
Simulating Light-Weight Personalised Recommender Systems in Learning Networks: a Case for Pedagogy-Oriented and Rating-Based Hybrid Recommendation Strategies
Journal of Artificial Societies and Social Simulation
vol. 12, no. 1 4
<https://www.jasss.org/12/1/4.html>
For information about citing this article, click here
Received: 01-Apr-2008 Accepted: 11-Aug-2008 Published: 31-Jan-2009

 Abstract
AbstractWhat RS and which limited set of LA-characteristics and learners' characteristics is needed in a light-weight hybrid PRS to enable sound recommendations within LNs, and which behaviour minimally needs to be traced?
What RS and which limited set of LA-characteristics and learners' characteristics is needed in a light-weight hybrid PRS to enable sound recommendations within LNs, and which behaviour minimally needs to be traced?
H1: PRS recommendations yield more, more satisfied, and faster graduation than no recommendations
H2: ontology-based and rating-based recommendations from PRS show no differences for graduation, nor satisfaction, nor time to graduate.
|
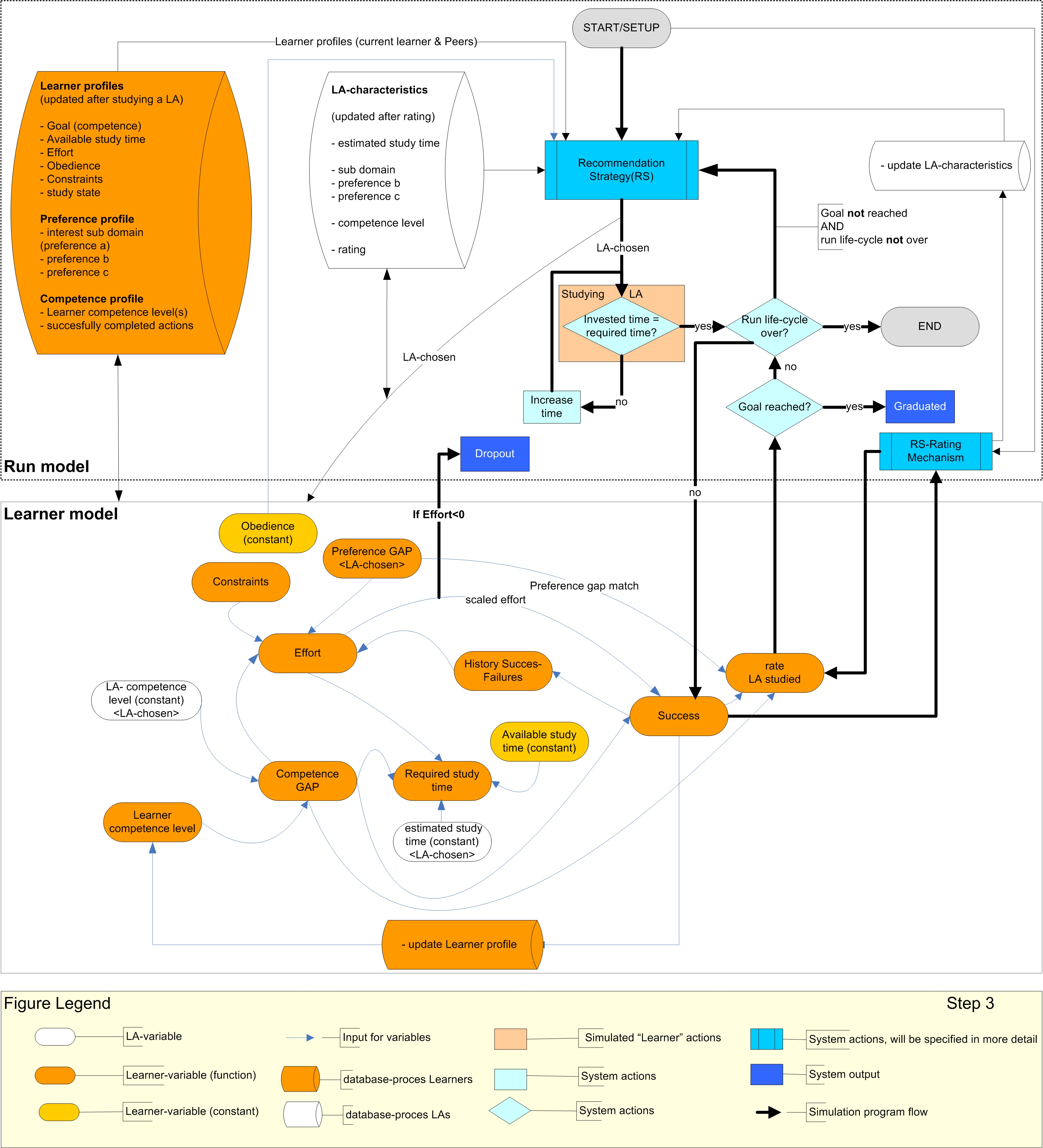
| Figure 1. Conceptual simulation model and simulation program flow. Details about Recommendation Strategy (RS) are included in Figures 2a, b. Details about Setup are presented in Figure 3. |
[Available study time] has the same magnitude as the simulation tick time (1 tick = 1 week).
[Effort] is initially normally distributed amongst learners, but changes during study (see Table 2). Effort is the key variable which determines dropout (Ryan and Deci 2000). If Effort gets below zero, a learner will drop out the LN and will not graduate. Effort depends on previous effort, [Preference GAP], [Competence GAP], [Constraints] and [History of Success/Failures] (abbreviated as: History) on the last three LA examinations.
The [Preference GAP] measures alignment between learners' preferences and corresponding LA-characteristics. The smaller the gap, the better the alignment.
The [Competence GAP] measures alignment between [Learner competence level] and the [LA-competence level] of the LA-chosen. A perfect match occurs if [LA-competence level] is one level above [Learner competence level] (Vygotsky 1978). Please note that [Learner competence level] is a variable with a specific value at a certain point of time, whereas [LA-competence level] is a constant. Mismatches for preferences and/or competences will decrease effort, whereas better matches or preferably perfect matches will increase effort.
