
Annie Abello, Sharyn Lymer, Laurie Brown, Ann Harding and Ben Phillips (2008)
Enhancing the Australian National Health Survey Data for Use in a Microsimulation Model of Pharmaceutical Drug Usage and Cost
Journal of Artificial Societies and Social Simulation
vol. 11, no. 3 2
<https://www.jasss.org/11/3/2.html>
For information about citing this article, click here
Received: 06-Aug-2007 Accepted: 16-May-2008 Published: 30-Jun-2008

 Abstract
Abstract
|
|
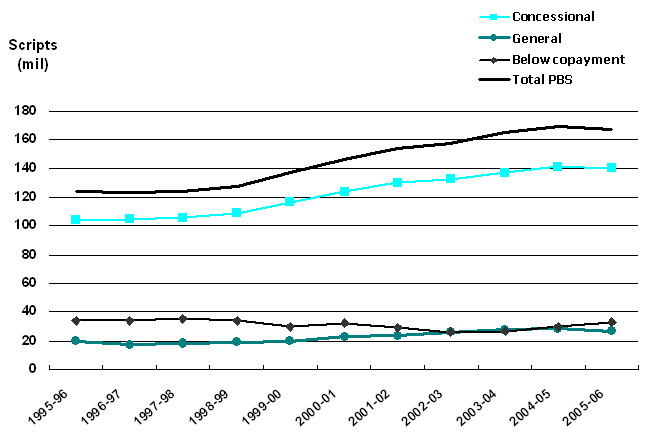
Figure 1. Volume of PBS-listed scripts, 1995-96 to 2005-06. Data sources: Medicare Australia website; Drug Utilisation Sub-Committee (DUSC) Drug Utilisation Database, Pharmaceutical Benefits Branch, Commonwealth Department of Health and Ageing. |
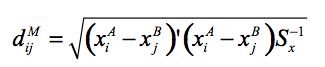
|
(1) |
where Sx is the estimated covariance matrix for the X variables. This was calculated using user-defined weights corresponding to the relative importance given to each matching variable. The X variables include age, number of usual residents in the household and equivalent income unit decile. The age variable in the distance function has 16 possible categories, somewhat more than the 6 categories employed in the cell groups. Two approaches were considered in implementing this stage of the matching procedure: unconstrained and constrained matching.
| Table 1: Unconstrained matching age allocation | |||||||||||||||||
| Matched | NHS age group | ||||||||||||||||
| dataset | 0-4 | 5-9 | 10-14 | 15-19 | 20-24 | 25-29 | 30-34 | 35-39 | 40-44 | 45-49 | 50-54 | 55-59 | 60-64 | 65-69 | 70-74 | 75+ | |
| 0-4 | 100 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 5-9 | . | 90 | 10 | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 10-14 | . | 16 | 84 | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 15-19 | . | . | . | 88 | 12 | . | . | . | . | . | . | . | . | . | . | . | |
| 20-24 | . | . | . | 38 | 62 | . | . | . | . | . | . | . | . | . | . | . | |
| 25-29 | . | . | . | . | . | 79 | 18 | 4 | . | . | . | . | . | . | . | . | |
| 30-34 | . | . | . | . | . | 12 | 75 | 14 | . | . | . | . | . | . | . | . | |
| 35-39 | . | . | . | . | . | 3 | 12 | 85 | . | . | . | . | . | . | . | . | |
| 40-44 | . | . | . | . | . | . | . | . | 83 | 13 | 4 | 0 | . | . | . | . | |
| 45-49 | . | . | . | . | . | . | . | . | 15 | 72 | 11 | 1 | 0 | . | . | . | |
| 50-54 | . | . | . | . | . | . | . | . | 3 | 12 | 75 | 9 | 1 | . | . | . | |
| 55-59 | . | . | . | . | . | . | . | . | 1 | 3 | 13 | 72 | 11 | . | . | . | |
| 60-64 | . | . | . | . | . | . | . | . | 0 | 1 | 3 | 12 | 84 | . | . | . | |
| 65-69 | . | . | . | . | . | . | . | . | . | . | . | . | . | 89 | 9 | 2 | |
| 70-74 | . | . | . | . | . | . | . | . | . | . | . | . | . | 7 | 86 | 7 | |
| 75+ | . | . | . | . | . | . | . | . | . | . | . | . | . | 5 | 6 | 89 | |
| Table 2: Constrained matching age allocation | |||||||||||||||||
| Matched | NHS age group | ||||||||||||||||
| dataset | 0-4 | 5-9 | 10-14 | 15-19 | 20-24 | 25-29 | 30-34 | 35-39 | 40-44 | 45-49 | 50-54 | 55-59 | 60-64 | 65-69 | 70-74 | 75+ | |
| 0-4 | 100 | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 5-9 | . | 87 | 13 | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 10-14 | . | 11 | 89 | . | . | . | . | . | . | . | . | . | . | . | . | . | |
| 15-19 | . | . | . | 88 | 12 | . | . | . | . | . | . | . | . | . | . | . | |
| 20-24 | . | . | . | 25 | 75 | . | . | . | . | . | . | . | . | . | . | . | |
| 25-29 | . | . | . | . | . | 77 | 20 | 3 | . | . | . | . | . | . | . | . | |
| 30-34 | . | . | . | . | . | 14 | 73 | 14 | . | . | . | . | . | . | . | . | |
| 35-39 | . | . | . | . | . | 1 | 18 | 81 | . | . | . | . | . | . | . | . | |
| 40-44 | . | . | . | . | . | . | . | . | 70 | 19 | 8 | 3 | . | . | . | . | |
| 45-49 | . | . | . | . | . | . | . | . | 12 | 58 | 22 | 7 | 1 | . | . | . | |
| 50-54 | . | . | . | . | . | . | . | . | 4 | 12 | 57 | 22 | 6 | . | . | . | |
| 55-59 | . | . | . | . | . | . | . | . | 1 | 3 | 10 | 59 | 27 | . | . | . | |
| 60-64 | . | . | . | . | . | . | . | . | 0 | 1 | 2 | 15 | 82 | . | . | . | |
| 65-69 | . | . | . | . | . | . | . | . | . | . | . | . | . | 69 | 23 | 8 | |
| 70-74 | . | . | . | . | . | . | . | . | . | . | . | . | . | 9 | 62 | 29 | |
| 75+ | . | . | . | . | . | . | . | . | . | . | . | . | . | 3 | 8 | 89 | |
| Table 3: Distribution of persons by term of health condition, 1995 and 2001 | |||
| Year | Condition | Persons | |
| (thousands) | % | ||
| 1995 | Long term only or both recent and long-term | 13,365 | 74 |
| Recent only (short-term) | 1,625 | 9 | |
| No health conditions (not applicable) | 2,890 | 16 | |
| Total population | 18,061 | 100 | |
| 2001 | With a long term condition | 14,737 | 78 |
| Without a long term condition | 4,179 | 22 | |
| Total population | 18,916 | 100 | |
| Table 4: Two-monthly prevalence rate of back problems by concession card status, 2001 (per 100 population) Source: NATSEM estimates. | |||||
| Concessional | Concessional | General | General | ||
| Males | Females | Males | Females | ||
| 15-34 years | 0.03 | 0.01 | 0.01 | 0.01 | |
| 35-49 years | 0.09 | 0.09 | 0.07 | 0.16 | |
| 50-64 years | 0.12 | 0.18 | 0.15 | 0.17 | |
| 65-74 years | 0.23 | 0.18 | 0.13 | 0.17 | |
| 75 years plus | 0.12 | 0.13 | 0.14 | 0.05 | |
|
|
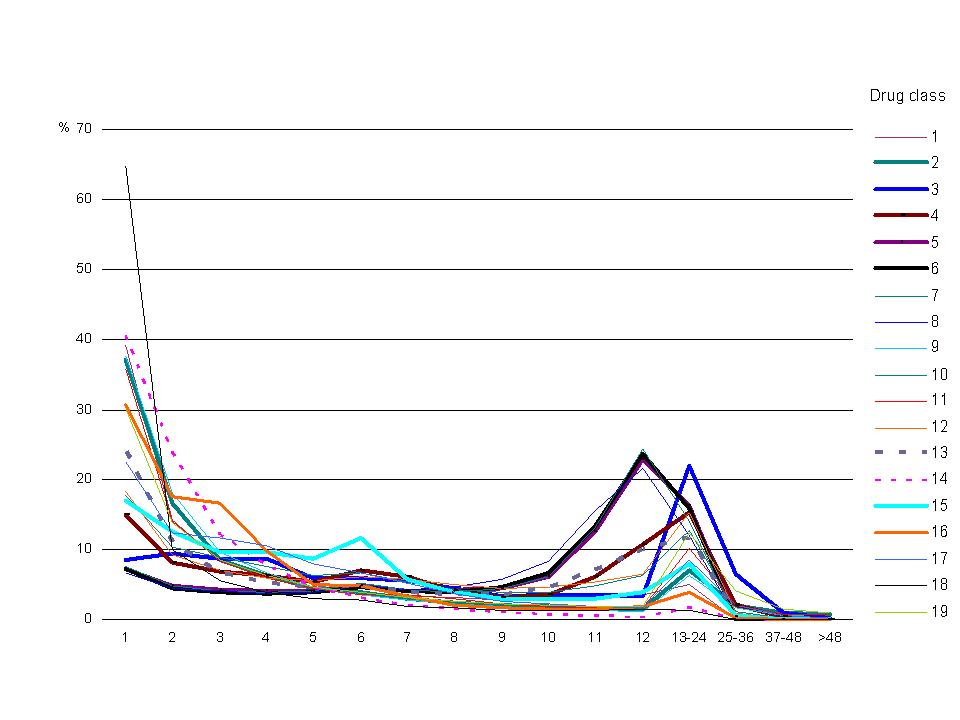
Figure 2. Distribution of annual PBS scripts per person, 2003 Data source: Medicare Australia Note: See Appendix Table B1 for listing of drug classes. The data underlying this graph are in Appendix Table C1. |
| Table 5: Example on distribution of PBS scripts per person (anti-inflammatories, males with concessional card status) by age group, 2003
Data source: Medicare Australia. | ||||||
| Number of persons by age group | ||||||
