
Umberto Gostoli (2008)
A Cognitively Founded Model of the Social Emergence of Lexicon
Journal of Artificial Societies and Social Simulation
vol. 11, no. 1 2
<https://www.jasss.org/11/1/2.html>
For information about citing this article, click here
Received: 31-May-2006 Accepted: 28-Sep-2007 Published: 31-Jan-2008

 Abstract
Abstract
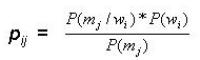
|
(1) |
However, with the same set of words and meanings, we can build a M x W matrix of conditional probabilities P(m/w) each element of which represents the conditional probability that given a word wi we can expect the meaning mj. The generic element of this matrix pji is given by the formula (2):
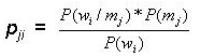
|
(2) |
A speaker who uses this second conditional probability matrix, in a certain way, adopts the point of view of the hearer, asking itself what is the meaning that the hearer would expect to be associated to the word sent by the speaker. It is the so-called obverter learning introduced by Oliphant and Batali (1997).
|
| Figure 1. A mental model |
| Figure 2: A generic database | ||||
| Var. 1 | Var. 2 | Var. 3 | Var. 4 | Dep. Var. |
| 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 |
| ... | ... | .... | .... | ... |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 | 2 |
| .... | .... | .... | .... | ... |
| 2 | 1 | 1 | 1 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 | 2 |
| Dep. Var. = W1*Var. 1 + W2*Var. 2 + W3*Var. 3 + W4*Var. 4 |
where W1, W2, W3 and W4 are the weights of the independent variables.
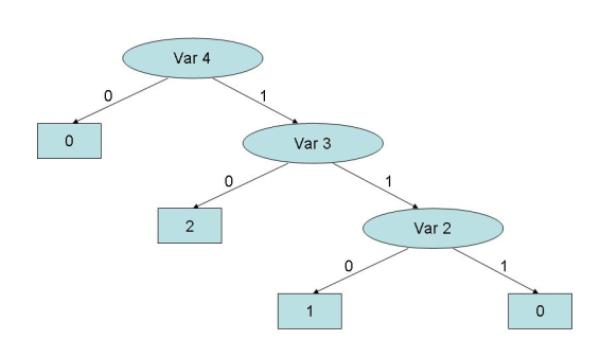
|
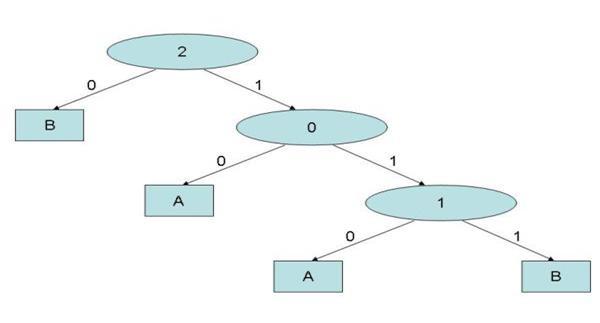
| Figure 3. The decision tree resulting from data mining analysis performed on the database shown in Figure 2 |
| E = - ( n 0/ N)log r ( n 0/ N) - ( n 1/ N)log r ( n 1/ N) | (3) |
For example, if we look at the dependent variable column of the database of Figure 10, we see that there are 8 instances that have value 0 and 12 instances that have value 1. The entropy of this database is given by:
| E(D) = - (8/20)log2 (8/20) - (12/20) log2 (12/20) |
| info(D) = 1- 0.971 = 0.029 |
| Figure 4 A database | ||||
| I1 | I2 | I3 | V | |
| 1 | 0 | 2 | 1 | 1 |
| 2 | 0 | 1 | 0 | 1 |
| 3 | 0 | 2 | 0 | 1 |
| 4 | 1 | 2 | 1 | 0 |
| 5 | 0 | 1 | 1 | 0 |
| 6 | 1 | 0 | 1 | 0 |
| 7 | 1 | 2 | 1 | 1 |
| 8 | 0 | 0 | 0 | 1 |
| 9 | 0 | 0 | 0 | 0 |
| 10 | 1 | 0 | 1 | 1 |