[Constraints] (like fatigue, being in the flow, a noisy or quiet or study room, stress) can influence the amount of effort learners want to invest when studying. Constraints are randomized at each studied LA. For calculation purposes, we define constraints as '1' in case of positive effects, '-1' in case of negative effects, and '0' in case of a neutral effect. As constraints are considered to be a multidimensional construct, a more fine grained approach could be used. For the sake of simplicity, we have conceived these constraints to be a one-dimensional construct.
[History] also affects [Effort]. Several successes in a row is expected to increase effort (more motivated), whereas successive failure will be detrimental to learner's effort, and ultimately could result in drop out.
[Obedience] differs between learners but remains constant for each learner. Obedience is similar to predictive utility that measures influences of system predictions upon users' willingness whether or not 'consuming' an item (i.e., obeying the recommendation) (Konstan et al. 1997; Walker et al. 2004). Predictive utility depends upon the domain in which the recommender system is used, and is a function of the value of the predictions, the cost of consuming items, and the ratio of desirable/undesirable items. In an earlier study we identified an obedience level of 60 % (Drachsler et al. 2008) which is similar to other studies (Bolman et al. 2007; Cranen 2007).
[Required study time] is the time a learner invests before doing an LA-examination. If a competence GAP occurs, a learner needs more (in case of knowledge deficiency) or less time (in case of knowledge surplus) than the [estimated study time] of the LA-chosen. Required study time is used in the simulation variable [required time]: the quotient of required study time and simulation tick time.
If [Success] is true, the learner passes LA-examination and achievement of the learner competence level corresponding with the LA competence level and goal will improve. If the studied LA is too far above the learners' current Learner competence level (in other words, there is a very huge competence GAP), it does not matter how much effort the learner invest, it will always lead to failing this LA-examination. However, for LA's that normally would be somewhat beyond learners' scope of possibilities, more effort can lead to their successful completion.
Except for [rating], all LA-characteristics remain unchanged. Learners' rating of a LA ([rate LA-studied]) is influenced by whether or not the learner successfully completes this LA, the [Preference gapmatch], and the [Competence GAP]. [Preference gapmatch] is a coarser variable than [Preference GAP] and has only two values. It is 0 in case of a perfect match if all learner preferences are the same as corresponding LA-characteristics, whereas a value of -1 indicates that one or more learner preferences are different from their corresponding LA-characteristics.
| Table 1: Overview variables in conceptual simulation model and their implementation within the simulation | ||||
| Variable | Description | Implementation in simulation | Input for | |
| Range (initialization) | Formula | |||
| Learner profile | ------ | ----------- | n.a. | RS |
| - goal | competence level(s) | in set up, same for all, allows 3 levels and needed number of LAs | no | |
| - available study time | ------ | M = 20 hours/week, SD = 5 (Normally-distributed) | no | required study time |
| - effort (and scaled effort) | investment to study | M = 10 , SD = 3 (Normally-distributed) | yes | Success/dropout, rst |
| - obedience | follow up recommendation | M = .6, SD = .15 (Normally-distributed) | no | RS |
| - constraints | fatigue, flow, stress, a.s.o. | [-1, 0, 1] (Randomized) for each studied LA | no | effort |
| - preference profile | ------ | ------------ | n.a. | |
| - preference a (interest sub domain) | ------ | number of sub domains, in setup (Randomized) | no | preference GAP |
| - preference b | ------ | [b1, b2, b3] (Randomized) | no | preference GAP |
| - preference c | ------ | [c1, c2, c3] (Randomized) | no | preference GAP |
| - competence profile | ------ | ------------- | n.a. | |
| - learner competence level (s) (LCL) | goal accomplishment | 0, updated if number of successfully completed LAs matches level | yes | competence GAP |
| - successfully completed LAs | contribution towards goal | an integer for each applicable level in the goal | yes | competence level |
| - study state | [studying (in progress), graduated, dropout] | dropout, graduated | ||
| LA characteristics - estimated study time - sub domain (flavour a) - preference b (flavour b) - preference c (flavour c) - competence level (CL) - rating | ------ ------ ------ ------ ------ ------ perceived usefulness after studying | --------- 100 hours for each LA number of sub domains in setup (Randomized) [b1, b2, b3] (Randomized) [c1, c2, c3] (Randomized) same as level(s) in goal, in setup (Randomized) 'missing', updated after each completion, integer [1, 5] | n.a. no no no no no yes | RS required study time preference GAP preference GAP preference GAP competence GAP RS |
| - preference GAP - Preference gapmatch | alignment preferences and flavours alignment preferences and flavours | Integer [-3, 0] Integer [-1, 0], more coarse as 'preference GAP', [-3, 0] → [-1,0] | yes | effort rate LA studied |
| - competence GAP | alignment learner competence level (LCL) and CL of LA | Integer [-2, 2] | yes | effort, rate LA studied, Success, required study time |