| No. of scripts | 0-4 | 5-14 | 15-24 | 25-34 | 35-64 | 65+ |
| 1 | 231 | 3,426 | 21,342 | 40,650 | 86,569 | 85,152 |
| 2 | 32 | 335 | 3,092 | 10,005 | 35,847 | 41,216 |
| 3 | 6 | 119 | 860 | 4,194 | 20,611 | 27,669 |
| 4 | 9 | 70 | 415 | 2,344 | 15,746 | 23,305 |
| 5 | 6 | 37 | 198 | 1,368 | 10,463 | 16,614 |
| 6 | 2 | 24 | 130 | 908 | 8,504 | 14,748 |
| 7 | 2 | 19 | 98 | 706 | 7,417 | 13,763 |
| 8 | 1 | 10 | 34 | 452 | 6,172 | 12,110 |
| 9 | 1 | 11 | 37 | 420 | 7,357 | 15,798 |
| 10 | 1 | 7 | 99 | 867 | 12,238 | 22,213 |
| 11 | 0 | 7 | 88 | 597 | 6,746 | 12,779 |
| 12 | 0 | 19 | 54 | 489 | 5,960 | 11,315 |
| 13-24 | 0 | 12 | 51 | 413 | 7,075 | 14,677 |
| 25-36 | 0 | 0 | 2 | 48 | 363 | 330 |
| 37+ | 0 | 0 | 0 | 4 | 45 | 26 |
| Total | 291 | 4,096 | 26,500 | 63,465 | 231,113 | 311,715 |
| Table 6: Policy settings of the Pharmaceutical Benefits Scheme, 2001-06 | |||||||
| 1/1/2001 | 1/1/2002 | 1/1/2003 | 1/1/2004 | 1/1/2005 | 1/1/2006 | ||
| $ | $ | $ | $ | $ | $ | ||
| Copayment — Concessional | |||||||
| Below safety net | 3.5 | 3.6 | 3.7 | 3.8 | 4.6 | 4.7 | |
| Above safety net | 0 | 0 | 0 | 0 | 0 | 0 | |
| Copayment — General | |||||||
| Below safety net | 21.9 | 22.4 | 23.1 | 23.7 | 28.6 | 29.5 | |
| Above safety net | 3.5 | 3.6 | 3.7 | 3.8 | 4.6 | 4.7 | |
| Safety net threshold | |||||||
| Concessional | 182.0 | 187.2 | 192.4 | 197.6 | 239.2 | 253.8 | |
| General | 669.7 | 686.4 | 708.4 | 726.4 | 874.9 | 960.1 | |
| No. of safety net scripts | |||||||
| Concessional | 52 | 52 | 52 | 52 | 52 | 54 | |
| General | 31 | 31 | 31 | 31 | 31 | 33 | |
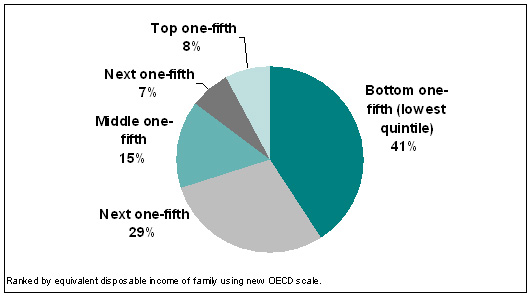
|
| Figure 3. Estimated percent of PBS outlays received by each income quintile of Australians, 2005-06 |
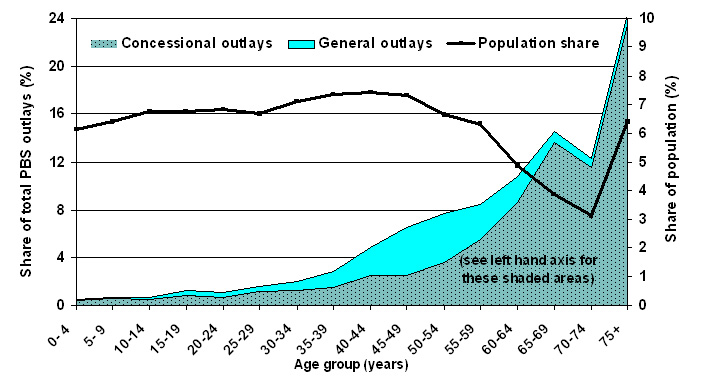
|
| Figure 4. Estimated percent of PBS outlays received by age group, 2005-06 |
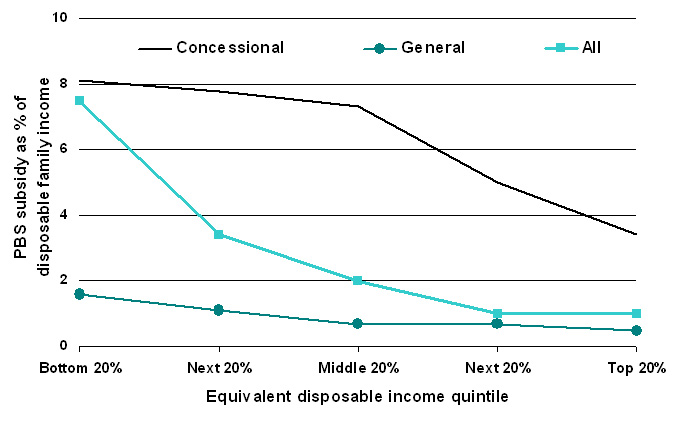
|
| Figure 5. Estimated PBS subsidy as a proportion of disposable family income, 2005-06 |
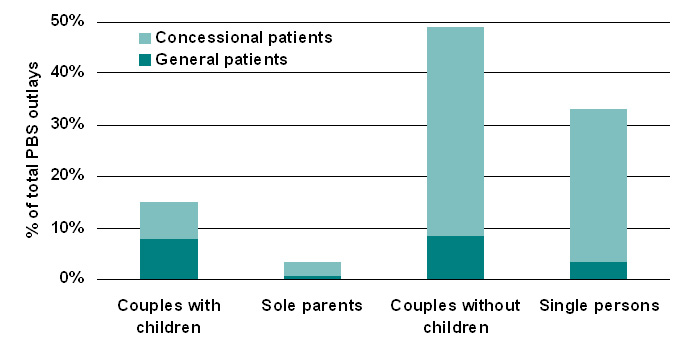
|
| Figure 6. Estimated distribution of PBS subsidy by family type, 2005-06 |
| Table 7: Estimated impact of the PBS by family type, 2005-06 | ||||||
| Couples | Sole | Couples | Single | All | ||
| with | parents | without | persons | families | ||
| children | children | |||||
| Unit | ||||||
| All patients | ||||||
| Disposable annual income per family (1) | $ | 58,039 | 31,400 | 39,790 | 26,552 | 36,638 |
| Family spending per year on PBS drugs (2) | $ | 203 | 83.8 | 220.4 | 73.5 | 137.3 |
| Family spending % of income (2/1) | % | 0.3 | 0.3 | 0.6 | 0.3 | 0.4 |
| Govt subsidy per family on PBS drugs (3) | $ | 487.4 | 455.5 | 1,109.00 | 347.1 | 569.2 |
| Government subsidy % of income (3/1) | % | 0.8 | 1.4 | 2.8 | 1.3 | 1.5 |
| % of all PBS govt. subsidy received by this group | % | 14.9 | 3.2 | 48.9 | 33 | 100 |
| Total PBS expenditure per family (2+3) | $ | 690.4 | 539.3 | 1329.4 | 420.6 | 706.5 |
| Total PBS spending % of income (2+3)/1 | % | 1.2 | 1.7 | 3.3 | 1.6 | 1.9 |
| No. of families | '000 | 2,170 | 469 | 2,550 | 5,157 | 10,347 |
| Concessional patients | ||||||
| Disposable annual income per family (1) | $ | 33,560 | 27,918 | 25,985 | 18,063 | 22,903 |
| Family spending per year on PBS drugs (2) | $ | 136.6 | 74.8 | 198.6 | 106.7 | 132.7 |
| Family spending % of income (2/1) | % | 0.4 | 0.3 | 0.8 | 0.6 | 0.6 |
| Govt subsidy per family on PBS drugs (3) | $ | 1141.7 | 507.2 | 2062 | 796.7 | 1161.9 |
| Government subsidy % of income (3/1) | % | 3.4 | 1.8 | 7.9 | 4.4 | 5.1 |
| % of all PBS govt. subsidy received by this group | % | 7.4 | 2.7 | 40.5 | 29.6 | 80.2 |
| Total PBS expenditure per family (2+3) | $ | 1278.3 | 582 | 2260.6 | 903.4 | 1294.6 |
| Total PBS spending % of income (2+3)/1 | % | 3.8 | 2.1 | 8.7 | 5 | 5.6 |
| No. of families | '000 | 424 | 371 | 1,097 | 2,016 | 3,907 |
| General patients | ||||||
| Disposable annual income per family (1) | $ | 63,975 | 44,539 | 50,218 | 31,998 | 44,973 |
| Family spending per year on PBS drugs (2) | $ | 219 | 117.8 | 236.9 | 52.2 | 140.1 |
| Family spending % of income (2/1) | % | 0.3 | 0.3 | 0.5 | 0.2 | 0.3 |
| Govt subsidy per family on PBS drugs (3) | $ | 328.8 | 260.3 | 389 | 58.6 | 209.5 |
| Government subsidy % of income (3/1) | % | 0.5 | 0.6 | 0.8 | 0.2 | 0.5 |
| % of all PBS govt. subsidy received by this group | % | 7.6 | 0.5 | 8.4 | 3.4 | 19.8 |
| Total PBS expenditure per family (2+3) | $ | 547.8 | 378.1 | 625.9 | 110.8 | 349.6 |
| Total PBS spending % of income (2+3)/1 | % | 0.9 | 0.8 | 1.2 | 0.3 | 0.8 |
| No. of families | '000 | 1,746 | 98 | 1,453 | 3,142 | 6,439 |
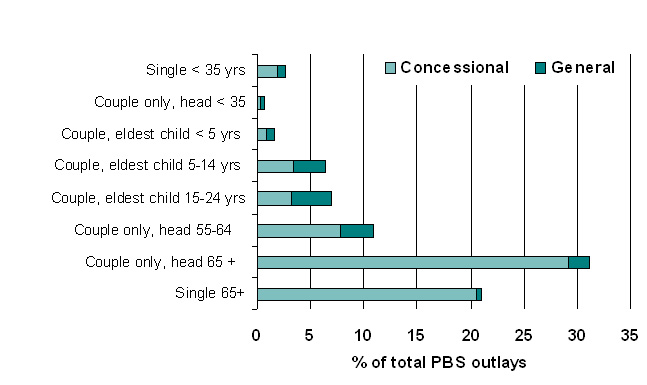
|
| Figure 7. Estimated distribution of PBS subsidy by lifecycle group, 2005-06 |
| Table 8: Estimated impact of PBS by lifecycle group, 2005-06 | |||||||||
| Single | Couple | Couple, | Couple | Couple | Couple | Couple | Single | ||
| <35yrs | only, head | eldest | eldest | eldest | only, head | only, head | 65+ yrs | ||
| <35yrs | child | child | child | 55-64yrs | 65+ yrs | ||||
| Unit | |||||||||
| All patients | |||||||||
| Disp. annual family income (1) | $ | 27,699 | 53,670 | 54,573 | 57,912 | 60,670 | 36,553 | 29,201 | 18,771 |
| Family spending on PBS (2) | $ | 19 | 48 | 111 | 188 | 295 | 276 | 265 | 165 |
| Family spending % income (2/1) | % | 0.1 | 0.1 | 0.2 | 0.3 | 0.5 | 0.8 | 0.9 | 0.9 |
| Govt PBS subsidy per family (3) | $ | 57.8 | 104.4 | 278 | 431 | 734.2 | 949.1 | 2323 | 1132 |
| Govt subsidy % of income (3/1) | % | 0.2 | 0.2 | 0.5 | 0.7 | 1.2 | 2.6 | 8 | 6 |
| % of all PBS govt subsidy received by this group | % | 2.7 | 0.6 | 1.6 | 6.5 | 7 | 11 | 31.6 | 21.3 |
| Total PBS family spending (2+3) | $ | 76.8 | 152.4 | 389 | 619 | 1029.2 | 1225.1 | 2588 | 1297 |
| Tot. spending % income (2+3)/1 | % | 0.3 | 0.3 | 0.7 | 1.1 | 1.7 | 3.4 | 8.9 | 6.9 |
