
Ugo Merlone, Michele Sonnessa and Pietro Terna (2008)
Horizontal and Vertical Multiple Implementations in a Model of Industrial Districts
Journal of Artificial Societies and Social Simulation
vol. 11, no. 2 5
<https://www.jasss.org/11/2/5.html>
For information about citing this article, click here
Received: 04-Aug-2007 Accepted: 06-Jan-2008 Published: 31-Mar-2008

 Abstract
Abstract
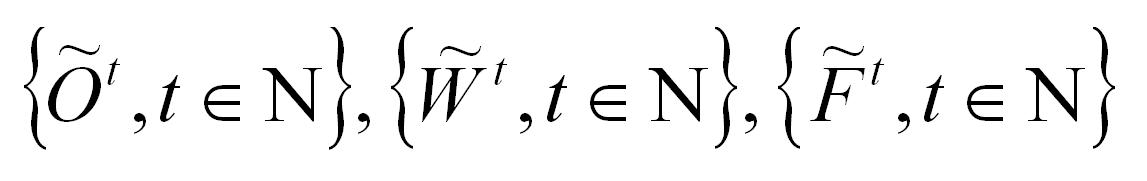
|
(1) |
describing respectively the orders generation, new workers entry, and new firms entry, then the evolution of the system can be formalized as follows:
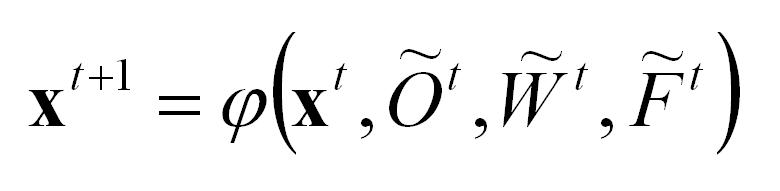
|
(2) |
|
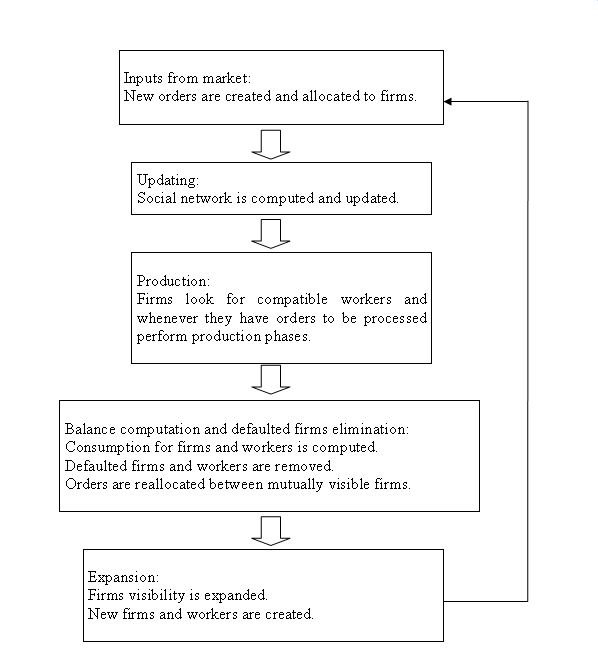
| Scheme 1. Scheme of a simulation turn |
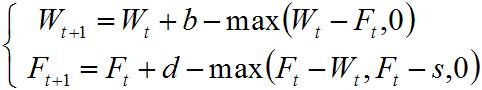
|
(3) |
Where
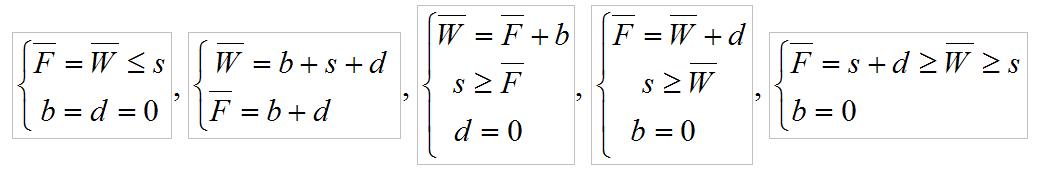
|
(4) |
|
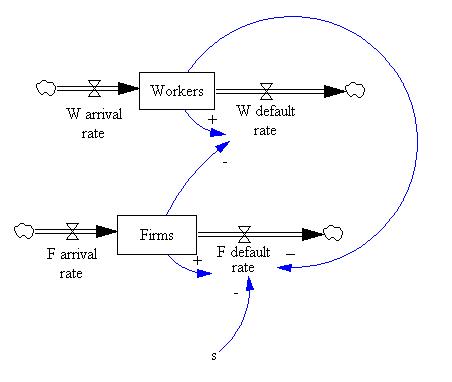
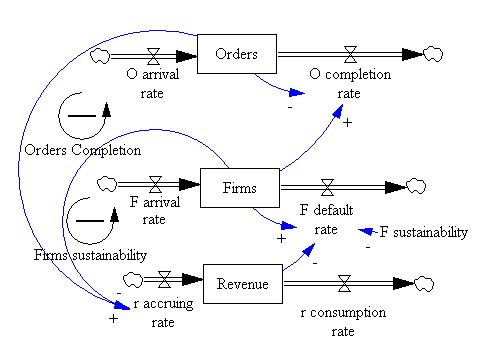
| Figure 1. The System Dynamic version of the piecewise linear model |
|
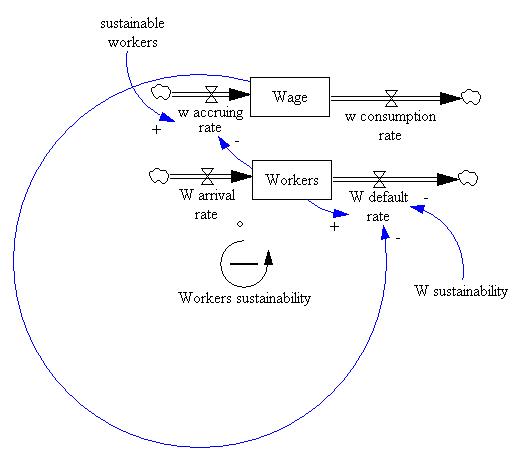
| Figure 2. The System Dynamic model of workers population |
