
Resolving a Replication That Failed: News on the Macy & Sato Model
Journal of Artificial Societies and Social Simulation
12 (4) 11
<https://www.jasss.org/12/4/11.html>
For information about citing this article, click here
Received: 29-Aug-2009 Accepted: 27-Sep-2009 Published: 31-Oct-2009

 Abstract
Abstract
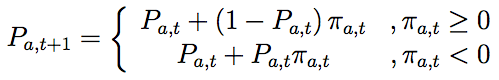
|
(2) |
where Pa,t is the current probability of deciding in a certain way a, e.g. to defect, πa,t is the payoff gained by that behaviour, e.g. -0.2 in mutual defection, and Pa,t+1 is the probability to decide for the same action a in the next time step.[6]
|
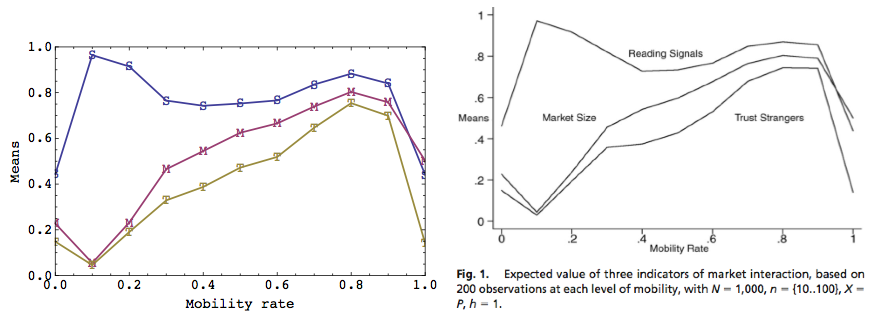
| Figure 1. Plots of data from replicated (left) and original model (right). |
|
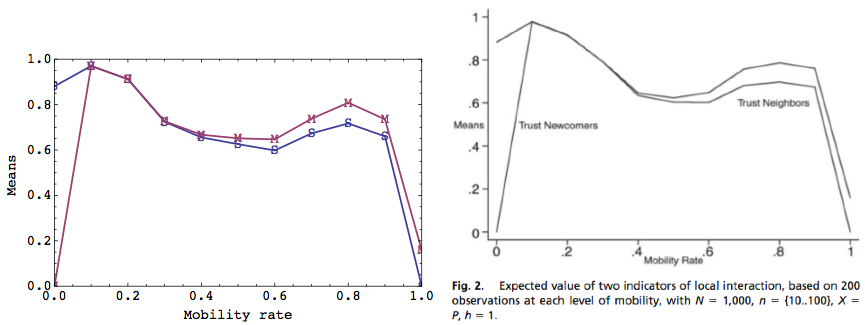
| Figure 2. Plots of data from replicated (left) and original model (right). |
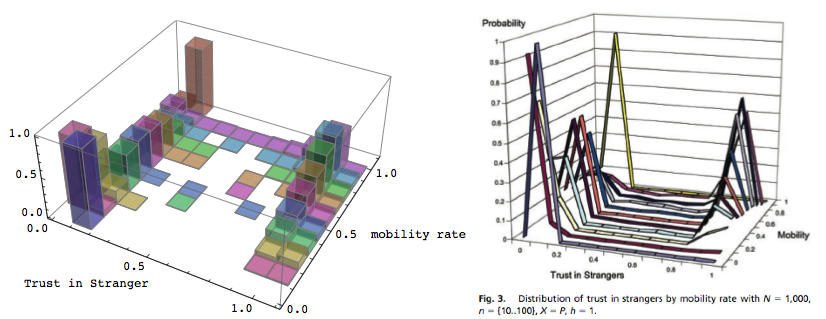
|
| Figure 3. Plots of data from replicated (left) and original model (right). |
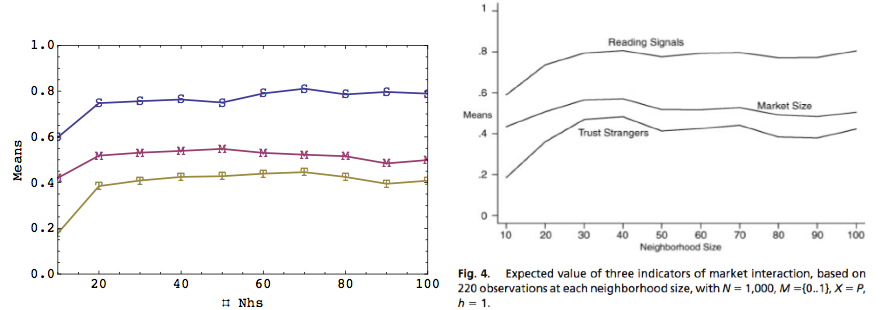
|
| Figure 4. Plots of data from replicated (left) and original model (right). |
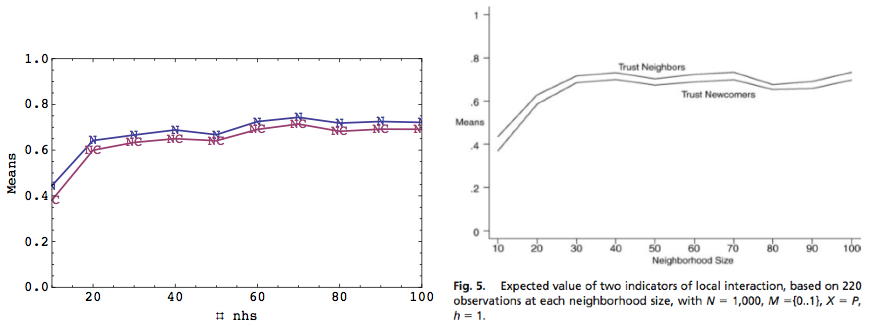
|
| Figure 5. Plots of data from replicated (left) and original model (right). |
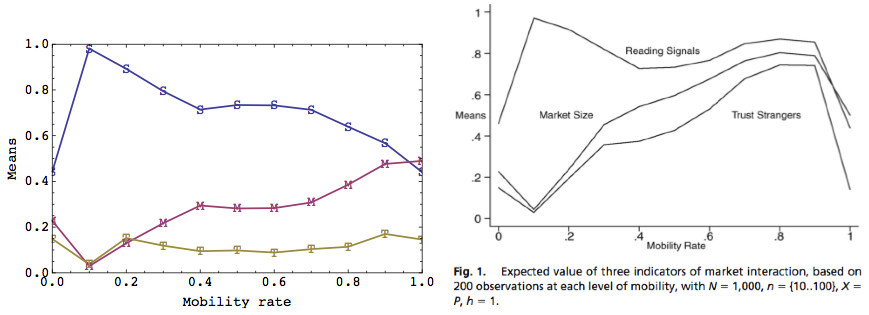
|
| Figure 6. Plots of data from "corrected" (left) and original model (right). |
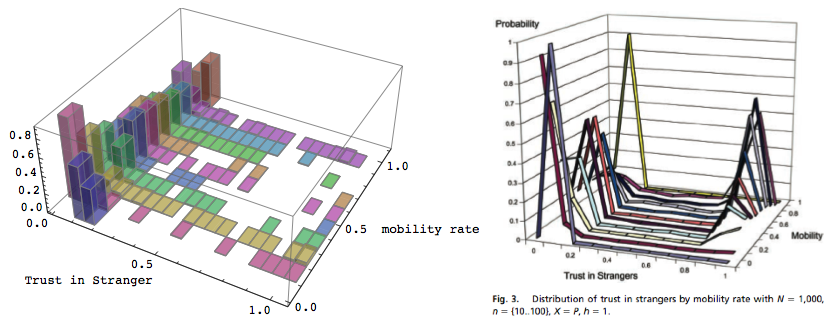
|
| Figure 7. Plots of data from "corrected" (left) and original model (right). |
2 This is a minor difference to our former repplication since in Will and Hegselmann (2008a) our variation of N was more fine-grained. E.g., to get an average neighbourhood size of 30, we conducted 7 runs with 34 neighbourhoods and the remaining 13 with 33 instead of taking 33 neighbourhoods in all 20 repetitions.
3 This is equivalent to the signalling mechanism suggested in Will and Hegselmann (2008a).
4 I use the standard notation here: If one agents defects and the other cooperates, the defector gains a payoff given by T(emptation) and the cooperator one given by S(ucker). In case of mutual cooperation both gain the R(reward payoff) and if both defect they receive the P(unishment) outcome.