| No. of families | '000 | 2,469 | 418 | 430 | 1,118 | 621 | 646 | 769 | 1,009 |
| Concessional patients | |||||||||
| Disp. annual family income (1) | $ | 19,831 | 28,966 | 30,173 | 33,822 | 34,929 | 24,180 | 26,607 | 17,693 |
| Family spending on PBS (2) | $ | 29 | 66 | 95 | 129 | 171 | 188 | 219 | 158 |
| Family spending % income (2/1) | % | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.8 | 0.8 | 0.9 |
| Govt PBS subsidy per family (3) | $ | 187.4 | 476.8 | 742.6 | 1063.6 | 1485.4 | 1746.5 | 2422.8 | 1200.5 |
| Govt subsidy % of income (3/1) | % | 0.9 | 1.6 | 2.5 | 3.1 | 4.3 | 7.2 | 9.1 | 6.8 |
| % of all PBS govt subsidy received by this group | % | 1.9 | 0.3 | 0.8 | 3.4 | 3.2 | 7.9 | 29.2 | 20.6 |
| Total PBS family spending (2+3) | $ | 216.4 | 542.8 | 837.6 | 1192.6 | 1656.4 | 1934.5 | 2641.8 | 1358.5 |
| Tot. spending % income (2+3)/1 | % | 1.1 | 1.9 | 2.8 | 3.5 | 4.7 | 8 | 9.9 | 7.7 |
| No. of families | '000 | 549 | 39 | 71 | 221 | 132 | 244 | 678 | 932 |
| General patients | |||||||||
| Disp. annual family income (1) | $ | 29947 | 56224 | 59353 | 63841 | 67625 | 44060 | 48746 | 31947 |
| Family spending on PBS (2) | $ | 16 | 46 | 114 | 202 | 328 | 329 | 613 | 244 |
| Family spending % income (2/1) | % | 0.05 | 0.08 | 0.2 | 0.3 | 0.5 | 0.7 | 1.3 | 0.8 |
| Govt PBS subsidy per family (3) | $ | 20.7 | 65.9 | 187 | 275.3 | 531.2 | 465.2 | 1571.5 | 294.3 |
| Govt subsidy % of income (3/1) | % | 0.1 | 0.1 | 0.3 | 0.4 | 0.8 | 1.1 | 3.2 | 0.9 |
| % of all PBS govt subsidy received by this group | % | 0.7 | 0.3 | 0.8 | 3 | 3.8 | 3 | 2 | 0.4 |
| Total PBS family spending (2+3) | $ | 36.7 | 111.9 | 301 | 477.3 | 859.2 | 794.2 | 2184.5 | 538.3 |
| Tot. spending % income (2+3)/1 | % | 0.1 | 0.2 | 0.5 | 0.7 | 1.3 | 1.8 | 4.5 | 1.7 |
| No. of families | '000 | 1,921 | 379 | 360 | 897 | 489 | 402 | 90 | 76 |
2 The Australian health system has identified 7 national health priority areas (NHPAs), including arthritis and musculoskeletal conditions, asthma, cancer control, cardiovascular health, diabetes mellitus, injury prevention and control, and mental health. The diseases and conditions targeted under the NHPA initiative were chosen because they currently impose high social and financial costs on Australian society, and through appropriate and focused attention significant gains in the health of Australia's population can be achieved.
3 The Australian Bureau of Statistics defines an income unit as 'one person or a group of related persons within a household, whose command over income is assumed to be shared. Income sharing is assumed to take place within married (registered or de facto) couples, and between parents and dependent children' (ABS 2001).
4 NATSEM was given approval by the ABS to conduct the statistical matching, and as part of the approval process, a joint ABS-NATSEM Technical Working Group on Statistical Matching was formed.
5 Rodgers (1984) gives a detailed description of statistical matching, as do Rassler (2002), Radner et al (1980), Cohen (1991), Sutherland et al (2002) and Moriarty and Scheuren (2001).
6 The results are based on unconstrained matching where the distance function used weights of 0.5 for age, 0.25 for equivalised income unit decile and 0.25 for the number of usual residents in the household.
7 For the LP approach each record was "exploded" so that a record was repeated to the extent of its weight. The selection without replacement refers to this "exploded" data set.
8 For our purposes, this only posed a problem with respect to the family income variable. As persons had been reconstructed into synthetic families, whilst retaining all original NHS variables, persons belonging to the same family had different family income values. To have a consistent family income, we averaged the income within each family. This average value was used to rank persons into income quintiles. Note however that the situation would be the same for any variable which relates to the whole family (and should thus be the same across the family), e.g. rurality, SEIFA.
9 For selected long-term conditions, the ABS has made a study of the comparability of the 1995 and 2001 surveys (ABS 2003b). For some conditions, such as heart and circulatory, they have indicated that each successive survey has improved the breadth and specificity of questioning for heart and circulatory. For mental conditions, a greater level of public awareness (and acceptance) may have influenced the higher rates of disclosure of mental health conditions.
10 For most health conditions (except diabetes, heart problems, depression, psychoses, and epilepsy and a few other conditions) a large proportion of persons did not report using any prescribed medication over the previous two weeks in the 1995 NHS. One reason for this could be that not all persons who have a long-term condition currently have an acute episode of that condition, in which case they may opt to take their medication less frequently or not at all. Other reasons could be that prescribed medication is not appropriate for that condition, or that non-prescribed medicine or other types of treatment are used to manage that condition.
11 Veterans were excluded from the model as there is a scheme that parallels the PBS, called the Repatriation Pharmaceutical Benefits Scheme (RPBS) that is separately administered for Australian war veterans and their dependants.
122003 is the first calendar year for which Medicare Australia had data on the distribution of scripts per person by gender, age group and drug classification for both concession cardholders and non-cardholders. Previous to this, data were only collected on concession cardholders that had not yet reached the safety net.