|
| Figure 3. The System Dynamic model of firms population |
|
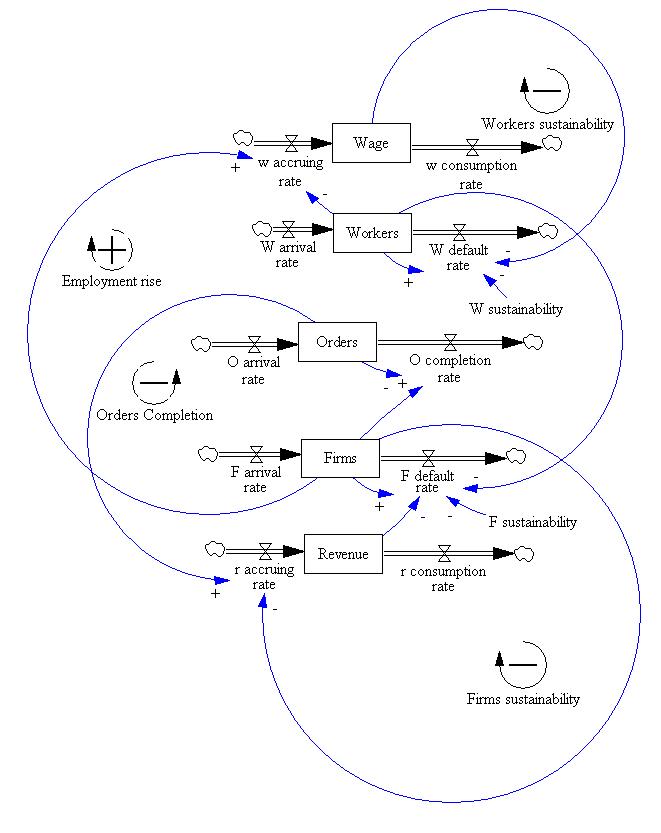
| Figure 4. The System Dynamic model of the workers and firms population |
The Agent-Based Approach
|
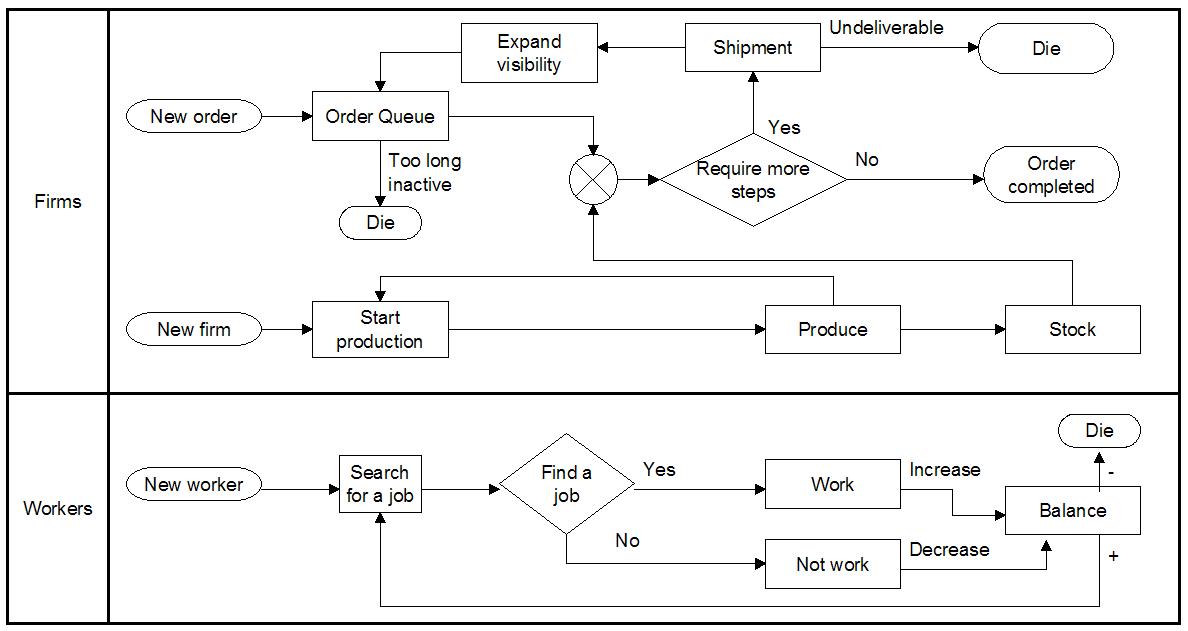
| Figure 5. The dynamic process of independent populations |
|
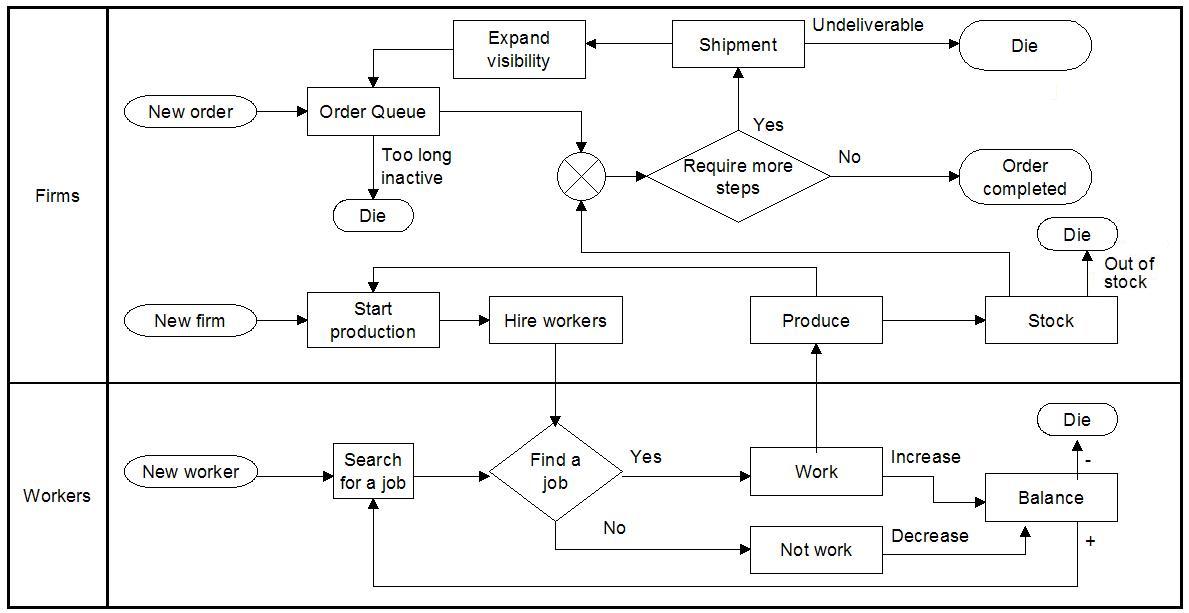
| Figure 6. The dynamic process of the co-evolving model |
|
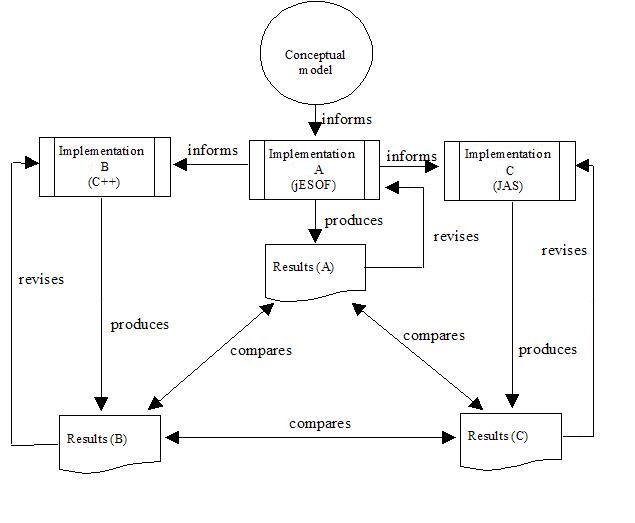
| Figure 7. Dependent multiple implementation |
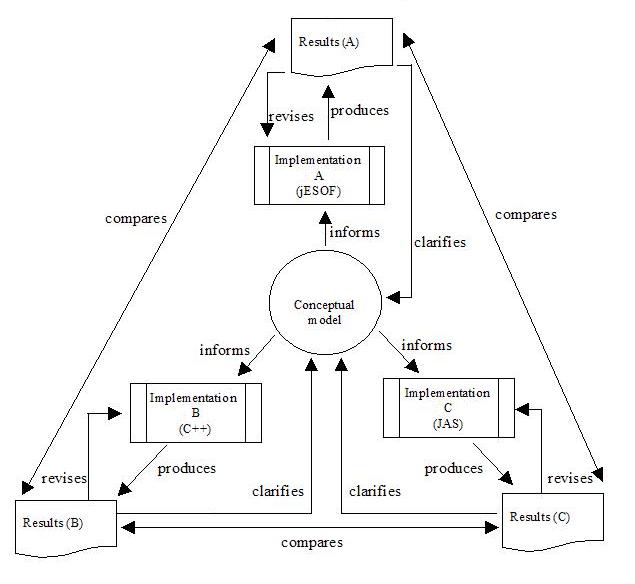 |