| 11 | 1 | 1 | 0 | 0 |
| 12 | 1 | 1 | 1 | 0 |
| 13 | 1 | 1 | 0 | 0 |
| 14 | 1 | 2 | 0 | 1 |
| 15 | 0 | 1 | 0 | 1 |
| 16 | 1 | 1 | 1 | 0 |
| 17 | 0 | 1 | 0 | 1 |
| 18 | 0 | 1 | 0 | 1 |
| 19 | 0 | 2 | 0 | 1 |
| 20 | 1 | 0 | 1 | 1 |
|
E[V(I1=0)] = - (2/10)log2 (2/10) - (8/10) log2 (8/10) = 0.722 E[V(I1=1)] = - (6/10)log2 (6/10) - (4/10) log2 (4/10) = 0.971 |
| Figure 5: Figure 5: V(I1=0) |
| V(I1=0) |
| 1 |
| 1 |
| 1 |
| 0 |
| 1 |
| 0 |
| 1 |
| 1 |
| 1 |
| 1 |
| Figure 6: Figure 6: V(I1=1) |
| V(I1=1) |
| 0 |
| 0 |
| 1 |
| 1 |
| 0 |
| 0 |
| 0 |
| 1 |
| 0 |
| 1 |
| E(I1) = (10/20) * 0.722 + (10/20) * 0.971 = 0.846 |
| info(I1) = 1- 0.846 = 0.154 |
|
E[V(I2=0)] = - (2/5)log2 (2/5) - (3/5) log2 (3/5) = 0.971 E[V(I2=1)] = - (5/9)log2 (5/9) - (4/9) log2 (4/9) = 0.994 E[V(I2=2)] = - (1/6)log2 (1/6) - (5/6) log2 (5/6) = 0.649
|
| Figure 7: V(I2=0) |
| V(I2=0) |
| 0 |
| 1 |
| 0 |
| 1 |
| 1 |
| Figure 8: V(I2=1) |
| V(I2=1) |
| 1 |
| 0 |
| 0 |
| 0 |
| 0 |
| 1 |
| 0 |
| 1 |
| 1 |
| Figure 9: V(I2=2) |
| V(I2=2) |
| 1 |
| 1 |
| 0 |
| 1 |
| 1 |
| 1 |
| E(I2) = (5/20) * 0.971 + (9/20) * 0.994 + (6/20) * 0.649 = 0.885 |
| info(I2) = 1- 0.885 = 0.115 |
| info(I3) = 1- 0.912 = 0.088 |
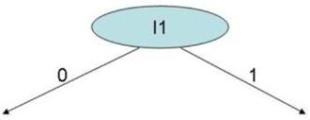
|
| Figure 10. First node |
| Figure 11: D(I1 = 0) | |||
| I2 | I3 | V | |
| 1 | 2 | 1 | 1 |
| 2 | 1 | 0 | 1 |
| 3 | 2 | 0 | 1 |
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 1 |
| 6 | 0 | 0 | 0 |
| 7 | 1 | 0 | 1 |
| 8 | 1 | 0 | 1 |
| 9 | 1 | 0 | 1 |
| 10 | 2 | 0 | 1 |
| Figure 12: D(I1 = 1) | |||
| I2 | I3 | V | |
| 1 | 2 | 1 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 2 | 1 | 1 |
| 4 | 0 | 1 | 1 |
| 5 | 1 | 0 | 0 |
| 6 | 1 | 1 | 0 |
| 7 | 1 | 0 | 0 |
| 8 | 2 | 0 | 1 |
| 9 | 1 | 1 | 0 |
| 10 | 0 | 1 | 1 |
| Figure 13: Agent Tom experiences' database | |||
| Symbol 0 | Symbol 1 | Symbol 2 | Number |
| A | B | A | 5 |
| B | A | A | 0 |
| B | B | A | 7 |
| ... | .... | .... | ... |
| B | A | B | 2 |
| B | B | A | 6 |
| A | A | A | 6 |
| .... | .... | .... | ... |
| A | B | B | 4 |
| A | B | B | 3 |
| A | A | B | 2 |
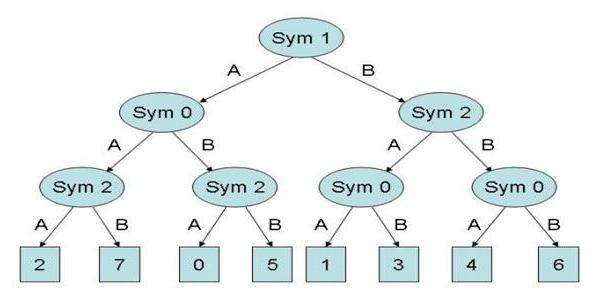
|
| Figure 14. Player S Mental Model |
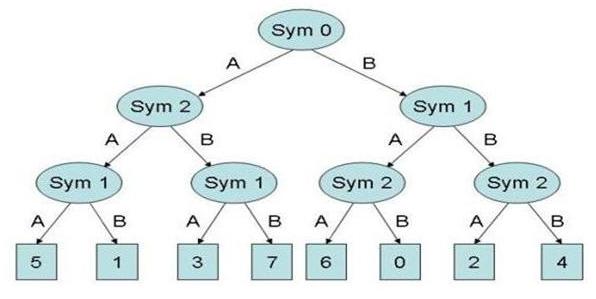
|
| Figure 15. Player R Mental Model |
|
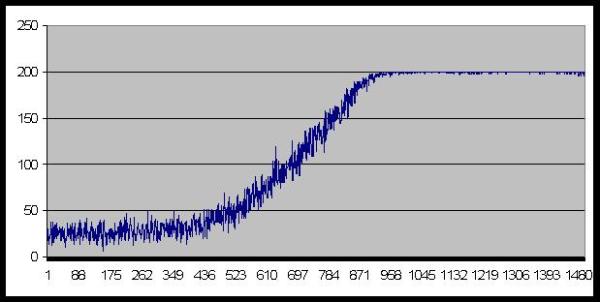
| Figure 16. Number of agents who coordinate successfully |
|
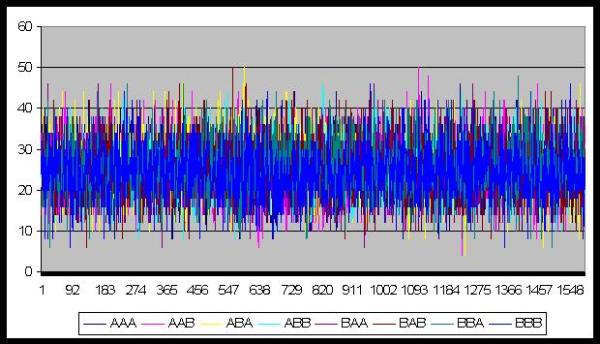
| Figure 17. Number of messages chosen |