13 Medicare Australia was previously known as the Health Insurance Commission (HIC).
14 Related information on general practice activity (Britt et al 2004) shows that for four out of the five drug classes listed, there was a decrease in medication rates (albeit over a slightly different time period, 1998 to 2004), which is consistent with the finding that for these particular drug classes, there were sufficient number of persons taking medications.
15 The institutionalised include those in hospitals and in homes for the aged and disabled. While we have no data on their drug usage, we expect this to be much higher than the drug usage of persons not living in those institutions.
16 Actual data for 2005-06 are slightly different from NATSEM estimates: at 167 million scripts (instead of 172 million) and total cost of A$6.7 billion (instead of A$6.6 billion).
| Table A1: Quality of the match: number of usual residents variable | |||||||
| NHS | HES number of usual residents | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | ||
| Unconstrained | 1 | 93 | 7 | . | . | . | . |
| 2 | 7 | 90 | 3 | 0 | 0 | 0 | |
| 3 | 3 | 9 | 80 | 7 | 1 | 1 | |
| 4 | 1 | 3 | 7 | 86 | 2 | 1 | |
| 5 | 1 | 2 | 3 | 13 | 79 | 2 | |
| 6 | 3 | 1 | 6 | 11 | 14 | 65 | |
| Constrained | 1 | 81 | 14 | 3 | 1 | 0 | 0 |
| 2 | 4 | 82 | 10 | 3 | 1 | 0 | |
| 3 | 2 | 18 | 61 | 18 | 1 | 0 | |
| 4 | 1 | 7 | 12 | 72 | 7 | 1 | |
| 5 | 1 | 1 | 2 | 16 | 67 | 14 | |
| 6 | 2 | 1 | 2 | 3 | 20 | 72 | |
| Table A2: Quality of the match: equivalent income decile variable | ||||||||||
| HES equivalent income unit decile | ||||||||||
| NHS | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Unconstrained | ||||||||||
| 1 | 76 | 20 | 4 | 0 | 0 | . | . | . | . | . |
| 2 | 13 | 75 | 9 | 3 | 0 | 0 | . | . | . | . |
| 3 | 6 | 6 | 73 | 9 | 4 | 1 | 0 | . | . | . |
| 4 | 0 | 1 | 5 | 72 | 16 | 5 | 1 | 0 | 0 | 0 |
| 5 | 0 | 1 | 3 | 11 | 70 | 12 | 3 | 0 | 0 | 0 |
| 6 | . | 0 | 1 | 2 | 7 | 82 | 5 | 2 | 1 | 0 |
| 7 | 0 | 0 | . | 0 | 1 | 8 | 85 | 3 | 2 | 0 |
| 8 | . | . | . | . | 0 | 0 | 4 | 87 | 5 | 4 |
| 9 | . | . | . | . | 0 | 0 | 0 | 3 | 88 | 9 |
| 10 | . | . | . | . | . | 0 | . | 0 | 3 | 97 |
| Constrained | ||||||||||
| 1 | 35 | 10 | 7 | 12 | 14 | 12 | 3 | 2 | 1 | 3 |
| 2 | 12 | 31 | 17 | 16 | 9 | 7 | 3 | 1 | 2 | 3 |
| 3 | 5 | 11 | 28 | 15 | 16 | 11 | 2 | 2 | 3 | 6 |
| 4 | 3 | 7 | 2 | 23 | 15 | 12 | 9 | 6 | 8 | 15 |
| 5 | 4 | 6 | 3 | 4 | 23 | 13 | 11 | 12 | 11 | 13 |
| 6 | 3 | 6 | 4 | 4 | 7 | 31 | 16 | 12 | 9 | 9 |
| 7 | 2 | 7 | 4 | 6 | 5 | 8 | 42 | 13 | 6 | 6 |
| 8 | 2 | 5 | 4 | 5 | 4 | 5 | 9 | 47 | 13 | 7 |
| 9 | 1 | 3 | 5 | 8 | 6 | 5 | 8 | 7 | 46 | 12 |
| 10 | 1 | 1 | 4 | 8 | 7 | 3 | 5 | 5 | 12 | 54 |
| Table B1: Drug classes in MediSim | |
| 1 | Anti-inflammatories |
| 2 | Asthma medications |
| 3 | Diabetes medications |
| 4 | Vasodilators & beta blockers |
| 5 | ACE inhibitors |
| 6 | Angiotensin IIs |
| 7 | Calcium channel blockers |
| 8 | Cholesterol & triglyceride reducers |
| 9 | Analgesic medications |
| 10 | Antipsychotics |
| 11 | Anxiolytics & hypnotics |
| 12 | Antidepressants |
| 13 | Stomach medications |
| 14 | Antibiotics |
| 15 | Antineoplastics |
| 16 | Genitourinary |
| 17 | Anti-epileptics |
| 18 | Direct acting antivirals |
| 19 | All other medications |
| Table B2: Health conditions in MediSim Note: NHPA = National Health Priority Area | ||
| 1 | NHPA Arthritis | Rheumatoid arthritis |
| Osteoarthritis | ||
| Arthritis NEC | ||
| 2 | NHPA Asthma | Asthma |
| 3 | NHPA Diabetes | Diabetes Mellitus — Type 1 |
| Diabetes mellitus — Type 2 | ||
| Diabetes unspecified | ||
| 4 | NHPA Heart or circulatory condition | Atherosclerosis |
| Fluid problems NOS | ||
| Varicose veins | ||
| Haemorrhoids | ||
| Other diseases of circulatory system | ||
| Hypertension | ||
| Heart disease | ||
| Stroke | ||
| Ill-defined symptomatic heart condition | ||
| Cerebrovascular disease | ||
| 5 | NHPA Mental | Nerves tension nervousness |
| Other mental disorders | ||
| Depression | ||
| Psychoses | ||
| Emotional problems NEC | ||
| Body image & eating disorders | ||
| Alcohol and drug dependence | ||
| Mental retardation specific delays in development | ||
| 6 | NHPA Cancer | Skin cancer |
| Breast cancer | ||
| Neoplasms NEC | ||
| 7 | NHPA Injury poisoning | Complications surgical NEC |
| Fractures | ||
| Dislocations, sprains and strains | ||
| Internal injuries | ||
| Open wounds | ||
| Bruising and crushing | ||
| Entry of foreign bodies | ||
| Burns and scalds | ||
| Poisoning other than by food | ||
| Other injuries | ||
| Injuries type not stated | ||
| 8 | Musculoskeletal system | Back problems |
| Other diseases musculoskeletal | ||
| Osteoporosis | ||
| Rheumatism | ||
| Absence of limbs or parts | ||
| Musculoskeletal deformities | ||
| 9 | Other endocrine | Thyroid disease |
| Gout | ||
| Obesity | ||
| Other endocrine and immune diseases | ||
| High blood sugar | ||
| High cholesterol | ||
| 10 | Respiratory system | Bronchitis/ Emphysema |
| Sinusitis | ||
| Cough or sore throat | ||
| Other diseases of respiratory system | ||
| Common cold | ||
| Hayfever | ||
| Influenza | ||
| 11 | Eye & adnexa | Blindness not corrected glasses |
| Other diseases of eye and adnexa | ||
| Visual disturbances | ||
| Cataracts | ||
| Glaucoma | ||
| Hypermetropia/Far-sighted | ||
| Myopia / Short-sighted | ||
| Presbyopia | ||
| 12 | Ear & mastoid | Otitis media |
| Deafness (complete/ partial) | ||
| Ear pain | ||
| Other diseases ear & mastoid proc | ||
| 13 | Nervous system | Epilepsy |
| Other diseases nervous system | ||
| Migraine | ||
| Paralysis | ||
| Other hereditary diseases nervous system | ||
| 14 | Infectious diseases | Herpes |
| Tinea | ||
| Other infectious diseases | ||
| 15 | Digestive system | Diarrhoea enteritis |
| Ulcer | ||
| Hernia | ||
| Constipation | ||
| Dental problems | ||
| Other diseases digestive system | ||
| 16 | Genito-urinary | Kidney diseases |
| Other diseases urinary system | ||
| Other diseases genital system | ||
| Disorders of menstruation | ||
| 17 | Skin subcutaneous tissue | Skin rash NOS |
| Eczema dermatitis | ||
| Acne | ||
| Other diseases skin and subcutaneous tissue | ||
| Psoriasis | ||
| 18 | Diseases of the blood | Diseases of blood |
| 19 | Complications childbirth | Complications of pregnancy etc |
| 20 | Other Signs & symptoms | Allergy NEC |
| Insomnia | ||
| Pyrexia | ||
| Localised swelling | ||
| Difficulty breathing | ||