| Figure 8. Independent multiple implementation |

|
| Figure 9. Java Code implementation for a computational firm |
|
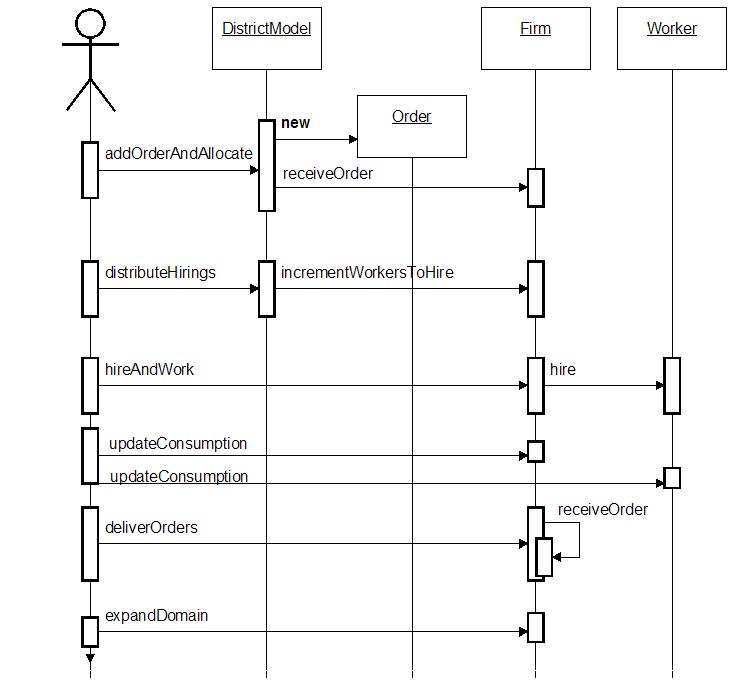
| Figure 10. Time-sequence UML diagram of the model implemented with JAS |

|
| Figure 11. The method getPlayersInMyDomain() from DomainPlayer class |

|
| Figure 12. C++ implementation code for a simulation turn |
|
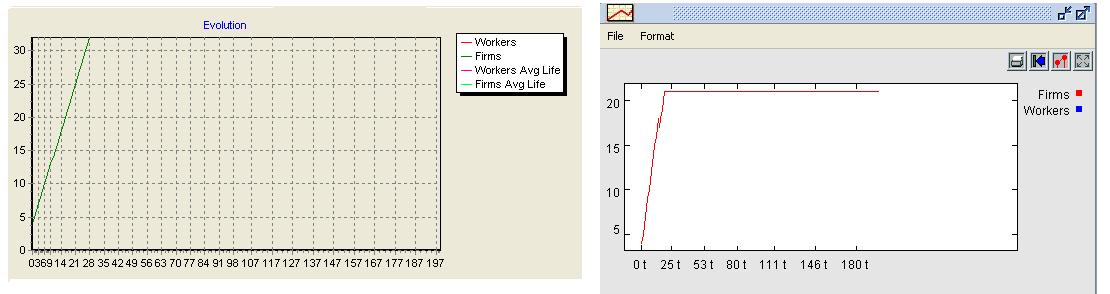
| Figure 13. Results in the deterministic order allocation for firm population |
|