| - required study time (rst) | invested time before LA-examination | [50, 100, 150] | yes | Studying LA |
| - Success | learner passes or fails LA-examination | Boolean | yes | rate LA studied, LCL |
| Table 2: Formulas and descriptions for all variables with changing values in conceptual simulation model | |||
| Variable | Description | Formula in simulation | Input for |
| Learner profile - effort (and scaled effort) | investment to study and satisfaction during study | Effort = PE + SUM (w1*PG, w2*G(CG), w3*Constraints, w4*History Success/Failures) - PE= Previous Effort; PG = Preference GAP; CG = Competence GAP - w1=w2=w3=w4=1 (all weighting values); PG: -3, -2, -1, 0; CG: -2, -1, 0, 1, 2 - G(CG): G(-2)=-1, G(-1)=1, G(0)=0, G(1)=-1, G(2)=-2,→ output [-2, 1] - Constraints: -1, 0, 1 - History Success/Failures (abbreviated as: History) for each LA: -1, 0, 1 →, output [-3, 3] Effort is scaled in order to be able to deal with different weighting values for its input variables (all being 1 for this study) and is scaled for calculating Success: Scaled Effort (SE). IF 0≤ Effort < 7 → Scaled Effort = 1; IF 7≤ Effort ≤ 13 → Scaled Effort = 2; IF 14 ≤ Effort ≤ 20 → Scaled Effort = 3 | Success, dropout, required study time (rst) |
| Learner profile - competence profile - learner competence level (s) - successfully completed LAs | goal accomplishment contribution towards goal | A specific LA competence level is mastered if the number of successfully completed LAs with a specific LA competence level matches the corresponding definition in the goal (specified at the setup). The number of successfully completed LAs for a specific LA competence level is stored within 'successfully completed LAs'. | competence GAP |
| LA characteristics - rating (updated each time this LA is studied) | perceived usefulness after studying | Rating = [w3*previous LA-rating + w1*G (individual rating) + w2*H(CF-rating)]/[w1+w2+w3] - w1 = 0.25, w2 = 0.25, w3 = 0.5; w1+w2+w3 = 1 - previous LA-rating = average rating for all learners having studied this LA so far - CF-rating = average rating for ad-hoc group-members to which the current learner belongs when completing this LA (using Slope One Algorithm by Lemire and Maclachlan (2005)). - individual rating = [J(Success) + K(Preference gapmatch) + L(Competence GAP)]/[10] - J(0)=25, J(1)=35 - K(-1)= -7.5, K(0)= 7.5 - L(-2)= -7.5, L(-1)=0, L(0)=L(1)= 7.5, L(2)= -7.5 - individual rating (i.e., Rate LA studied): 1, 2, 3, 4, 5 (Note: 5 for successfully completed, preference GAP is 0, and CG=0 or 1) - H([CF-rating]) → 1, 2, 3, 4, 5 (CF-rating (average) should be round off) | RS |
| - preference GAP - Preference gapmatch | alignment preferences and flavours | Preference GAP = - SUM ((Learner preference(xi) - (LA preference(xi)), i = 1, 2, 3 Learner preference(xi) - LA preference(xi) = 1 if Learner preference(xi) ≠ LA preference(xi) Learner preference(xi) - LA preference(xi) = 0 if Learner preference(xi) = LA preference(xi) The SUM is 0 if the preference GAP is 0, indicating that there is a perfect match. For calculation purposes (in effort) we use negative values if there is no perfect match. | effort rate LA studied |
| - competence GAP | alignment competence level of learner and competence level of LA | Competence GAP = (Learner competence level - LA competence level) +1
Learner competence level: 0, 1, 2 LA competence level: 1, 2, 3 For calculation purposes a symmetric distribution of competence GAP with integers ranging from [-2, 2] was preferred. Therefore, a perfect match results in a competence GAP of 0. | effort, rate LA studied, Success, required study time |
| - required study time (rst) | invested time before LA-examination | rst= FSA* ((1 + H(CG)*) LA Estudy time)
- FSA = Factor Scaled Effort: FSA= 0.8 if SE = 3, FSA= 1.0 if SE = 2, FSA= 1.2 if SE = 1 - Estudy time = estimated study time; - H(CG) is a function with competence GAP (CG) as input - H(CG) = 0,5 if CG = -3, -2; H(CG) = 0 if CG = -1, 0 ; H(CG)= -0.5 if CG = 1, 2 A learner needs to invest 50% more time in case of knowledge deficiency (CG=-2) and 50% less time in case of a knowledge surplus (CG= 1 or 2). The required study time is in line with the LA estimated study time if the learner has adequate prior knowledge (CG=-1, or 0). | studying LA |
| - Success | learner passes or fails LA-examination | Success = Scaled Effort + H(CG) - CG= Competence GAP; - Scaled Effort: 1, 2, 3 - H(CG): H(-2)=-2, H(-1)=0, H(0)=0, H(1)=0, H(2)=0 → output [-2, 0] The learner successfully completes a LA if Succes ≥ 0, otherwise the LA examination fails. | rate LA studied, learner competence level |
Graduation. Learners will dropout if their effort falls below zero and when they consequently fail to reach their goal. Reaching their goal equals graduating. Identifying effectiveness of the RS from PRS will be based upon the percentage of learners reaching their goal (Graduates). A higher percentage of graduates indicates more effectiveness.
Satisfaction.Satisfaction is measured when learners achieve their goal. We suppose that a higher proportion with maximum satisfaction at goal completion indicates that they are more satisfied at graduation than a lower proportion with maximum satisfaction at graduation. Learners' willingness to voluntary invest a certain effort to study is here regarded to be similar to satisfaction.
Time to graduate. Learners reaching their goal within the LN graduate. The impact of RS from PRS on time efficiency is determined by identifying learners' total study time for achieving their goal: time to graduate. The less time to graduate, the more time efficient.