| Chest pain | ||
| Abdominal pain | ||
| Heartburn | ||
| Dizziness | ||
| Headache due to stress | ||
| Headache unspecified or trivial | ||
| Virus | ||
| Other symptoms ill-defined conditions | ||
| 21 | Preventive measure | Immunisation |
| 22 | Congenital conditions | Congenital anomalies |
| 23 | Disability nec | Speech impediment NEC |
| Blackouts loss of cons NEC | ||
| Missing organs NEC | ||
| Table B3: Short term health conditions imputed in MediSim | |
| Musculoskeletal system | Back problems |
| Other diseases musculoskeletal | |
| Other endocrine system | Thyroid disease |
| Gout | |
| Other endocrine and immune diseases | |
| Respiratory system | Bronchitis/ Emphysema |
| Cough or sore throat | |
| Other diseases of respiratory system | |
| Common cold | |
| Influenza | |
| Eye & adnexa | Other diseases of eye and adnexa |
| Visual disturbances | |
| Ear & mastoid | Otitis media |
| Ear pain | |
| Other diseases ear & mastoid proc | |
| Nervous system | Other diseases nervous system |
| Migraine | |
| Infectious diseases | Herpes |
| Tinea | |
| Other infectious diseases | |
| Digestive system | Diarrhoea enteritis |
| Constipation | |
| Dental problems | |
| Other diseases digestive system | |
| Genito-urinary system | Kidney diseases |
| Other diseases urinary system | |
| Other diseases genital system | |
| Disorders of menstruation | |
| Skin and subcutaneous tissue | Skin rash NOS |
| Eczema dermatitis | |
| Acne | |
| Other diseases skin and subcutaneous tissue | |
| Psoriasis | |
| Diseases of the blood | Diseases of blood |
| Complications of childbirth | Complications of pregnancy etc |
| Other signs & symptoms | Allergy NEC |
| Insomnia | |
| Pyrexia | |
| Localised swelling | |
| Difficulty breathing | |
| Chest pain | |
| Abdominal pain | |
| Heartburn | |
| Dizziness | |
| Headache due to stress | |
| Headache unspecified or trivial | |
| Virus | |
| Other symptoms and ill-defined conditions | |
| Table C1: No. of annual scripts per person, by drug type, 2003 (percent distribution) | |||||||||||||||||||
| No. of scripts | Drug class | ||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| 1 | 39.23 | 37.11 | 8.53 | 15.00 | 7.20 | 7.19 | 7.55 | 6.66 | 37.70 | 17.73 | 35.87 | 18.24 | 23.98 | 40.60 | 16.93 | 30.68 | 22.50 | 64.80 | 30.19 |
| 2 | 14.13 | 16.61 | 9.33 | 8.04 | 4.85 | 4.48 | 4.77 | 4.49 | 18.05 | 10.42 | 14.12 | 9.25 | 10.92 | 23.84 | 12.63 | 17.46 | 12.45 | 9.99 | 13.85 |
| 3 | 8.26 | 8.52 | 8.71 | 6.85 | 4.18 | 3.91 | 4.10 | 3.98 | 9.69 | 8.94 | 8.35 | 7.10 | 6.63 | 12.07 | 9.69 | 16.57 | 11.59 | 5.45 | 8.45 |
| 4 | 6.31 | 6.34 | 8.59 | 6.31 | 3.99 | 3.68 | 3.93 | 3.77 | 6.73 | 7.54 | 5.94 | 5.93 | 5.13 | 7.71 | 9.54 | 9.83 | 10.51 | 3.88 | 6.28 |
| 5 | 4.35 | 4.52 | 5.87 | 5.40 | 3.99 | 3.86 | 4.14 | 3.97 | 4.55 | 6.24 | 4.37 | 5.47 | 4.41 | 4.58 | 8.73 | 4.90 | 7.91 | 2.99 | 4.63 |
| 6 | 3.69 | 3.97 | 5.83 | 7.05 | 4.73 | 4.62 | 5.22 | 4.77 | 3.57 | 6.61 | 3.58 | 6.02 | 4.58 | 3.11 | 11.64 | 4.89 | 6.69 | 2.81 | 3.86 |
| 7 | 3.32 | 2.89 | 5.60 | 6.04 | 4.05 | 4.02 | 4.26 | 4.26 | 2.71 | 5.43 | 3.54 | 5.70 | 3.79 | 2.03 | 5.74 | 3.28 | 5.15 | 1.86 | 3.16 |
| 8 | 3.06 | 2.45 | 4.38 | 4.02 | 4.19 | 3.97 | 3.95 | 4.66 | 2.22 | 4.33 | 3.03 | 4.91 | 3.49 | 1.44 | 3.85 | 2.07 | 3.73 | 1.61 | 2.65 |
| 9 | 2.76 | 2.01 | 3.41 | 3.19 | 4.49 | 4.68 | 4.35 | 5.74 | 1.77 | 3.87 | 2.21 | 4.48 | 3.60 | 1.02 | 2.96 | 1.58 | 2.60 | 1.31 | 2.26 |
| 10 | 2.89 | 1.80 | 3.46 | 3.52 | 6.15 | 6.61 | 6.09 | 8.40 | 1.48 | 3.85 | 1.89 | 4.59 | 4.40 | 0.75 | 2.88 | 1.54 | 2.21 | 1.22 | 2.04 |
| 11 | 3.39 | 1.54 | 3.44 | 6.08 | 12.60 | 13.32 | 13.07 | 15.47 | 1.26 | 4.75 | 1.70 | 5.32 | 6.94 | 0.57 | 3.04 | 1.40 | 1.86 | 1.30 | 1.90 |
| 12 | 3.57 | 1.48 | 3.38 | 10.70 | 22.95 | 23.72 | 24.40 | 21.68 | 1.15 | 6.27 | 1.61 | 6.55 | 10.01 | 0.46 | 3.80 | 1.85 | 1.69 | 1.40 | 1.91 |
| 13 – 24 | 4.95 | 7.11 | 21.97 | 15.30 | 16.27 | 15.85 | 13.96 | 11.96 | 6.19 | 12.81 | 10.25 | 15.41 | 11.65 | 1.63 | 7.86 | 3.84 | 8.49 | 1.38 | 12.34 |
| 25 – 36 | 0.09 | 2.06 | 6.51 | 2.11 | 0.35 | 0.09 | 0.20 | 0.18 | 1.62 | 1.07 | 2.11 | 0.91 | 0.41 | 0.17 | 0.60 | 0.10 | 2.03 | 0.00 | 4.12 |
| 37 – 48 | 0.01 | 0.84 | 0.87 | 0.32 | 0.01 | 0.00 | 0.01 | 0.01 | 0.63 | 0.12 | 0.66 | 0.09 | 0.04 | 0.03 | 0.09 | 0.01 | 0.47 | 0.00 | 1.46 |
| 49+ | 0.00 | 0.74 | 0.12 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.69 | 0.03 | 0.76 | 0.03 | 0.01 | 0.01 | 0.01 | 0.00 | 0.11 | 0.00 | 0.88 |
| Total | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| Drug class descriptions | |||||||||||||||||||
| 1 Anti-inflammatories | 6 Angiotensins | 11 Mental: anxiolytics & hypnotics | 16 Genitourinary | ||||||||||||||||
| 2 Asthma medications | 7 Calcium channel blockers | 12 Mental: antidepressants | 17 Anti-epileptics | ||||||||||||||||
| 3 Diabetes | 8 Cholesterol & trig | 13 Stomach medications | 18 Direct acting antivirals | ||||||||||||||||
| 4 Vasodilators | 9 Analgesics | 14 Antibiotics | 19 All other medications | ||||||||||||||||
| 5 ACE inhibitors | 10 Mental: antipsychotics | 15 Cancer: antineoplastics | |||||||||||||||||
| Table C2: Distribution of drug usage per specific health condition | ||||||||||||||||||||||
| Health group | Health condition | Drug class | ||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | All | |||
| 1 | NHPA Arthritis | Rheumatoid arthritis | 48 | . | . | 0 | . | 0 | . | 10 | 1 | 1 | 39 | 100 | ||||||||
| Osteoarthritis | 63 | . | 0 | 1 | 0 | 0 | 0 | 19 | 1 | 1 | 14 | 100 | ||||||||||
| Arthritis NEC | 63 | 1 | 1 | 0 | . | 1 | 0 | 16 | 0 | 1 | 18 | 100 | ||||||||||
| 2 | NHPA Asthma | Asthma | . | 98 | 2 | 100 | ||||||||||||||||
| 3 | NHPA Diabetes | Diabetes Mellitus — Type 1 | . | . | 97 | 0 | 0 | . | 1 | . | . | . | 0 | 1 | 100 | |||||||
| Diabetes mellitus — Type 2 | . | . | 93 | 0 | 2 | 1 | 1 | 0 | . | . | 0 | 3 | 100 | |||||||||
| Diabetes unspecified | 1 | . | 92 | 0 | 1 | . | 1 | 0 | . | . | 1 | 3 | 100 | |||||||||
| 4 | NHPA Heart circ | Atherosclerosis | 5 | . | . | 16 | . | 1 | 33 | 6 | 11 | . | . | 2 | 26 | 100 | ||||||
| Fluid problems NOS | 1 | . | 0 | 1 | . | . | 0 | . | . | 98 | 100 | |||||||||||
| Varicose veins | 9 | . | . | . | 1 | . | . | 14 | . | 4 | . | 72 | 100 | |||||||||
| Haemorrhoids | . | . | . | . | . | . | . | 4 | . | . | . | 96 | 100 | |||||||||
| Other dis circulatory system | 1 | 0 | . | 10 | 2 | 4 | 28 | 0 | 47 | 0 | . | . | 8 | 100 | ||||||||