| Figure 14. Results in the deterministic order allocation for firm population (top-bottom) |
|
| Figure 15. Results in the deterministic order allocation for firm population (bottom-top) |
|
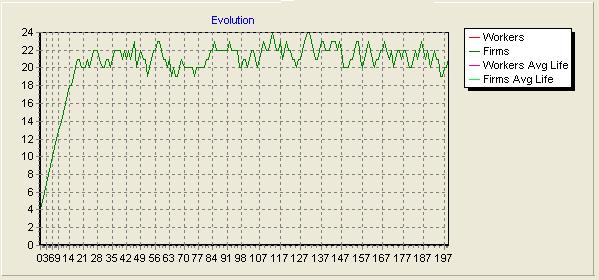
| Figure 16. Number of firms over time, for random length order with top-bottom firm list rotation |
|
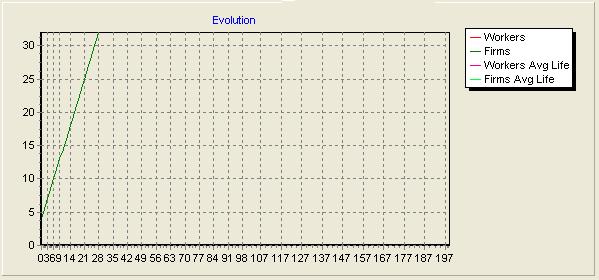
| Figure 17. Number of firms over time, for random length order with bottom-top firm list rotation |

|
| Figure 18. Firm list evolution, for random length order with top-bottom firm list rotation |