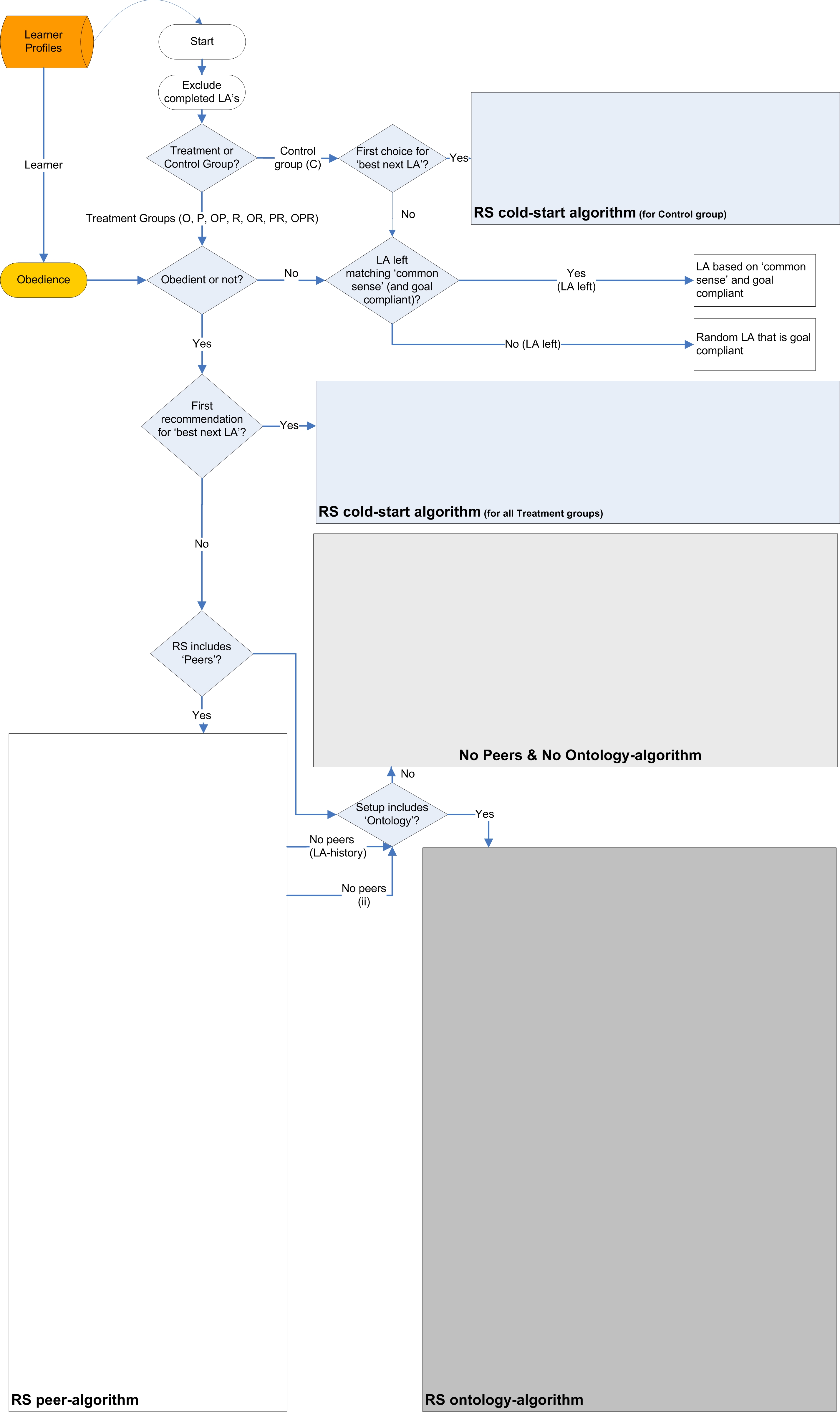
|
| Figure 2a. Recommendation Strategy (RS) for the simulation program. See Figure 2b for more detail |
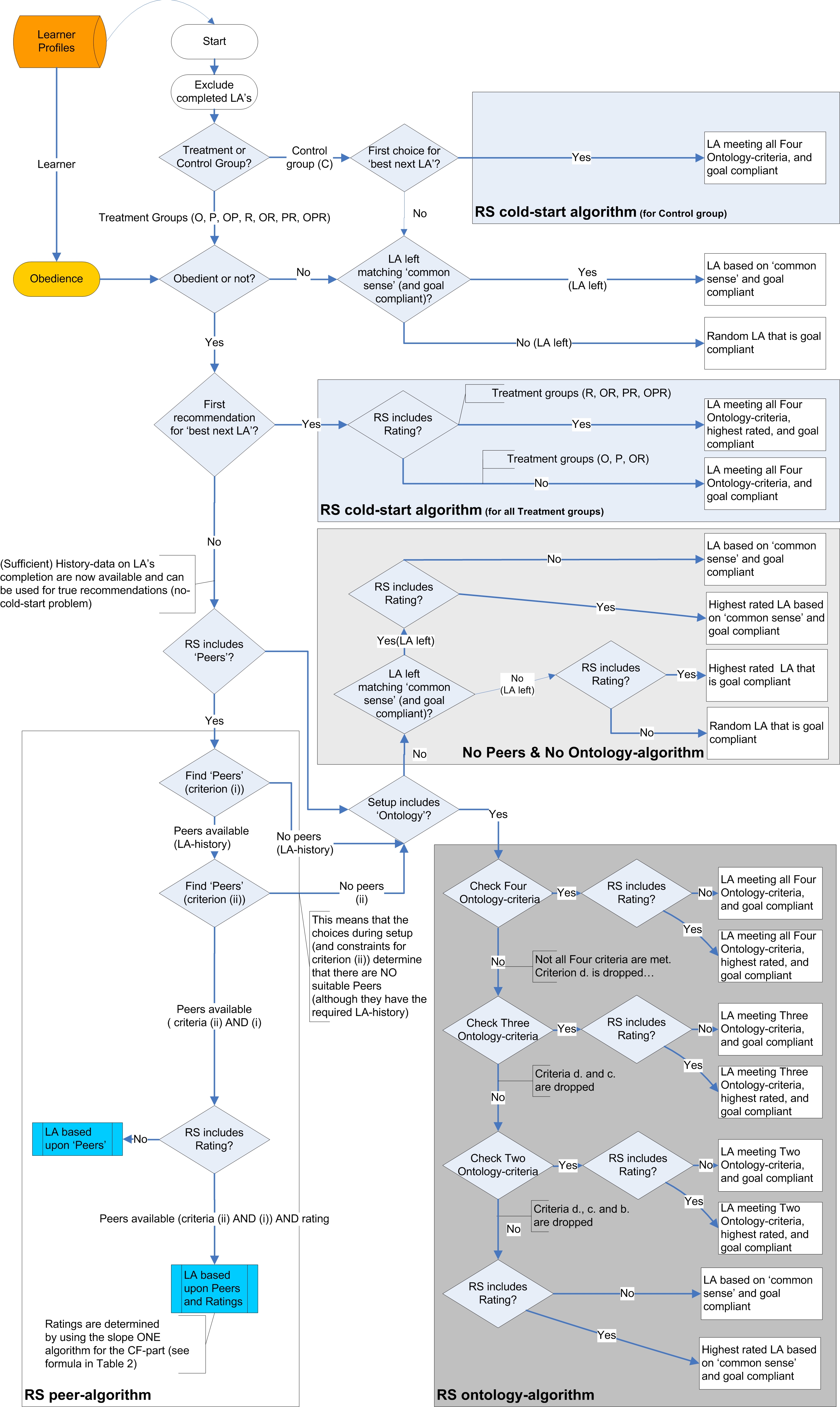
|
| Figure 2b. Recommendation Strategy (RS) for the simulation program in detail |
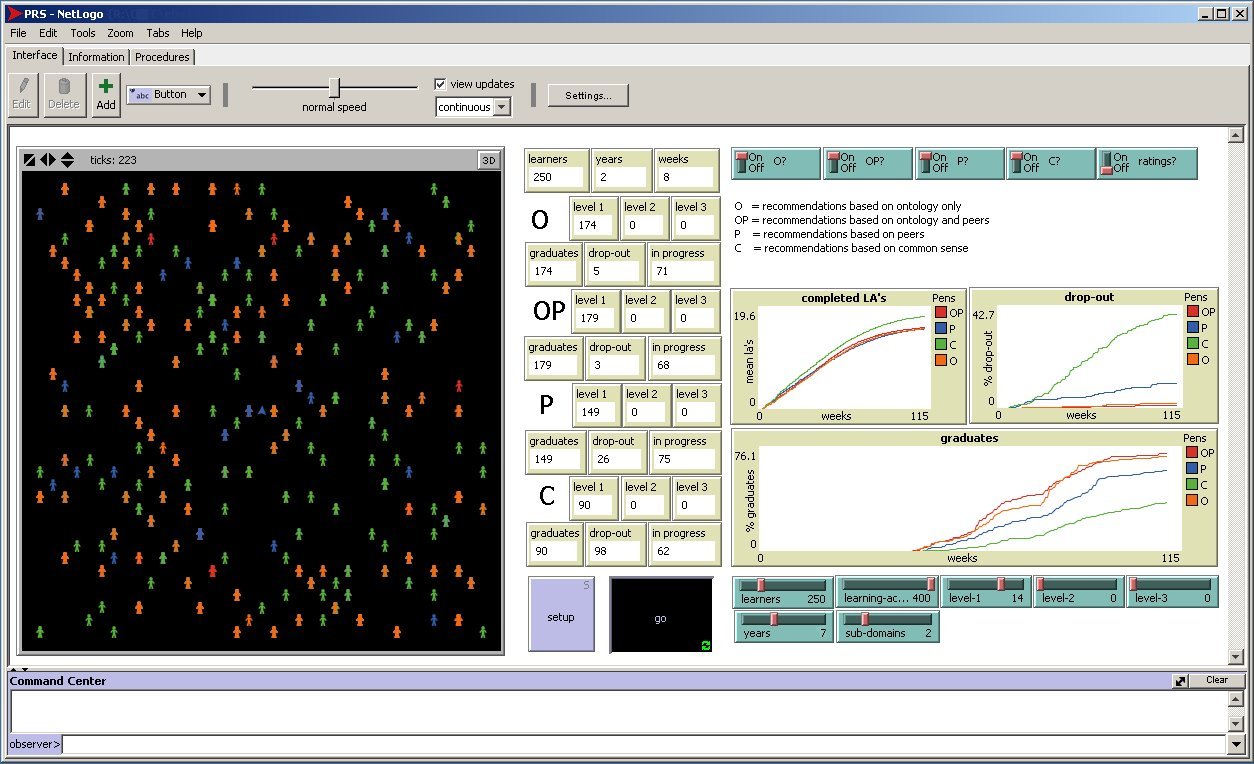
|
| Figure 3. Screenshot of the simulation in Netlogo. Level-1 goal: 14 LAs level-1, 2 sub domains, 400 LAs, 250 learners for each group, run length 7 years: 2 years and 8 weeks are passed. Treatment 'O' then has 174 graduates, 5 drop outs, and 71 participants still studying (in progress) |
| Table 3: Graduation, satisfaction, time to graduate for a goal including one level (similar to Bachelor). With cold-start algorithm | |||||||||||||||||
| # sub domains | Variables | Treatment | No treatment | ||||||||||||||
| Ontology (O) | Peers (P) | Ratings (R) | OP | OR | PR | OPR | Control (C) | ||||||||||
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | ||
| 2 | Graduates | ||||||||||||||||
| - percentage | 92.9 | 2.2 | 70.5 | 2.7 | 94.5 | 1.3 | 88.2 | 2.7 | 93.5 | 1.6 | 79.2 | 3.3 | 91.1 | 2.5 | 20.2 | 4.3 | |
| - perc. max. satisf. | 47.3 | 3.5 | 9.1 | 1.9 | 42.9 | 3.1 | 23.1 | 3.1 | 49.0 | 3.4 | 17.9 | 2.5 | 32.7 | 3.1 | 3.3 | 3.0 | |
| - time | 1658 | 362 | 1823 | 364 | 1530 | 258 | 1665 | 339 | 1650 | 355 | 1781 | 366 | 1641 | 350 | 2264 | 393 | |
| 3 | Graduates | ||||||||||||||||
| - percentage | 91.1 | 2.4 | 65.8 | 5.1 | 93.9 | 1.3 | 84.5 | 1.7 | 91.8 | 1.9 | 73.5 | 3.9 | 88.7 | 1.5 | 17.4 | 3.9 | |
| - perc. max. satisf | 39.2 | 4.0 | 6.6 | 2.0 | 33.3 | 3.1 | 16.7 | 3.0 | 37.7 | 2.4 | 13.4 | 3.1 | 24.5 | 2.4 | 2.5 | 1.3 | |
| - time | 1670 | 373 | 1843 | 352 | 1580 | 281 | 1661 | 341 | 1669 | 367 | 1816 | 361 | 1669 | 356 | 2286 | 413 | |
| 4 | Graduates | ||||||||||||||||
| - percentage | 89.3 | 3.2 | 60.8 | 3.7 | 89.4 | 2.4 | 83.0 | 4.0 | 88.9 | 1.9 | 72.2 | 2.7 | 85.4 | 2.4 | 15.3 | 5.3 | |
| - perc. max. satisf | 33.2 | 4.4 | 5.7 | 1.9 | 27.4 | 2.9 | 13.7 | 3.1 | 32.7 | 3.0 | 11.3 | 2.3 | 20.1 | 2.1 | 1.7 | 2.5 | |
| - time | 1680 | 363 | 1853 | 353 | 1626 | 300 | 1670 | 332 | 1673 | 350 | 1820 | 365 | 1676 | 349 | 2251 | 400 | |
| Table 4: Graduation, satisfaction, time to graduate for a goal including three levels (similar to Master). With cold-start algorithm | |||||||||||||||||
| # sub domains | Variables | Treatment | No treatment | ||||||||||||||
| Ontology (O) | Peers (P) | Ratings (R) | OP | OR | PR | OPR | Control (C) | ||||||||||
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | ||
| 2 | Graduates | ||||||||||||||||
| - percentage | 92.1 | 1.7 | 61.5 | 4.3 | 90.6 | 2.1 | 85.1 | 3.4 | 92.5 | 2.1 | 73.6 | 4.6 | 87.8 | 2.2 | 10.4 | 2.9 | |