|
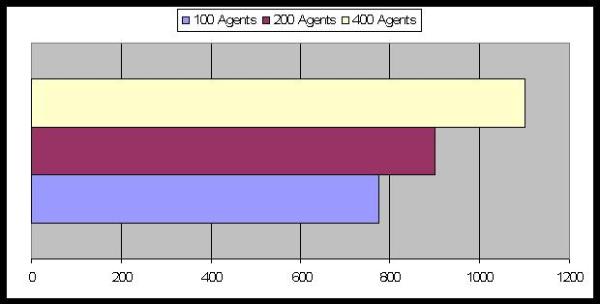
| Figure 18. Average Number of Periods to reach equilibrium: the effect of the population's size |
|
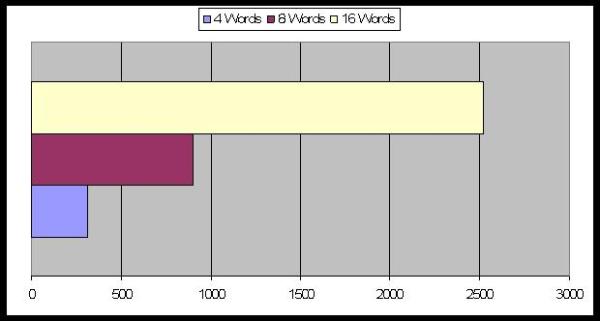
| Figure 19. Average Number of Periods to reach equilibrium: the effect of the words' number |
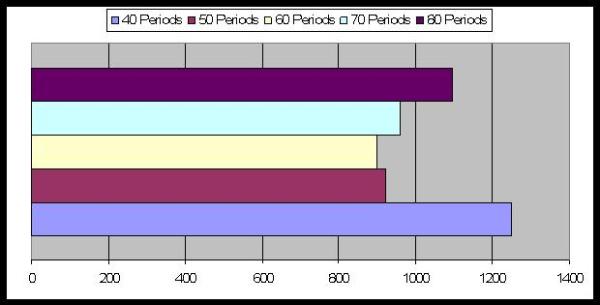
|
| Figure 20. Average Number of Periods to reach equilibrium: the effect of the memory's length |
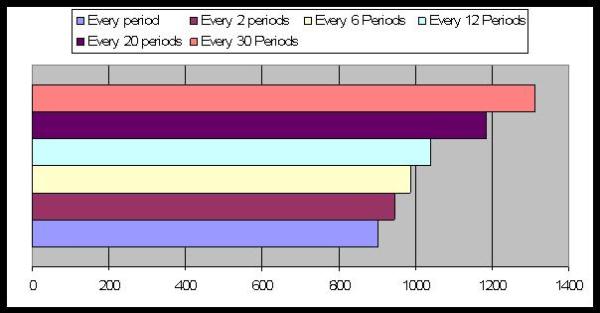
|
| Figure 21. Average Number of Periods to reach equilibrium: the mental model updating lag |
I wish to thank my PhD supervisor Prof. Roberto Scazzieri for his constant support during all the stages of the research.
I am grateful to Prof. Nigel Gilbert who, during the three-month research period I spent at the University of Surrey, gave me precious advice that helped me to critically reconsider my work, allowing me to amend some of its weak points.
I wish to thank Prof. Pietro Terna and his PhD students for the invaluable help they gave me regarding the technical aspects of the agent-based simulation.
import java.util.ArrayList;
import java.util.Random;
public class Agent {
private int Address;
private int Object;
private int Age;
private boolean Forecast;
private boolean DT;
private int[] Word;
private int MemoryLenght;
private int Period;
private int[][] Sym;
private int[] Meaning;
private int Root;
private int[] SnNode;
private int[][] TrNode;
private int[][][] TrNodeLeaf;
private int Guess;
private int numberObjects;
private int wordLenght;
private int numberSymbols;
Random rand = new Random();
private int numAgents;
private int LearningPeriod;
public Agent (int i, int no, int wl, int ns, int p, int m) {
rand.setSeed(Society.get_Seed()*(i+1));
Address = i;
numberObjects = no;
wordLenght = wl;
numberSymbols = ns;
numAgents = p;
Period = 0;
MemoryLenght = m;
LearningPeriod = MemoryLenght-2;
Root = -1;
DT = false;
Sym = new int[wordLenght][MemoryLenght];
Meaning = new int[MemoryLenght];
Word = new int[wordLenght];
SnNode = new int[numberSymbols];
TrNode = new int[numberSymbols][numberSymbols];
TrNodeLeaf = new int [numberSymbols][numberSymbols][numberSymbols];
}
public void build_DecisionTree() {
if ( Period > LearningPeriod && rand.nextDouble() < 0.2 ) {
DT = true;
double[][] cs = new double[wordLenght][numberSymbols];
double[][][] csm = new double[wordLenght][numberSymbols][numberObjects];
