
André C. R. Martins (2008)
Replication in the Deception and Convergence of Opinions Problem
Journal of Artificial Societies and Social Simulation
vol. 11, no. 4 8
<https://www.jasss.org/11/4/8.html>
For information about citing this article, click here
Received: 19-Jan-2008 Accepted: 27-Sep-2008 Published: 31-Oct-2008

 Abstract
Abstract| P(S|p,e,d,a,b)=ed+(1-e)[pa+(1-p)(1-b)] | (1) |
| P(S|p,e,d,a,b)=e[0.5h+(1-h)d]+(1-e)[pa+(1-p)(1-b)] | (2) |
|
P(SR)= e{[e(0.5h+(1-h)d)+(1-e)(pa+(1-p)(1-b))] [0.5h+(1-h)d]}
+(1-e){[pa+(1-p)(1-b)][e(1-h)d+(1-e(1-h))(pa+(1-p)(1-b))]} P(S~R)= e{[e(0.5h+(1-h)d)+(1-e)(p(1-a)+(1-p)b)] [0.5h+(1-h)(1-d)]} +(1-e){[ pa+(1-p)(1-b)][e(1-h)(1-d)+(1-e(1-h))(p(1-a)+(1-p)b)]} P(~SR)= e{[e(0.5h+(1-h)(1-d))+(1-e)(pa+(1-p)(1-b))] [0.5h+(1-h)d]} +(1-e){[ p(1-a)+(1-p)b][e(1-h)d+(1-e(1-h))(pa+(1-p)(1-b))]} and P(~S~R)= e{[e(0.5h+(1-h)(1-d))+(1-e)(p(1-a)+(1-p)b)] [0.5h+(1-h)(1-d)]} +(1-e){[ p(1-a)+(1-p)b][e(1-h)(1-d)+(1-e(1-h))(p(1-a)+(1-p)b)]} |
(3) |
| n = 4o(S)(1-o(S)) / [o(R)-o(S)]2 | (4) |
where it was assumed, for the numerator that o(R) and o(S) were very close and that o(S)(1-o(S)) was basically the same as o(R)(1-o(R)).
|
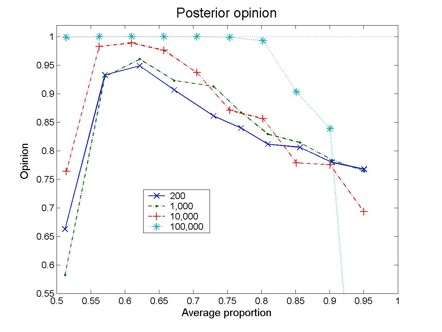
| Figure 1. Posterior opinion as a function of the average proportion, 0.5(o(S)+o(R)). Each curve corresponds to a different number of pairs of articles (original experiment and replication). The results correspond to a=b=0.6. For 200 and 1,000 pairs, the results correspond to averages over 20 different realizations |
|
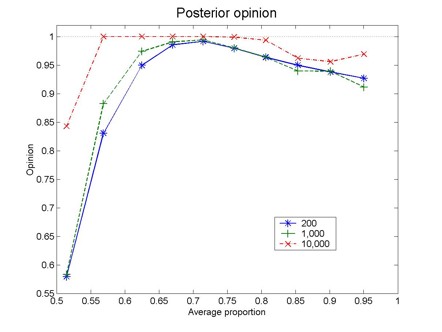
| Figure 2. Posterior opinion as a function of the average proportion, 0.5(o(S)+o(R)). Each curve corresponds to a different number of pairs of articles (original experiment and replication). These results were obtained with a=b=0.7 |
|
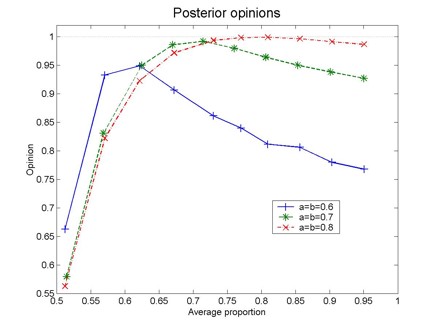
| Figure 3. Posterior opinion as a function of the average proportion, 0.5(o(S)+o(R)), for different values of a and b. The results correspond to 200 pairs of articles (original experiment and replication) and are averages over 20 different realizations |
CHASE, J.E. (1971), Normative criteria for scientific publications, American Sociologist, 5, 262-265.
EVANSCHITZKY, H., Baumgarth, C., Hubbard, R., and Armstrong, J. S. (2007) Replication Research in Marketing Revisited: A Note on a Disturbing Trend, Journal of Business Research, 60, 411-415.
GILES, J. (2006) The Trouble with Replication. Nature, 442, 344 - 347.
HUBBARD, R., and Armstrong, J. S. (1994) Replications and Extensions in Marketing — Rarely Published But Quite Contrary, International Journal of Research in Marketing, 11, 233-248
JAYNES, E.T. (2003) Probability Theory: The Logic of Science (Cambridge: Cambridge University Press).
IOANNIDIS, J. P. A. (2005) Contradicted and initially stronger effects in highly cited clinical research. Journal of the American Medical Association, 294, 218-228.
MARTINS, A. C. R. (2005) Deception and Convergence of Opinions, Journal of Artificial Societies and Social Simulations, vol. 8 (2) 3 https://www.jasss.org/8/2/3.html.
MARTINS, A. C. R. (2006) Probabilistic Biases as Bayesian Inference. Judgment And Decision Making, 1, 108-117.
PALMER, V. (2006) Deception and Convergence of Opinions Part 2: the Effects of Reproducibility, Journal of Artificial Societies and Social Simulations, 9 (1) 14 https://www.jasss.org/9/1/14.html.
TENENBAUM, J. B., Kemp, C. and Shafto, P. (2007) Theory-based Bayesian models of inductive reasoning, in Feeney, A. and Heit, E., Inductive reasoning, Cambridge, Cambridge University Press.
TITUS, S. L., Wells, J. A., and Rhoades, L. J. (2008) Repairing research integrity, Nature, 453, 980-982.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2008]