| Hypertension | 0 | 0 | 0 | 20 | 27 | 0 | 25 | 0 | 2 | 0 | 0 | 0 | 25 | 100 | ||||||||
| Heart disease | 0 | 0 | 0 | 34 | 9 | 0 | 22 | 1 | 7 | 0 | 0 | 0 | 26 | 100 | ||||||||
| Stroke | 2 | . | . | 10 | 2 | 13 | 18 | 1 | 31 | . | . | . | 23 | 100 | ||||||||
| Ill-def symp heart cond | 1 | . | 0 | 25 | 9 | 0 | 18 | 1 | 5 | 0 | 0 | 0 | 40 | 100 | ||||||||
| Cerebrovasc dis | 9 | . | . | . | . | 29 | . | . | 11 | . | . | . | 51 | 100 | ||||||||
| 5 | NHPA Mental | Nerves tension nervousness | 11 | 43 | 39 | 8 | 100 | |||||||||||||||
| Other mental disorders | 9 | 5 | 74 | 11 | 100 | |||||||||||||||||
| Depression | 12 | 9 | 69 | 10 | 100 | |||||||||||||||||
| Psychoses | 60 | 11 | 15 | 14 | 100 | |||||||||||||||||
| Emotional problems NEC | 34 | 14 | 44 | 8 | 100 | |||||||||||||||||
| Body image & eating disorders | 100 | 100 | ||||||||||||||||||||
| Alcohol and drug dependence | . | . | . | . | . | 59 | 6 | 35 | 100 | |||||||||||||
| Mental ret delays devt | . | . | . | . | . | . | 15 | 79 | 6 | 100 | ||||||||||||
| 6 | NHPA Cancer | Skin cancer | 7 | 92.5 | 100 | |||||||||||||||||
| Breast cancer | 0 | 100 | 100 | |||||||||||||||||||
| Neoplasms NEC | 21 | 5 | 1 | 73.6 | 100 | |||||||||||||||||
| 7 | NHPA Injur pois | Complic surgical NEC | 1 | 1 | . | 2 | 0 | 1 | . | 13 | . | 3 | 4 | 59 | 16 | 100 | ||||||
| Fractures | 18 | 1 | . | . | . | . | . | 53 | . | 5 | 0 | 17 | 5 | 100 | ||||||||
| Disloc sprains and strains | 50 | . | . | . | . | 1 | . | 30 | . | 7 | 1 | 8 | 2 | 100 | ||||||||
| Internal injuries | 11 | . | . | . | . | . | . | 37 | . | 0 | 0 | 41 | 11 | 100 | ||||||||
| Open wounds | 0 | . | . | . | . | . | . | 12 | . | 0 | 0 | 70 | 19 | 100 | ||||||||
| Bruising and crushing | 23 | . | . | . | . | . | . | 43 | . | . | . | 27 | 7 | 100 | ||||||||
| Entry of foreign bodies | 0 | . | . | . | . | . | . | 5 | . | . | . | 75 | 20 | 100 | ||||||||
| Burns and scalds | 0 | . | . | . | . | . | . | 14 | . | . | . | 68 | 18 | 100 | ||||||||
| Poisoning other than by food | 0 | . | . | . | . | . | . | 0 | . | . | . | 79 | 21 | 100 | ||||||||
| Other injuries | 0 | 2 | . | . | . | 1 | 3 | 10 | . | 0 | . | 66 | 18 | 100 | ||||||||
| Injuries type not stated | 100 | . | . | . | . | . | . | 0 | . | . | . | 0 | 0 | 100 | ||||||||
| 8 | Muscoskel sys | Sciatica | 46 | . | . | . | . | . | 38 | . | 8 | 0 | 8 | 100 | ||||||||
| Dis of the interver disc | 29 | . | . | . | . | . | 51 | . | 6 | 4 | 11 | 100 | ||||||||||
| Back problems (unspecified) | 35 | . | . | 0 | . | . | 46 | 0 | 8 | 3 | 7 | 100 | ||||||||||
| Other dis musculoskel | 32 | . | 1 | 1 | . | 19 | 0 | 4 | 3 | 40 | 100 | |||||||||||
| Curvature of spine | 32 | . | . | . | . | 53 | . | 0 | 15 | 0 | 100 | |||||||||||
| Osteoporosis | 10 | . | . | . | . | 6 | . | 1 | 0 | 83 | 100 | |||||||||||
| Rheumatism | 48 | . | . | . | 6 | . | 3 | 11 | . | 0 | 0 | 32 | 100 | |||||||||
| Absence of limbs or parts | 0 | . | . | . | . | . | . | 19 | . | 0 | 0 | 81 | 100 | |||||||||
| Musculoskeletal deformities | 39 | . | . | . | . | . | . | 30 | . | 3 | 0 | 28 | 100 | |||||||||
| 9 | Other endocrine | Thyroid disease | 100 | 100 | ||||||||||||||||||
| Gout | 15 | 0 | . | 0 | 0 | 0 | . | 2 | . | 0 | . | 82 | 100 | |||||||||
| Obesity | . | . | . | . | . | . | 2 | 3 | . | . | . | 95 | 100 | |||||||||
| Oth endocrine and imm | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 98 | 100 | |||||||||
| High blood sugar | . | . | 91 | . | . | . | . | . | . | . | . | 9 | 100 | |||||||||
| High cholesterol | . | . | 0 | 0 | 1 | 1 | 0 | 97 | 1 | . | . | . | 1 | 100 | ||||||||
| 10 | Respirat sys | Bronchitis/ Emphysema | . | 66 | 1 | . | 0 | . | 0 | . | 0 | 0 | 17 | 0 | 16 | 100 | ||||||
| Sinusitis | 0 | 52 | . | . | . | . | . | 3 | 0 | . | . | 22 | 1 | 21 | 100 | |||||||
| Cough or sore throat | 0 | 19 | . | . | . | . | . | 3 | . | . | . | 39 | 1 | 37 | 100 | |||||||
| Other dis respiratory system | 0 | 24 | . | . | 1 | 1 | . | 2 | 0 | 0 | . | 36 | 1 | 34 | 100 | |||||||
| Common cold | . | 12 | . | . | . | . | . | 8 | . | . | . | 41 | 1 | 39 | 100 | |||||||
| Hayfever | . | 49 | . | . | . | . | . | 1 | . | 0 | 0 | 25 | 1 | 24 | 100 | |||||||
| Influenza | . | 8 | . | . | . | . | . | 4 | . | . | . | 45 | 1 | 42 | 100 | |||||||
| 11 | Visual dist | Blindness not corr glasses | 20 | . | . | 1 | . | . | . | . | . | . | 79 | 100 | ||||||||
| Other dis eye and adnexa | . | 2 | . | 3 | 0 | . | 2 | . | . | . | 60 | 1 | 33 | 100 | ||||||||
| Visual disturbances | . | . | . | 2 | . | . | . | . | 13 | . | 85 | 100 | ||||||||||
| Cataracts | . | . | . | 8 | . | . | . | . | . | . | 92 | 100 | ||||||||||
| Glaucoma | . | . | . | 27 | 1 | . | 0 | . | . | . | 72 | 100 | ||||||||||
| Hypermetropia/Far-sighted | . | . | . | . | . | . | . | . | . | . | 100 | 100 | ||||||||||
| Myopia / Short-sighted | . | . | . | . | . | . | . | . | . | . | 100 | 100 | ||||||||||
| Presbyopia | . | . | . | . | . | . | . | . | . | . | 100 | 100 | ||||||||||
| 12 | Ear & mastoid | Otitis media | . | 1 | . | . | . | . | . | 1 | . | 0 | . | 62 | 1 | 34 | 100 | |||||
| Deafness (complete/ partial) | . | . | . | . | . | 48 | . | . | . | . | . | 34 | 18 | 100 | ||||||||
| Ear pain | 3 | 2 | . | . | . | . | . | 15 | . | . | . | 51 | 1 | 28 | 100 | |||||||
| Oth dis ear & mastoid proc | . | 1 | . | 1 | . | 12 | . | 1 | 1 | 7 | 1 | 50 | 1 | 27 | 100 | |||||||
| 13 | Nerv sys | Epilepsy | 0 | . | . | 0 | . | . | . | . | 0 | 5 | 1 | 93 | 100 | |||||||
| Other dis nervous system | 16 | . | . | . | . | . | . | 19 | 1 | 1 | 15 | 48 | 100 | |||||||||
| Migraine | 3 | . | . | 9 | . | 2 | . | 30 | 0 | 1 | 4 | 50 | 100 | |||||||||
| Paralysis | . | . | . | . | . | . | . | 14 | 12 | 10 | . | 64 | 100 | |||||||||
| Oth hered dis nerv sys | 1 | . | . | 1 | 1 | 2 | . | 7 | . | 7 | 5 | 76 | 100 | |||||||||
| 14 | Infectious dis | Herpes | . | . | . | . | . | . | . | . | . | . | 2 | 98 | 100 | |||||||
| Tinea | . | . | . | . | . | . | . | . | . | . | . | 100 | 100 | |||||||||
| Other infectious dis | 1 | 3 | . | . | . | . | . | 2 | . | . | 2 | 92 | 100 | |||||||||
| 15 | Digestive sys | Diarrhoea enteritis | . | . | . | . | . | . | 1 | 2 | . | 0 | 0 | 75 | 2 | 19 | 100 | |||||
| Ulcer | 0 | 0 | . | 0 | . | 0 | . | 0 | . | . | 0 | 40 | 49 | 10 | 100 | |||||||
| Hernia | . | . | . | 0 | . | 0 | . | 2 | . | . | 1 | 96 | 100 | |||||||||
| Constipation | . | . | . | 1 | 3 | . | . | . | . | . | 1 | 77 | 19 | 100 | ||||||||
| Dental problems | 2 | 2 | . | . | . | . | . | 24 | . | 1 | . | 72 | 100 | |||||||||