double[] infoVal = new double[wordLenght];
int[][][][] countWord = new int[numberSymbols][numberSymbols][numberSymbols][numberObjects];
for ( int i = 0; i < numberSymbols; i++ ) {
for ( int j = 0; j < numberSymbols; j++ ) {
for ( int y = 0; y < numberSymbols; y++ ) {
for ( int k = 0; k < numberObjects; k++ ) {
countWord[i][j][y][k] = 0;
}}}}
for ( int j = 0; j < wordLenght; j++ ) {
infoVal[j] = 0;
for ( int i = 0; i < numberSymbols; i++ ) {
cs[j][i] = 0;
for ( int z = 0; z < numberObjects ; z++ ) {
csm[j][i][z] = 0;
}}}
for ( int j = 0; j < wordLenght; j++ ) {
for ( int y = 0; y < numberSymbols; y++ ) {
for ( int i = 0; i < Period ; i++ ) {
if ( Sym[j][i] == y )
cs[j][y] += 1;
for ( int z = 0; z < numberObjects ; z++ ) {
if ( Sym[j][i] == y && Meaning[i] == z )
csm[j][y][z] += 1;
}}}}
for ( int j = 0; j < wordLenght; j++ ) {
for ( int i = 0; i < numberSymbols; i++ ) {
for ( int z = 0; z < numberObjects ; z++ ) {
if ( cs[j][i] != 0 && csm[j][i][z] != 0 )
infoVal[j] +=
cs[j][i]*(-1*(csm[j][i][z]/cs[j][i])*Math.log(csm[j][i][z]/cs[j][i]));
}}}
double bestIV = infoVal[0];
for ( int j = 1; j < wordLenght; j++ ) {
if ( infoVal[j] < bestIV ) {
bestIV = infoVal[j];
}}
int[] check2 = new int[wordLenght];
for ( int k = 0; k < wordLenght; k++ ) {
check2[k] = 0;
}
for ( int h = 0; h < wordLenght; h++ ) {
if ( infoVal[h] == bestIV )
check2[h] = 1;
}
int f;
do {
f = rand.nextInt(wordLenght);
}while (check2[f] == 0);
Root = f;
int countSR;
for ( int q = 0; q < numberSymbols; q++ ) {
countSR = 0;
for ( int r = 0; r < Period ; r++ ) {
if ( Sym[Root][r] == q )
countSR += 1;
}
int[][] srSym = new int[wordLenght-1][countSR];
int[] srMea = new int[countSR];
for ( int j = 0, y = 0; j < wordLenght-1 && y < wordLenght; ) {
int p = 0;
if ( Root == y )
y += 1;
for ( int i = 0; i < Period ; i++ ) {
if ( Sym[Root][i] == q ) {
srSym[j][p] = Sym[y][i];
srMea[p] = Meaning[i];
p += 1;
}
}
j += 1;
y += 1;
}
double[][] sr_cs = new double[wordLenght-1][numberSymbols];
double[][][] sr_csm =
new double[wordLenght-1][numberSymbols][numberObjects];
double[] sr_infoVal = new double[wordLenght-1];
for ( int j = 0; j < wordLenght-1; j++ ) {
sr_infoVal[j] = 0;
for ( int i = 0; i < numberSymbols; i++ ) {
sr_cs[j][i] = 0;
for ( int z = 0; z < numberObjects ; z++ ) {
sr_csm[j][i][z] = 0;
}}}
for ( int j = 0; j < wordLenght-1; j++ ) {
for ( int y = 0; y < numberSymbols; y++ ) {
for ( int i = 0; i < countSR ; i++ ) {