2 In particular for firms, the equilibrium is expected to be similar to an economic cycle.
3 In the jES Open Foundation version of the model we have also instrumental layers showing separately the presence of workers for each type of skill, but, obviously, the two implementations are equivalent in terms of modeling.
4 We remark that the employee-employer relationship is negotiated at each simulation turn and therefore is not permanent.
5 The careful reader will notice that the graphical representation we provide is similar to the one proposed in Edmonds and Hales (2003); this is not a coincidence.
6 The generator is taken from the COLT library ( http://dsd.lbl.gov/~hoschek/colt-download/releases/) and more precisely is referred to the class cern.jet.random.engine.MersenneTwister.
AXELROD, R (1984). The Evolution of Cooperation. New York: Basic Books.
BANKS, J, Carson II, J S, Nelson B L, and Nicol D M, (2005). Discrete-Event System Simulation. Fourth Edition, Upper Saddle River, NJ: Pearson Prentice Hall.
BECATTINI, G, Pyke, F, Sengenberger, W (Eds.) (1992). Industrial Districts and Inter-firm Co-operation in Italy. Geneva: International Institute for Labour Studies.
BECATTINI, G (2003). "From the industrial district to the districtualisation of production activity: some considerations". In F. Belussi, G. Gottardi, and E. Rullani (Eds.), The Technological Evolution of Industrial Districts . Dordrecht: Kluwer Academic Publisher.
BECKER, P (2005). "Bad Pointers". C/C++ Users Journal. 23(9), 37-41.
BELUSSI, F, Gottardi, G (Eds.) (2000). Evolutionary Patterns of Local Industrial Systems. Towards a Cognitive Approach to the Industrial District. Sydney: Ashgate.
BRENNER, T (2002). "Simulating the Evolution of Localised Industrial Clusters: An Identification of the Basic Mechanisms". Presented at IG2002, Sophia Antipolis, France, January 18-19, 2002.
CARBONARA, N (2004). "Innovation processes within geographical clusters: a cognitive approach". Technovation, 24, 17-28.
CARBONARA, N (2005). "Information and communication technology and geographical clusters: opportunities and spread". Technovation, 25, 213-222.
CARLEY, K M and Prietula, M J (1994). Computational Organization Theory. Hillsdale. N.J: Lawrence Erlbaum Associates.
CERRUTI, U, Giacobini, M, Merlone, U (2005). "A New Framework to Analyze Evolutionary 2×2 Symmetric Games". Proceedings of the IEEE 2005 Symposium on Computational Intelligence and Games, April 4-6 2005 Essex University, Colchester, Essex, UK.
EDMONDS, B and Hales, D (2003). "Replication, Replication and Replication: Some Hard Lessons from Model". Journal of Artificial Societies and Social Simulation, 5(4) 11 https://www.jasss.org/6/4/11.html
FLAKE, G W (1988). The Computational Beauty of Nature. Cambridge (MA): The MIT Press.
FRANK, S A (1997). Models of Symbiosis. The American Naturalist. 150(S), S80-S99.
GAROFOLI, G (1981). "Lo sviluppo delle aree "periferiche" nell'economia italiana degli anni '70". L'industria 3, 391- 404.
