- |
| Vinit | 20 | 14/- | 8/- | -/12 | 1/6 | 1/11 |
| v | 20 | 10/- | 9/- | 1/5 | -/1,7 | 5/2 |
2 Of course, this statement in principle only holds if an infinite number of random sets is chosen. However, the more sets of parameters are chosen, the more reliable is the obtained result.
ALLEN, P. M. (1997A). Cities and Regions as Evolutionary, Complex Systems. Geographical Systems 4, 103-130.
ALLEN, P. M. (1997B). Cities and Regions as Self-Organizing Systems. Models of Complexity. Amsterdam: Gordon and Breach.
ALMUS, M., ENGEL, D. & NERLINGER, E. A. (1999). Determinanten des Beschäftigungswachstums junger Unternehmen in den alten und neuen Bundesländern: Bestehen Unterschiede hinsichtlich der Technologieorientierung?. Zeitschrift für Wirtschafts- und Sozialwissenschaften 119, 561-592.
ANSELIN, L., VARGA, A. & ACS, Z. (1997). Local Geographic Spillovers between University Research and High Technology Innovations. Journal of Urban Economics 42, 422-448.
AUDRETSCH, D. B. (1998). Agglomeration and the Location of Innovative Activity. Oxford Review of Economic Policy 14, 18-29.
AUDRETSCH, D. B. & FRITSCH, M. (1999). The Industry Component of Regional New Firm Formation Processes. Review of Industrial Organization 15, 239-252.
BECATTINI, G. (1990). The Marshallian Industrial District as a Socio-economic Notion. In: (Pyke, F., Becattini, G. and Sengenberger, W., Eds.) Industrial Districts and Inter-firm Co-operation in Italy, pp. 37-51. Geneva: International Institute for Labour Studies.
BLIND, K. & GRUPP, H. (1999). Interdependencies between the Science and Technology Infrastructure and Innovation Activities in German Regions: Empirical Findings and Policy Consequences. Research Policy 28, 451-468.
BRENNER, T. (2000). The Evolution of Localised Industrial Clusters: Identifying the Processes of Self-organisation. Papers on Economics & Evolution #0011, Max-Planck-Institute Jena.
Brenner, T. & Fornahl, D. (2001). Theoretische Erkenntnisse zur Entstehung und Erzeugung `innovativer Regionen´. mimeo, Max-Planck-Institute Jena.
Brenner, T. & Weigelt, N. (2001). The Evolution of Industrial Clusters - Simulating Spatial Dynamics. Advances in Complex Systems 3, (forthcomming). CAMAGNI, R. P. (1995). The Concept of Innovative Milieu and Its Relevance for Public Policies in European Lagging Regions. Papers in Regional Science 74, 317-340.
CAMAGNI, R. P. & DIAPPI, L. (1991). A Supply-oriented Urban Dynamics Model with Innovation and Synergy Effects. In: (Boyce, D. E., Nijkamp, P. and Shefer, D. ,Eds.) Regional Science, pp. 339-357. Berlin: Springer-Verlag.
CANIËLS, M. (1999). Regional Growth Differentials. Maastricht: Dissertation.
CANIËLS, M. C. J. AND VERSPAGEN, B. (1999). Spatial Distance in a Technology Gap Model. Working Paper 99.10, Eindhoven Centre for Innovation Studies.
DALUM, B. (1995). Local and Global Linkages: The Radiocommunications Cluster in Northern Denmark. mimeo, Aalborg University.
DEI OTTATI, G. (1994). Cooperation and Competition in the Industrial District as an Organisation Model. European Planning Studies 2, 463-483.
ELLISON, G. AND GLAESER, E. L. (1994). Geographic Concentration in U.S. Manufacturing Industies: A Dartboard Approach. Working Paper No. 4840, National Bureau of Economic Research.
FRITSCH, M., BRÖSKAMP, A. & SCHWIRTEN, C. (1996). Innovationen in der sächsischen Industrie - Erste empirische Ergebnisse. Freiberg Working Papers 96/13, Technical University Bergakademie Freiberg.
JAFFE, A.B., TRAJTENBERG, M. AND HENDERSON, R. (1993). Geographic Localization of Knowledge Spillovers as Evidenced by Patent Citations. Quarterly Journal of Economics 79, 577-598.
JONARD, N. AND YILDIZOGLU, M. (1998). Technological Diversity in an Evolutionary Industry Model with Localized Learning and Network Externalities. Structural Change and Economic Dynamics 9, 35-53.
KRUGMAN, P. (1991A). Geography and Trade. Cambridge: MIT Press.
KRUGMAN, P. (1991B). Increasing Returns and Economic Geography. Journal of Political Economy 99, 483-499.
LAWSON, C (1997). Territorial Clustering and High-Technology Innovation: From Industrial Districts to Innovative Milieux. Working Paper No. 54, ESRC Centre for Business Research, University of Cambridge
MAILLAT, D. (1998). From the Industrial District to the Innovative Milieu: Contribution to an Analysis of Territorialised Productive Organisations. Recherches Economiques de Louvain 64, 111-129.
MAILLAT, D. AND LECOQ, B. (1992). New Technologies and Transformation of Regional Structures in Europe: The Role of the Milieu. Entrepreneurship & Regional Development 4, 1-20.
MARKUSEN, A. (1996). Sticky Places in Slippery Space: A Typology of Industrial Districts. Economic Geography 72, 293-313.
PYKE, F. AND SENGENBERGER, W., EDS (1992). Industrial Districts and Local Economic Regeneration. Geneva: International Institute for Labour Studies.
RABELLOTTI, R. (1997). External Economies and Cooperation in Industrial Districts. Houndmills: Macmillan Press Ltd.
ROSEGRANT, S. AND LAMPE, D. R. (1992). Route 128. Basic Books.
SAXENIAN, A.-L. (1994). Regional Advantage. Cambridge: Harvard University Press.
SCHULENBURG, J.-M. & WAGNER, J. (1991). Advertising, Innovation and Market Structure: A Comparison of the United States of America and the Federal Republic of Germany. In: (Acs, Z.J. and Audretsch, D.B., Eds.) Innovation and Technological Change, pp. 160-182. New York: Harvester Wheatsheaf.
SCHWEITZER, F. (1998). Modelling Migration and Economic Agglomeration with Active Brownian Particles. adv. complex systems 1, 11-37.
SCOTT, A. J. (1992). The Role of Large Producers in Industrial Districts: A Case Study of High Technology Systems Houses in Southern California. Regional Studies 26, 265-275.
SENGENBERGER, W. & PYKE, F. (1992). Industrial Districts and Local Economic Regeneration: Research and Policy Issues. In: (Pyke, F. and Sengenberger, W., Eds.) Industrial Districts and Local Economic Regeneration. Geneva: International Institute for Labour Studies.
VAN DIJK, M. P. (1995). Flexible Specialisation, The New Competition and Industrial Districts. Small Business Economics 7, 15-27.
VERSPAGEN, B. & SCHOENMAKERS, W. (2000). The Spatial Dimension of Knowledge Spillovers in Europe: Evidence from Firm Patenting Data. mimeo, ECIS and MERIT.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, 2001