if ( srSym[j][i] == y )
sr_cs[j][y] += 1;
for ( int z = 0; z < numberObjects ; z++ ) {
if ( srSym[j][i] == y && srMea[i] == z )
sr_csm[j][y][z] += 1;
}}}}
for ( int j = 0; j < wordLenght-1; j++ ) {
for ( int i = 0; i < numberSymbols; i++ ) {
for ( int z = 0; z < numberObjects ; z++ ) {
if ( sr_cs[j][i] != 0 && sr_csm[j][i][z] != 0 )
sr_infoVal[j] += sr_cs[j][i]*
(-1*(sr_csm[j][i][z]/sr_cs[j][i])*Math.log(sr_csm[j][i][z]/sr_cs[j][i]));
}}}
double sr_bestIV = sr_infoVal[0];
for ( int j = 1; j < wordLenght-1; j++ ) {
if ( sr_infoVal[j] < sr_bestIV )
sr_bestIV = sr_infoVal[j];
}
for ( int k = 0; k < wordLenght-1; k++ ) {
check2[k] = 0;
}
for ( int h = 0; h < wordLenght-1; h++ ) {
if ( sr_infoVal[h] == sr_bestIV )
check2[h] = 1;
}
do {
f = rand.nextInt(wordLenght-1);
} while (check2[f] == 0);
SnNode[q] = f;
if ( Root == 0 ) {
SnNode[q] += 1;
}
if ( Root == 1) {
if ( SnNode[q] > 0 )
SnNode[q] += 1;
}
for ( int k = 0; k < numberSymbols; k++ ) {
for ( int i = 0; i < wordLenght; i++ ) {
if ( i != Root && i != SnNode[q] )
TrNode[q][k] = i;
}
for ( int v = 0; v < numberSymbols; v++ ) {
for ( int h = 0; h < numberObjects; h++ ) {
for ( int t = 0; t < Period; t++ ) {
if ( Sym[Root][t] == q && Sym[SnNode[q]][t] == k &&
Sym[TrNode[q][k]][t] == v && Meaning[t] == h )
countWord[q][k][v][h] += 1;
}
int bestMeaning = 0;
for ( int h = 0; h < numberObjects; h++ ) {
if ( countWord[q][k][v][h] > bestMeaning )
bestMeaning = countWord[q][k][v][h];
}
int[] countTNL = new int[numberObjects];
for ( int h = 0; h < numberObjects; h++ ) {
countTNL[h] = 0;
}
for ( int h = 0; h < numberObjects; h++ ) {
if ( countWord[q][k][v][h] == bestMeaning )
countTNL[h] = 1;
}
do {
f = rand.nextInt(numberObjects);
}while(countTNL[f] == 0 );
TrNodeLeaf[q][k][v] = f;
}}}}}
public void update_DataSet() {
for ( int j = 0; j < wordLenght; j++ ) {
for ( int i = Period-1; i > -1 ; i-- ) {
Sym[j][i+1] = Sym[j][i];
}
}
for ( int i = Period-1; i > -1 ; i-- ) {
Meaning[i+1] = Meaning[i];
}
for ( int j = 0; j < wordLenght; j++ ) {
Sym[j][0] = Word[j];
}
Meaning[0] = Object;
if ( Period < MemoryLenght-1 )
Period += 1;
}
public void think_Word() {
if ( DT == true ) {
int c = 0;
int[][] word = new int[numberSymbols*numberSymbols*numberSymbols][wordLenght];
for ( int i = 0; i < numberSymbols; i++ ) {
for ( int j = 0; j < numberSymbols; j++ ) {
for ( int k = 0; k < numberSymbols; k++ ) {