GAROFOLI, G (1991). "Local Networks, Innovation and Policy in Italian Industrial Districts". In E. Bergman, G. Mayer and F. Tödtling (Eds.), Regions Reconsidered. Economic Networks Innovation and Local Development in Industrialized Countries. London: Mansell.
GAROFOLI, G (1992). "Industrial Districts: Structure and Transformation". In G Garofoli (Ed.), Endogeneous Development and Southern Europe. Avebury: Aldershot, 49-60.
GAYLORD, R J , and D'Andria, L J (1998). Simulating Society. New York: Springer-Verlag.
HASTINGS, A (1997). Population Biology. Concepts and Models. New York: Springer-Verlag.
HOFBAUER, J, and Sigmund, K (1998). Evolutionary Games and Population Dynamics. Cambridge: Cambridge University Press.
LAW, A M and Kelton, W D (2000). Simulation modeling and analysis. Boston: Mc-Graw-Hill.
LOTKA, A J (1925). Elements of physical biology. Baltimore: Williams and Wilkins Co.
LAZZARETTI, L, and Storai, D (1999). "Il distretto come comunità di popolazioni organizzative. Il caso Prato". Prato: Quaderni IRIS n.6.
LAZZERETTI, L and Storai, D (2003). "An ecology based interpretation of district 'complexification': the Prato district evolution from 1946 to 1993". In F Belussi, G Gottardi, and E Rullani (Eds.), The Technological Evolution of Industrial Districts . Dordrecht: Kluwer Academic Publisher.
MASS, N (1980). "Stock and flow variables and the dynamics of supply and demand". In Randers, J (ed.), Elements of System Dynamics Method. Waltham, Ma: Pegasus Communications
MATSUMOTO, M and Nishimura, T (1998). "Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator". ACM Transactions on Modeling and Computer Simulation (TOMACS), Vol.8(1) p. 3-30.
MERLONE, U and Terna, P (2006). "Population Symbiotic Evolution in a Model of Industrial Districts", in Rennard J.P (ed.), Handbook of Research on Nature Inspired Computing for Economics and Management, Idea Group Inc.
PIVA, M, Santarelli, E, Vivarelli, M (2003). The Skill Bias Effect of Technological and Organizational Change: Evidence and Policy Implications. IZA Discussion Paper, 934.
POLHILL, J G, Izquieredo, L R, Gotts, N M (2005). "The Ghost in the Model (and other effects of the floating points arithmetic)". Journal of Artificial Societies and Social Simulation, 8(1) 5. https://www.jasss.org/8/1/5.html
PRESS, W H, Teulkolsky, S A, Vetterling, W T, Flannery, B P (2002). Numerical Recipes in C++. Cambridge: Cambridge University Press.
RICHIARDI, M, Leombruni, R, Sonnessa, M and Saam, N (2006). "A Common Protocol for Agent-Based Social Simulation". Journal of Artificial Societies and Social Simulation 9(1) 15 https://www.jasss.org/9/1/15.html
ROYAMA, T (1992). Analytical population dynamics. New York : Chapman and Hall.
SORENSON, O, Rivkin, J W and Fleming, L (2004). "Complexity, Networks and Knowledge Flow", Working Paper.
SQUAZZONI, F and Boero, R (2002). "Economic Performance, Inter-Firm Relations and Local Institutional Engineering in a Computational Prototype of Industrial Districts". Journal of Artificial Societies and Social Simulation, 5(1)1 https://www.jasss.org/5/1/1.html.
STERMAN, J D (2000). Business Dynamics: System Thinking and Modeling for a Complex World". Boston, MA: Irwin McGraw-Hill.
VOLTERRA, V (1926). Variazioni e fluttuazioni del numero d'individui in specie animali conviventi. Roma: Mem. R. Accad. Naz. dei Lincei. VI(2).
ZHANG, J (2003). "Growing Silicon Valley on a landscape: an agent-based approach to high-tech industrial clusters". Journal of Evolutionary Economics 13. 529-548.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2008]