| Other dis digestive system | 1 | . | . | 0 | 0 | 1 | 0 | 4 | 0 | 1 | 1 | 92 | 100 | |||||||||
| 16 | Genito-urinary | Kidney diseases | 1 | 0 | . | 3 | 2 | 1 | 1 | 3 | . | . | 1 | 89 | 100 | |||||||
| Other dis urinary system | . | . | 1 | 0 | 1 | 0 | . | . | . | 1 | 7 | 76 | 4 | 10 | 100 | |||||||
| Other dis genital system | 3 | 1 | . | 0 | . | 0 | . | 5 | . | 1 | 1 | 85 | 4 | 100 | ||||||||
| Disorders of menstruation | 6 | . | . | 0 | . | . | . | 2 | . | 0 | 1 | 88 | 4 | 100 | ||||||||
| 17 | Skin subcut tiss | Skin rash NOS | . | . | . | . | . | . | . | 0 | . | . | . | 100 | 100 | |||||||
| Eczema dermatitis | 0 | 1 | . | . | . | . | . | . | 0 | 0 | 0 | 99 | 100 | |||||||||
| Acne | . | . | . | . | . | . | . | . | . | . | . | 100 | 100 | |||||||||
| Oth dis skin and subcut tiss | 0 | . | . | . | . | 0 | . | 2 | . | 0 | 0 | 8 | 89 | 100 | ||||||||
| Psoriasis | 0 | 1 | . | . | . | . | 0 | 0 | . | 1 | . | 98 | 100 | |||||||||
| 18 | Dis of the blood | Diseases of blood | 2 | . | . | . | . | 3 | . | . | . | . | . | 95 | 100 | |||||||
| 19 | Complic chldbrth | Complic of pregnancy etc | . | 13 | . | . | . | . | . | . | . | . | . | 69 | 18 | 100 | ||||||
| 20 | Oth symptoms | Allergy NEC | 1 | 33 | . | . | . | . | . | 1 | . | 1 | 1 | 64 | 100 | |||||||
| Insomnia | 0 | . | . | 0 | . | . | . | 3 | 1 | 75 | 16 | 4 | 100 | |||||||||
| Pyrexia | 4 | . | . | . | . | . | . | 21 | . | . | . | 25 | 25 | 25 | 100 | |||||||
| Localised swelling | 27 | . | . | . | . | . | . | . | . | . | . | 73 | 100 | |||||||||
| Difficulty breathing | . | 51 | . | 2 | 11 | 15 | 5 | 1 | . | . | 1 | . | 15 | 100 | ||||||||
| Chest pain | 9 | 8 | . | 23 | . | 15 | 12 | . | 17 | . | . | 2 | 15 | 100 | ||||||||
| Abdominal pain | 7 | . | . | 1 | . | 1 | . | 14 | . | . | . | 77 | 100 | |||||||||
| Heartburn | 2 | . | . | . | . | . | . | . | . | . | . | 98 | 100 | |||||||||
| Dizziness | . | . | . | . | . | 10 | . | 10 | 2 | . | 4 | 75 | 100 | |||||||||
| Headache due to stress | . | . | . | . | . | . | . | 48 | . | 23 | . | 28 | 100 | |||||||||
| Headache unspec or trivial | 4 | 0 | . | 1 | . | 0 | . | 86 | 0 | 0 | 2 | 5 | 100 | |||||||||
| Virus | 1 | 4 | . | . | 0 | . | . | 12 | . | . | . | 83 | 100 | |||||||||
| Oth symp ill-defined cond | 2 | 3 | . | 3 | 0 | 0 | 1 | 9 | 1 | 5 | 5 | 71 | 100 | |||||||||
| 21 | Preventive | Checkup/ examination | 8 | . | 5 | . | 2 | . | . | . | . | . | 4 | 81 | 100 | |||||||
| Contraceptive management | . | . | . | . | 0 | . | . | . | . | 1 | . | 99 | 100 | |||||||||
| Counselling | . | . | . | . | . | . | . | . | . | . | . | 100 | 100 | |||||||||
| Immunisation | . | . | . | . | 8 | . | . | . | . | . | . | 92 | 100 | |||||||||
| 22 | Congenital | Congenital anomalies | 21 | . | . | . | 2 | . | . | 10 | . | . | . | 67 | 100 | |||||||
| 23 | Disability | Speech impediment NEC | . | 29 | . | . | . | . | . | . | . | 71 | . | 0 | 100 | |||||||
| Blackouts loss of cons NEC | . | . | . | . | . | . | . | . | . | 42 | . | 58 | 100 | |||||||||
| Missing organs NEC | . | 49 | . | . | . | . | . | . | . | . | . | 51 | 100 | |||||||||
| Due to rounding, totals do not always add up to 100. Source: NATSEM estimates using 1995 NHS. | ||||||||||||||||||||||
| Table C3: Distribution of persons by concession card status and age: actual vs. model estimates (percent) | ||||||
| Medicare Australia 2003 | Model 2003-04 | % Difference | ||||
| Concessional | General | Concessional | General | Concessional | General | |
| All | 100 | 100 | 100 | 100 | ||
| 0-4 | 1 | 5 | 2 | 6 | 0 | 0 |
| 5-9 | 2 | 5 | 2 | 6 | 0 | 0 |
| 10-14 | 2 | 5 | 3 | 5 | 0 | -1 |
| 15-19 | 4 | 6 | 4 | 7 | 0 | -1 |
| 20-24 | 4 | 5 | 4 | 5 | 0 | 1 |
| 25-29 | 6 | 4 | 6 | 4 | 0 | 0 |
| 30-34 | 8 | 5 | 7 | 4 | 1 | 0 |
| 35-39 | 8 | 5 | 9 | 5 | 0 | 0 |
| 40-44 | 11 | 5 | 13 | 5 | -2 | 0 |
| 45-49 | 13 | 5 | 15 | 4 | -2 | 1 |
| 50-54 | 15 | 4 | 15 | 4 | 0 | 0 |
| 55-59 | 14 | 5 | 11 | 6 | 4 | 0 |
| 60-64 | 8 | 7 | 6 | 7 | 2 | 0 |
| 65-69 | 2 | 9 | 2 | 10 | 1 | -1 |
| 70-74 | 1 | 9 | 1 | 9 | 0 | 0 |
| 75+ | 1 | 16 | 1 | 14 | 0 | 2 |
| Table C4: Average scripts per person by concession card status, gender and age group: actual vs. model estimates | |||||||
| Medicare Australia 2003 | Model 2003-04 | % Difference | |||||
| Gender | Age group | Concessional | General | Concessional | General | Concessional | General |
| All | 21.5 | 9.6 | 21.9 | 8.7 | -2 | 10 | |
| Males | 0-4 | 4.2 | 2.5 | 4.4 | 2.6 | -5 | -2 |
| 5-9 | 4.1 | 2.7 | 4.4 | 2.8 | -7 | -4 | |
| 15-24 | 5.1 | 3.8 | 5.4 | 3.4 | -6 | 12 | |
| 25-39 | 10.1 | 5.6 | 10.0 | 4.9 | 1 | 13 | |
| 40-64 | 22.1 | 13.0 | 22.9 | 11.1 | -3 | 17 | |
| 65 + | 35.6 | 26.2 | 35.4 | 18.6 | 1 | 41 | |
| Females | 0-4 | 3.7 | 2.5 | 4.0 | 2.5 | -8 | -1 |
| 5-9 | 3.5 | 2.6 | 3.9 | 2.6 | -10 | -3 | |
| 15-24 | 5.8 | 3.6 | 5.7 | 3.3 | 2 | 7 | |
| 25-39 | 10.0 | 5.2 | 9.5 | 4.7 | 5 | 12 | |
| 40-64 | 24.6 | 10.8 | 24.0 | 10.1 | 3 | 6 | |
| 65 + | 41.7 | 19.5 | 41.7 | 19.8 | 0 | -1 | |
| Table C5: Average no. of scripts by concession card status and drug class: actual vs. model estimates | |||||
| Medicare Australia 2003 | Model 2003-04 | ||||
| Concessional | General | Concessional | General | ||
| Ave. no. scripts per person | 21.5 | 9.6 | 21.9 | 8.7 | |
| No. of drugs classes per person | 3.4 | 1.9 | 3.5 | 1.7 | |
| Ave. no. scripts/person/drug | 6.3 | 5.2 | 6.3 | 5.2 | |
| 1 Anti-inflammatories | 4.6 | 3.1 | 4.6 | 3.1 | |
| 2 Asthma medications | 6.5 | 3.3 | 6.5 | 3.3 | |
| 3 Diabetes | 10.7 | 5.6 | 10.7 | 5.6 | |
| 4 Vasodilators | 8.3 | 4.6 | 8.3 | 4.6 | |
| 5 ACE inhibitors | 9.5 | 8.2 | 9.5 | 8.2 | |
| 6 Angiotensins | 9.4 | 8.5 | 9.4 | 8.5 | |
| 7 Calcium channel blockers | 9.3 | 7.7 | 9.3 | 7.7 | |
| 8 Cholesterol & trig. reducers | 9.4 | 8.0 | 9.4 | 8.0 | |
| 9 Analgesics | 5.0 | 5.3 | 5.0 | 5.2 | |
| 10 Antipsychotics | 6.9 | 5.8 | 6.9 | 5.7 | |
| 11 Anxiolytics & hypnotics | 6.1 | 3.1 | 6.1 | 3.1 | |
| 12 Antidepressants | 7.5 | 6.4 | 7.5 | 6.4 | |
| 13 Stomach medications | 7.0 | 5.2 | 7.0 | 5.2 | |
| 14 Antibiotics | 2.9 | 2.3 | 2.9 | 2.3 | |
| 15 Cancer: antineoplastics | 5.7 | 5.8 | 5.7 | 5.8 | |
| 16 Genitourinary | 3.9 | 2.7 | 3.9 | 2.7 | |
| 17 Anti-epileptics | 6.1 | 5.2 | 6.1 | 5.2 | |
| 18 Direct acting antivirals | 2.3 | 2.7 | 2.3 | 2.7 | |
| 19 All other medications | 7.8 | 4.4 | 7.8 | 4.4 | |
AUSTRALIAN BUREAU OF STATISTICS (2001a) Income Distribution, Australia, Catalogue no. 6523.0, Canberra.