if ( TrNodeLeaf[i][j][k] == Object ) {
word[c][Root] = i;
word[c][SnNode[i]] = j;
word[c][TrNode[i][j]] = k;
c += 1;
}}}}
if ( c != 0 ) {
int f = rand.nextInt(c);
for ( int j = 0; j < wordLenght; j++ ) {
Word[j] = word[f][j];
} }
else {
for ( int j = 0; j < wordLenght; j++ ) {
Word[j] = rand.nextInt(numberSymbols);;
}}}
else {
for ( int j = 0; j < wordLenght; j++ ) {
Word[j] = rand.nextInt(numberSymbols);;
}}}
public void draw_Object() {
Object = rand.nextInt(numberObjects);
}
public void guess_Object() {
if ( DT == true ) {
int a = Word[Root];
int b = Word[SnNode[a]];
int c = Word[TrNode[a][b]];
Guess = TrNodeLeaf[a][b][c];
if ( Guess == -1 )
Guess = rand.nextInt(numberObjects);
}
else {
Guess = rand.nextInt(numberObjects);
}
if ( Guess == Object )
Forecast = true;
else
Forecast = false;
}
public void get_Guess(Agent a) {
Guess = a.guess();
if ( Guess == Object )
Forecast = true;
else
Forecast = false;
}
private int guess() {
return Guess;
}
public int get_Object() {
return Object;
}
public int[] get_Sig() {
return Word;
}
public void get_Message(Agent a) {
Object = a.get_Object();
int[] word = a.get_Sig();
for ( int j = 0; j < wordLenght; j++ ) {
Word[j] = word[j];
}
}
public boolean get_Forecast() {
return Forecast;
}
public int get_Word0() {
return Word[0];
}
public int get_Word1() {
return Word[1];
}
public int get_Word2() {
return Word[2];
}
}
import java.util.LinkedList;
import java.util.Random;
public class Society {
private static final long Seed = 918273;
private static int numAgents = 200;
private static int Memory = 60;
private static int numberObjects = 8;
private static int wordLenght = 3;
private static int numberSymbols = 2;
private static int TotalPayOff = 0;
private static int Time = -1;
static java.util.List<number> urn;
static Random rand = new Random();
public static void main(String[] args) {
rand.setSeed(Seed);
urn = new LinkedList<number>();
Agent[] agent = new Agent[numAgents];
for ( int i = 0; i < numAgents; i++ ) {
agent[i] = new Agent(i, numberObjects, wordLenght, numberSymbols, numAgents, Memory);
}
for (int t = 0; t < 2000; t++) {
for (int i = 0; i < numAgents; i++ ) {
urn.add(new Number(i));
}
for (int i = 0; i < numAgents/2; i++ ) {
int f;
int r;
Number n;
f = rand.nextInt(urn.size());
n = urn.get(f);
r = n.draw_Number();
urn.remove(f);
Agent a = agent[r];
f = rand.nextInt(urn.size());
n = urn.get(f);
r = n.draw_Number();
urn.remove(f);