| - perc. max. satisf. | 92.5 | 1.6 | 62.1 | 4.4 | 68.9 | 2.5 | 72.8 | 3.4 | 91.2 | 2.1 | 70.3 | 2.1 | 76.3 | 2.0 | 47.9 | 11.8 | |
| - time | 5234 | 443 | 5504 | 587 | 5223 | 394 | 5247 | 490 | 5204 | 444 | 5423 | 557 | 5209 | 460 | 6057 | 543 | |
| 3 | Graduates | ||||||||||||||||
| - percentage | 88.9 | 2.2 | 51.4 | 3.8 | 83.8 | 2.6 | 79.9 | 2.9 | 89.9 | 2.5 | 65.5 | 5.0 | 83.50 | 3.3 | 8.1 | 2.3 | |
| - perc. max. satisf | 87.2 | 2.3 | 53.7 | 2.4 | 61.8 | 3.0 | 63.8 | 4.2 | 88.3 | 2.7 | 64.4 | 2.6 | 71.5 | 3.7 | 38.0 | 12.1 | |
| - time | 5246 | 457 | 5576 | 587 | 5326 | 430 | 5282 | 508 | 5236 | 459 | 5465 | 565 | 5268 | 495 | 6061 | 536 | |
| 4 | Graduates | ||||||||||||||||
| - percentage | 87.3 | 2.5 | 45.5 | 4.9 | 81.2 | 3.2 | 76.1 | 2.8 | 87.3 | 3.0 | 62.3 | 4.1 | 81.3 | 1.5 | 6.5 | 2.1 | |
| - perc. max. satisf | 75.6 | 2.8 | 44.5 | 3.3 | 54.1 | 4.3 | 59.6 | 4.2 | 74.7 | 5.0 | 59.6 | 4.3 | 68.3 | 2.2 | 26.7 | 10.0 | |
| - time | 5266 | 479 | 5581 | 572 | 5383 | 455 | 5301 | 518 | 5275 | 482 | 5502 | 569 | 5258 | 494 | 6073 | 553 | |
| Table 5: Outcomes for (a) Analyses of variance and (b) Multiple comparisons with Bonferroni's correction with respect to Graduation (N = 12 runs) | |||||
| Goal | # sub- | Analyses of variance | p | Multiple comparisons | |
| domains | F | MSE | (mean difference between two groups, all p <.05*) | ||
| Level-1 | 2 | F(7, 23992) = 1678.02 | 754 | <.05* | control group fewer Graduates than any treatment group |
| 3 | F(7, 23992) = 1552.80 | 783 | <.05* | control group fewer Graduates than any treatment group | |
| 4 | F(7, 23992) = 1378.75 | 775 | <.05* | control group fewer Graduates than any treatment group | |
| Level-3 | 2 | F(7, 23992) = 1903.68 | 937 | <.05* | control group fewer Graduates than any treatment group |
| 3 | F(7, 23992) = 1584.61 | 928 | <.05* | control group fewer Graduates than any treatment group | |
| 4 | F(7, 23992) = 1495.61 | 935 | <.05* | control group fewer Graduates than any treatment group | |
| Table 6: Outcomes for (a) Analyses of variance and (b) Multiple comparisons with Bonferroni's correction with respect to Satisfaction at graduation (N = 12 runs) | |||||
| Goal | # sub- | Analyses of variance | p | Multiple comparisons | |
| domains | F | MSE | (mean difference between two groups, all p < .05*) | ||
| Level-1 | 2 | F(7, 18890) = 533.09 | 11790 | < .05* | C fewer maximum satisfaction at graduation than any T |
| 3 | F(7, 18196) = 451.12 | 10966 | < .05* | C fewer maximum satisfaction at graduation than any T | |
| 4 | F(7, 17520) = 352.08 | 9175 | < .05* | C fewer maximum satisfaction at graduation than any T | |
| Level-3 | 2 | F(7, 17800) = 185.62 | 353 | < .05* | C fewer maximum satisfaction at graduation than any T |