5 In Will and Hegselmann (2008a) we assumed that newcomers can be role models.
6 In Will and Hegselmann (2008a) we assumed that all agents that have a partner learn either by social or reinforcement learning and that both options are equally likely.
7 The variables are named "PropMktN" and "PropMktS" in the source code. Line 492 shows their application.
8 Line 348 of the source code.
9 Line 753 of the source code. Here, you also find a note, that the distinction should be eliminated.
10 Here is a description of what the values in the figures mean. The exact definition of each value was extracted from the source code of Macy and Sato's model.
11Not only were the parameters the same but I also used the same random seeds to initialise the model.
12Note that this modified model produces results that are not only different from those in Macy and Sato's article but also from those of the very first replication in Will and Hegselmann (2008a). Theses differences are mainly due to further differences concerning the learning algorithm mentioned in footnotes [5] and [6]. The model's high sensitivity to small modifications of the learning algorithm will be adressed in future work.
13See for example van de Rijt, Siegel and Macy (2009).
MACY, M and Sato Y (2008). 'Reply to Will and Hegselmann'. Journal of Artificial Societies and Social Simulation 11 (4) 11 https://www.jasss.org/11/4/11.html.
VAN DE RIJT, A, Siegel, D and Macy, M (2009). 'Neighborhood Chance and Neighborhood Change: A Comment on Bruch and Mare'. American Journal of Sociology 114, 4, pp. 1166-80.
WILL, O and Hegselmann, R (2008a). 'A Replication That Failed — on the Computational Model in 'Michael W. Macy and Yoshimichi Sato: Trust, Cooperation and Market Formation in the U.S. and Japan. Proceedings of the National Academy of Sciences, May 2002''. Journal of Artificial Societies and Social Simulation 11 (3) 3 https://www.jasss.org/11/3/3.html.
WILL, O and Hegselmann, R (2008b). 'Remark on a Reply'. Journal of Artificial Societies and Social Simulation 11 (4) 13 https://www.jasss.org/11/4/13.html.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2009]