Agent b = agent[r];
a.build_DecisionTree();
b.build_DecisionTree();
a.draw_Object();
a.think_Word();
b.get_Message(a);
b.guess_Object();
a.get_Guess(b);
a.update_DataSet();
b.update_DataSet();
}
int tpo = 0;
for (int i = 0; i < numAgents; i++ ) {
Agent a = agent[i];
if ( a.get_Forecast() == true )
tpo += 1;
}
}
}
public static long get_Seed() {
return Seed;
}
public static int get_Time() {
return Time;
}
}
OLIPHANT, M. (1999) "The Learning Barrier: Moving from Innate to Learned Systems of Communication" Adaptive Behaviour: 7, 371-384. OLIPHANT, M. and Batali, J. (1997) "Learning and the Emergence of Coordinated Communication" Centre for Research on Language Newsletter, 11(1).
SMITH, A. D. M. (2001) "Establishing Communication Systems without Explicit Meaning Transmission" Proceedings of the 6th European Conference on Artificial Life. Eds. J. Kelemen and P. Sosik. Berlin: Springer-Verlag.
STEELS, L. (1996) "Emergent Adaptive Lexicons" From Animals to Animats 4: Proceedings of the Fourth International Conference On Simulating Adaptive Behaviour. Ed. P. Maes. Cambridge, Mass.: MIT Press.
STEELS, L. and Kaplan, F. (2002) "Bootstrapping Grounded Word Semantics" Linguistic Evolution through Language Acquisition: Formal and Computational Models. Ed. T. Briscoe. Cambridge: Cambridge University Press.
STEELS, L. and Vogt P. (1997) "Grounding Adaptive Language Games in Robotic Agents" Proceedings of the Fourth European Conference on Artificial Life. Eds. C. Husbands and I. Harvey. Cambridge, Mass.: MIT Press.
VOGT, P. (2001) "The Impact of Non-Verbal Communication on Lexicon Formation" Proceedings of the 13th Belgian/Netherlands Artificial Intelligence Conference. Eds. B. Kröse, M. De Rijke, G. Schreiber and M. Van Someren.
Vogt, P. (2002) "The Physical Symbol Grounding Problem" Cognitive Systems Research, 3(3): 429-457.
VOGT, P. and Coumans, H. (2003) "Investigating Social Interaction Strategies for Bootstrapping Lexicon Development" Journal of Artificial Societies and Social Simulation, 6(1)4 https://www.jasss.org/6/1/4.html.
YANCO, H. and Stein, L. (1993) "An Adaptive Communication Protocol for Cooperating Mobile Robots" From Animals to Animats 2:Proceedings of the Second International Conference On Simulating Adaptive Behaviour. Eds. J. A. Meyer, H. L. Roitblat and S. Wilson. Cambridge, Mass.: MIT Press.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2008]