| 3 | F(7, 16519) = 182.28 | 616 | < .05* | C fewer maximum satisfaction at graduation than any T | |
| 4 | F(7, 15815) = 107.23 | 634 | < .05* | C fewer maximum satisfaction at graduation than any T | |
| Table 7: Outcomes for (a) Analyses of variance and (b) Multiple comparisons with Bonferroni's correction with respect to time to graduate (N = 12 runs) | |||||
| Goal | # sub- | Analyses of variance | p | Multiple comparisons | |
| domains | F | MSE | (mean difference between two groups, all p < .05*) | ||
| Level-1 | 2 | F(7, 18890) = 416.89 | 49315069 | < .05* | C more time to graduate than any T |
| 3 | F(7, 18196) = 350.54 | 42896187 | < .05* | C more time to graduate than any T | |
| 4 | F(7, 17520) = 272.81 | 32631950 | < .05* | C more time to graduate than any T | |
| Level-3 | 2 | F(7, 17800) = 230.24 | 52926168 | < .05* | C more time to graduate than any T |
| 3 | F(7, 16519) = 184.26 | 45151363 | < .05* | C more time to graduate than any T | |
| 4 | F(7, 15815) = 157.14 | 40070442 | < .05* | C more time to graduate than any T | |
| Table 8: Graduation, satisfaction, time to graduate for a goal including one level (similar to Bachelor). No cold-start algorithm | |||||||||||||||||
| # sub domains | Variables | Treatment | No treatment | ||||||||||||||
| Ontology (O) | Peers (P) | Ratings (R) | OP | OR | PR | OPR | Control (C) | ||||||||||
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | ||
| 2 | Graduates | ||||||||||||||||
| - percentage | 94.2 | 1.5 | 51.9 | 4.4 | 76.5 | 3.8 | 88.4 | 1.7 | 94.4 | 1.8 | 58.5 | 4.9 | 88.9 | 2.5 | 15.6 | 4.4 | |
| - perc. max. satisf. | 48.4 | 4.5 | 6.0 | 2.1 | 28.1 | 2.7 | 23.0 | 3.2 | 49.5 | 4.4 | 11.7 | 3.0 | 28.8 | 3.6 | 3.6 | 3.3 | |
| - time | 1649 | 348 | 1902 | 359 | 1692 | 283 | 1649 | 335 | 1644 | 359 | 1897 | 358 | 1654 | 342 | 2334 | 402 | |
| 3 | Graduates | ||||||||||||||||
| - percentage | 91.1 | 2.3 | 44.0 | 4.2 | 70.0 | 2.8 | 84.1 | 3.4 | 90.8 | 2.1 | 53.6 | 6.0 | 87.4 | 2.4 | 10.7 | 3.5 | |
| - perc. max. satisf | 38.3 | 3.5 | 3.9 | 2.2 | 22.4 | 3.0 | 18.3 | 4.0 | 38.5 | 5.1 | 9.3 | 3.3 | 23.0 | 4.0 | 1.6 | 3.4 | |
| - time | 1667 | 364 | 1939 | 350 | 1730 | 295 | 1660 | 338 | 1669 | 363 | 1919 | 365 | 1682 | 350 | 2340 | 387 | |
| 4 | Graduates | ||||||||||||||||
| - percentage | 90.0 | 1.9 | 39.7 | 5.2 | 67.6 | 4.2 | 82.0 | 2.9 | 89.1 | 2.0 | 49.1 | 4.2 | 85.3 | 2.2 | 11.4 | 3.4 | |
| - perc. max. satisf | 33.3 | 2.7 | 3.5 | 1.7 | 20.1 | 3.1 | 13.8 | 2.4 | 34.1 | 4.7 | 6.0 | 2.7 | 19.1 | 3.5 | 1.8 | 1.9 | |
| - time | 1685 | 361 | 1926 | 350 | 1756 | 312 | 1674 | 338 | 1660 | 358 | 1915 | 344 | 1673 | 355 | 2304 | 392 | |