AUSTRALIAN BUREAU OF STATISTICS (2001b) Government Benefits, Taxes and Household Income, Australia, ABS Catalogue No. 6537.0, Australian Bureau of Statistics, Canberra.
AUSTRALIAN BUREAU OF STATISTICS (2003a) National Health Survey: User's Guide, 2001, Catalogue No. 4363.0.55.001, Canberra.
AUSTRALIAN BUREAU OF STATISTICS (2003b) Occasional Paper: Long-term Health Conditions — A Guide to Time Series Comparability from the National Health Survey, Australia (ABS Catalogue no. 4816.0.55.001).
AUSTRALIAN BUREAU OF STATISTICS (1996) National Health Survey User's Guide, Australia, 1995, Catalogue no. 4363.0.
AUSTRALIAN INSTITUTE OF HEALTH AND WELFARE (2006) Health Inequalities in Australia: Morbidity, Health Behaviour, Risk Factors and Health Service Use, Canberra, Australia.
BARR, RS and Turner, JS (1978) 'A new, linear programming approach to microdata file merging', 1978 Compendium of Tax Research, Office of the Treasury, Washington, D.C.
BARR, RS, Stewart, WH and Turner, JS (1982) 'An Empirical Evaluation of Statistical Matching Strategies', mimeograph, Edwin L. Cox School of Business, Southern Methodist University, Dallas, Texas.
BRITT, H, Miller, G C, Knox, S, Charles, J, Valenti, L, Pan, Y, BROWN, L, Abello, A and Harding, A (2006) Which Australian Families Benefit from the Australian Pharmaceuticals Benefit Scheme's Safety Net?, Agenda, 13(3), pp. 211-224.
BROWN, L (2005a) "Distributional Impacts of the Pharmaceutical Benefit Scheme's Safety Net", Presented at the Australia Health Economist's Conference 29-30th of September 2005, Auckland.
BROWN , L (2005b) "Distributional Impacts of the PBS in 2005-06: An Investment in Australian Families", The 3rd Annual Conference on The Future of the Pharmaceutical Benefits Scheme, 24-25 August 2005, Sydney
BROWN, L and Harding, A (2005) 'The new frontier of health and aged care', Ch. 10. in Quantitative Tools for Microeconomic Policy Analysis, Conference Proceedings, Canberra, 17-18 November 2004, Productivity Commission, Canberra.
BROWN, L and Harding, A (2002) Social Modelling and Public Policy: Application of Microsimulation Modelling in Australia. Journal of Artificial Societies and Social Simulation, 5 (4) 6 https://www.jasss.org/5/4/6.html
COHEN, M (1991) 'Statistical matching and microsimulation models'. In Citro, C F and Hanushek, E A (eds), The Uses of Microsimulation Modelling, Review and Recommendations, vol. 1, National Academy Press, Washington
COMMONWEALTH DEPARTMENT OF THE TREASURY (2005) Budget Strategy and Outlook 2005-06, Budget Paper No. 1, Treasury, Commonwealth of Australia, May.
CREEDY, J (2001) Tax modelling. Economic Record, 77 (237), pp. 189-202.
GUPTA, A (2007) 'Pharmasim Model', in Gupta, A and Harding, A (eds.). Modelling Our Future: Population Ageing, Health and Aged Care, International Symposia in Economic Theory and Econometrics, vol. 16, Amsterdam, Elsevier B. V.
HARDING, A and Gupta, A (2007) 'Introduction and Overview', in Harding, A and Gupta, A. (eds), Modelling Our Future: Population Ageing, Social Security and Taxation, International Symposia in Economic Theory and Econometrics, vol. 15, Elsevier B. V., Amsterdam, pp. 1-29.
HARDING, A, Abello, A, Brown, L and Phillips, B (2004) The Distributional Impact of Government Outlays on the Australian Pharmaceutical Benefits Scheme in 2001-02, Economic Record, 80 (Special Issue) S83-S96.
HARDING, A, Percival, R, Schofield, D, and Walker, A (2002) The lifetime distributional impact of government health outlays, Australian Economic Review, 35(4), pp.363-379.
MAYNARD, A and Bloor, K (2003), Dilemmas in regulation of the Market for Pharmaceuticals, Health Affairs, vol. 22:3 pp.31-41.
MEDICAL NEWS TODAY (2006), Share of pharmaceutical spending in total healthcare expenditure remains high across most EU countries', 30 Feb 2006, http://www.medicalnewstoday.com/articles/37057.php
MOISE, P and Docteur, E (2007) Pharmaceutical Pricing and Reimbursement Policies in Sweden, Health Technical Paper no. 28, OECD.
MORIARTY, C and Scheuren, F (2001) 'Statistical Matching: Pitfalls of Current Procedures', in Proceedings of the Annual Meeting of the American Statistical Association, August 5-9, 2001.
NGUYEN, L and A. Gupta (2007) 'A Microsimulation Model to Evaluate Hypothetical Drug Plans', Abstract of paper to be presented at the 1st General Conference of the International Microsimulation Association, Vienna, 20-22 August 2007 (available from http://www.euro.centre.org/ima2007/Submissions.pdf)
PARIS, V. and Docteur, E. (2006) 'Pharmaceutical Pricing and Reimbursement Policies in Canada', Health Technical Paper no. 24, OECD.
PERCIVAL, R, Abello, A and Vu, Q N (2007) 'STINMOD (Static Incomes Model), in Gupta, A. and Harding, A. (eds.), Modelling Our Future: Population Ageing, Health and Aged Care, International Symposia in Economic Theory and Econometrics, vol. 16, Amsterdam, Elsevier B. V.
OECD Health Data (2007) http://www.oecd.org/health/healthdata
OECD (2005) http://www.oecd.org/document/25/0,2340,en_2649_201185_34967193_1_1_1_1,00.html
OECD OBSERVER (2003), 'Bitter Pill', January 2004, No. 240/241 December 2003 http://www.oecdobserver.org/news/fullstory.php/aid/1171/Bitter_pill.html
RADNER, D B, Allen, R, Gonzalez, M E, Jabine, T B and Muller, H J (1980) "Report on Exact and Statistical Matching Techniques," Statistical Policy Working Paper 5, U.S. Government Printing Office.
RASSLER, S (2002) Statistical Matching: A Frequentist Theory, Practical Applications, and Alternative Bayesian Approaches, Springer-Verlag.
RODGERS, W (1984) An Evaluation of Statistical Matching, Journal of Business and Economic Statistics, vol. 2, No. 1, January 1984.
SUTHERLAND, H (2007) 'EUROMOD — The Tax-Benefit Microsimulation Model for the European Union, in Gupta, A and Harding, A (eds.). Modelling Our Future: Population Ageing, Health and Aged Care, International Symposia in Economic Theory and Econometrics, vol. 16, Amsterdam, Elsevier B. V.
SUTHERLAND, H, Taylor, R and Gomulka, J (2002) Combining household income and expenditure data in policy simulations, Review of Income and Wealth, vol. 48:4, pp. 517-536.
TAYLOR, R, Gomulka, J and Sutherland, H (2000) Creating Order out of Chaos? Identifying Homogeneous Groups of Households across Multiple Datasets, paper presented at the 26th General Conference of the International Association for Research in Income and Wealth, Cracow, Poland, 27 August to 2 September.
TECHNICAL WORKING GROUP ABS-NATSEM COLLABORATION ON STATISTICAL MATCHING (2004) Statistical Matching of the HES and NHS: An Exploration of Issues in the Use of Unconstrained and Constrained Approaches in Creating a Basefile for a Microsimulation Model of the Pharmaceutical Benefits Scheme, ABS Methodology Advisory Committee Paper, June 2004.
THURECHT, L, Walker, A, Harding, A and Pearse, J (2005) 'The 'Inverse Care Law', Population Ageing and the Hospital System: A Distributional Analysis', Economic Papers, vol 24:1, pp.1-17.
TURELL, G and Mathers, C (2000) 'Socioeconomic status and health in Australia', Medical Journal of Australia, vol 172, pp.434-438.
WALKER, A (2000) Distributional impact of higher patient contributions to Australia's Pharmaceutical Benefits Scheme, Australian Health Review, vol. 23:2, pp. 32-46.
WALKER, A and Abello, A (2000) Changes in the Health Status of Low Income Groups in Australia, 1977-78 to 1995, Discussion Paper no. 52, National Centre for Social and Economic Modelling, University of Canberra
WALKER, A, Abello, A and Harding, A (2000) 'The impact of demographic and other changes on expenditure on pharmaceutical benefits in 2020 in Australia', in Mitton, L, Sutherland, H and Weeks, M (eds), Microsimulation Modelling for Policy Analysis: Challenges and Innovations, Cambridge University Press, pp. 149-71.
WALKER A, Pearse, J, Thurecht, L and Harding, A. (2006) 'Hospital admissions by socio-economic status: does the 'inverse care law' apply to older Australians?' Australian and New Zealand Journal of Public Health, vol 30:5, pp.467-473.
WOODWARD, M (2005), Epidemiology: Study Design and Data Analysis, Chapman & Hall/CRC Press, pp. 12-13.
YOSHIZOE, Y and Araki, M (1999) Use of statistical matching for household surveys in Japan. In 52nd Session of the International Statistical Institute, Helsinki, Finland
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2008]