ANDERSON M, Ball M, Boley H, Greene S, Howse N, Lemire D and McGrath S (2003) RACOFI: A Rule-Applying Collaborative Filtering System. In Proceedings IEEE/WIC COLA'03, Halifax, Canada, October 2003
ANDRONICO A, Carbonaro A, Casadei G, Colazzo L, Molinari A, and Ronchetti M (2003) Integrating a multi-agent recommendation system into a mobile learning management system. Retrieved, October 18, 2007, from http://w5.cs.uni-sb.de/~krueger/aims2003/camera-ready/carbonaro-4.pdf
BALABANOVIC M and Shoham Y (1997) Fab: content-based, collaborative recommendation. Communications of the ACM, 40(3), 66-72.
BERLANGA A J, van den Berg E B , Nadolski R J , Drachsler H, Hummel H G K and Koper E J R (2007) Towards a model for navigation support in Learning Networks. ePortfolio Conference, Maastricht, The Netherlands, October 18-20, 2007. Retrieved, October 18, 2007, from http://dspace.ou.nl/handle/1820/1015
BOCK G W and Kim Y (2002) Breaking the myths of rewards: an exploratory study of attitudes about knowledge sharing. Information Resources Management Journal, 15(2), 14-21.
BOLMAN C, Tattersall C, Waterink W, Janssen J, van den Berg E B, van Es R and Koper E J R (2007) Learners' evaluation of a navigation support tool in distance education. Journal of Computer Assisted Learning, 23, 384-392.
CLAYPOOL M, Gokhale A, Miranda T, Murkinov P, Netes D and Sartin M (1999) Combining content-based and collaborative filters in an online newspaper. Paper presented at the conference ACM SIGIR Workshop on Recommender Systems: Algorithms and Evaluation. August, 19, 1999, Berkeley, CA, USA.
CRANEN K (2007) Using digital consults and determinants in following up advices [Het gebruik van het digital consult en de determinanten voor het opvolgen van het advies]. Master thesis. Enschede, The Netherlands: Twente University.
DRACHSLER H, Hummel H G K and Koper E J R (2008) Personal recommender systems for learners in lifelong learning networks: requirements, techniques and model. International Journal of Learning Technology, 3(4), 404-423.
DRACHSLER, H, Hummel, H G K, van den Berg, E B, Waterink, W, Eshuis, J, Nadolski, R J, Berlanga, A J, Boers, N, and Koper, E J R (2008) Effects of the ISIS recommender system for providing personalised advice to lifelong learners: an experimental study in the domain of Psychology. Accepted for publication.
FARZAN R and Brusilovsky P (2006) "AnnotatEd: A Social Navigation and Annotation Service for Web-based Educational Resources". In: Reeves T C and Yamashita S F (Eds.) Proceedings of World Conference on E-Learning, E-Learn 2006, Honolulu, HI, USA, October 13-17, 2006, AACE, pp. 2794-2802.
GILBERT N and Troitzsch K G (1999) Simulation for the social scientist. Buckingham, Philadelphia, USA: Open University Press.
GOOD N, Schafer J B, Konstan J A, Borchers A, Sarwar B, Herlocker J and Riedl J (1999) Combining collaborative filtering with personal agents for better recommendations. Proceedings of AAAI, 99, 439-446.
HSU M H (2008) A personalized English learning recommender system for ESL students. Expert Systems with Applications, 34(1), 683-688.
HUMMEL H G K, van den Berg E B, Berlanga A J, Drachsler H, Janssen J, Nadolski R J and Koper E J R (2007) Combining Social- and Information-based Approaches for Personalised Recommendation on Sequencing Learning Activities. International Journal of Learning Technology, 3(2), 152-168.
HUMMEL H G K, Burgos D, Tattersall C, Brouns F M R, Kurvers H J and Koper E J R (2005). Encouraging Contributions in Learning Networks by using Incentive Mechanisms. Journal of Computer Assisted Learning, 21(5), 355-365.
JANSSEN J , Berlanga A J, Vogten H and Koper E J R (2008) Towards a learning path specification. International Journal of Continuing Engineering Education and Lifelong Learning, 18(1), 77-97.
KONSTAN J, Miller B, Maltz D, Herlocker J, Gordon L, and Riedl J (1997) Grouplens. Communications of the ACM, 40(3), 77- 87.
KOPER E J R (2005) Increasing learner retention in a simulated learning network using indirect social interaction. Journal of Artificial Societies and Social Simulation, 8(2). Retrieved, October 30, 2007, from https://www.jasss.org/8/2/5.html
KOPER E J R and Olivier B (2004) Representing the Learning Design of Units of Learning. Educational Technology & Society, 7(3), 97-111.
KOPER E J R and Sloep P B (2002) Learning Networks: connecting people, organizations, autonomous agents and learning resources to establish the emergence of effective lifelong learning (OTEC RTD Programme Plan 2003-2008). Heerlen: Open University of the Netherlands. Available from: http://hdl.handle.net/1820/65.
LAW A M and Kelton W D (2000) Simulation Modeling and Analysis. Boston: McGrawHill.
LEMIRE D (2005) Scale and Translation Invariant Collaborative Filtering Systems. Information Retrieval, 8(1), 129-150, January 2005.
LEMIRE D, Boley H, McGrath S and Ball M. (2005) Colloborative filtering and inference rules for context-aware learning object recommendation. International Journal of Interactive Technology and Smart Education, 2(3). August 2005.
LEMIRE D and MacLachlan A (2005) "Slope One Predictors for online rating-based collaborative filtering". In: SIAM Data Mining (SDM'05), Newport Beach, California, April 21-23, 2005.
MANOUSELIS N and Costopoulou C (2007) Analysis and Classification of Multi-Criteria Recommender Systems, to appear in World Wide Web: Internet and Web Information Systems, Special Issue on "Multi-channel Adaptive Information Systems on the World Wide Web",
MCCALLA G (2004) The ecological approach to the design of e-Learning environments: Purpose-based capture and use of information about learners. Journal of Interactive Media in Education. Retrieved October 18, 2007, from http://www-jime.open.ac.uk/2004/7
MCNEE S M, Riedl J, and Konstan J A (2006) Making recommendations better: an analytic model for human-recommender interaction. Proceedings of Conference on Human Factors in Computing Systems, 1103-1108, 22-26 april, 2006. Montréal, Québec, Canada.
MELVILLE P, Mooney R J and Nagarajan R (2002) Content-boosted collaborative filtering for improved recommendations. Proceedings of 18th National Conference on Artificial Intelligence, 187-192. July 28 - August 1, 2002, Edmonton, Alberta, Canada.
PAZZANI M J (1999) A framework for collaborative, content-based and demographic filtering. Artificial Intelligence Review, 13(5), 393-408.
RAFAELI S, Barak M, Dan-Gur Y and Toch E (2004). QSIA - a Web-based environment for learning, assessing and knowledge sharing in communities. Computers & Education, 43, 273-289.
RAFAELI S, Dan-Gur Y and Barak M (2005) Social Recommender Systems: Recommendations in Support of E-Learning. Journal of Distance Education Technologies, 3(2), 29-45.
RYAN R M and Deci E L (2000) Self-determination theory and the facilitation of intrinsic motivation, social developments and well being. American Psychologist, 55, 68-78.
SHEN L and Shen R (2004) "Learning Content Recommendation Service based on Simple Sequencing Specification". In Liu W et al. (Eds.) ICWL 2004, LNCS 3143, 363-370.
SOBORO I M and Nicholas C K (2000) Combining content and collaboration in text filtering. Proceedings of the IJCAI Workshop on Machine Learning in Information Filtering, 86-91. August, 1999, Stockholm.
TANG T Y and McCalla G (2004a) Beyond Learners' Interest: Personalized Paper Recommendation Based on Their Pedagogical Features for an E-Learning System. Proceedings of the 8th Pacific Rim International Conference on Artificial Intelligence (PRICAI 2004), Auckland, New Zealand, August 9-13, 2004.
TANG T Y and McCalla G (2004b) Utilizing Artificial Learners to help overcome the cold-start problem in a Pedagogical-Oriented Paper Recommendation System. Proceedings of AH 2004: International Conference on Adaptive Hypermedia and Adaptive Web-Based Systems, Eindhoven, The Netherlands, August 23-26.
TANG T Y and McCalla G (2005) Smart Recommendation for an Evolving E-Learning System: Architecture and Experiment, International Journal on E-Learning, 4 (1), 105-129.
VAN SETTEN M (2005) Supporting People in finding information: Hybrid Recommender Systems and Goal-Based Structuring. Doctoral thesis. Enschede, The Netherlands: Telematica Instituut.
VYGOTSKY L (1978) Mind in Society: The development of higher psychological functions. Cambridge: Harvard University Press.
WALKER A, Recker M M, Lawless K and Wiley D (2004). Colloborative Information Filtering: a review and an educational application. International Journal of Artificial Intelligence in Education, 14, 1-26.
WILENSKY U (1999) NetLogo. http://ccl.northwestern.edu/netlogo/. Center for Connected Learning and Computer-Based Modeling, Northwestern University, Evanston, IL.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2009]