
Stéphane Airiau, Sabyasachi Saha and Sandip Sen (2007)
Evolutionary Tournament-Based Comparison of Learning and Non-Learning Algorithms for Iterated Games
Journal of Artificial Societies and Social Simulation
vol. 10, no. 3 7
<https://www.jasss.org/10/3/7.html>
For information about citing this article, click here
Received: 06-Dec-2005 Accepted: 09-Jun-2007 Published: 30-Jun-2007

 Abstract
Abstract

|
| Figure 1. Modified Tournament Selection Algorithm for a population of N agents |
| 
|
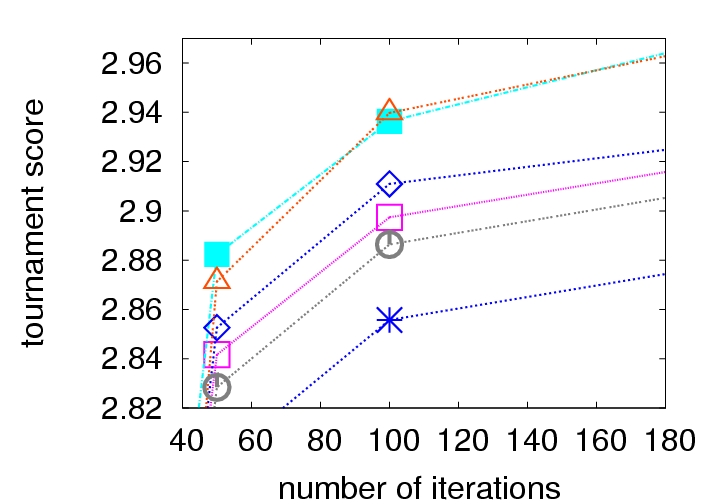
| Zoom around iteration 100 | |
|---|---|
| |
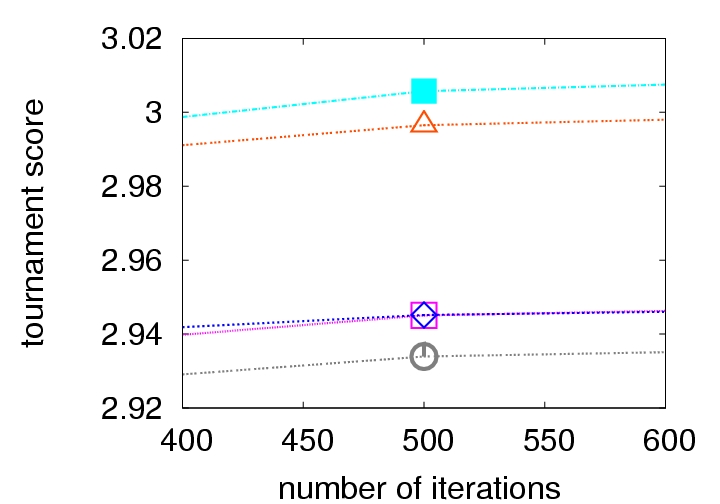
| All iterations | Zoom around iteration 500 |
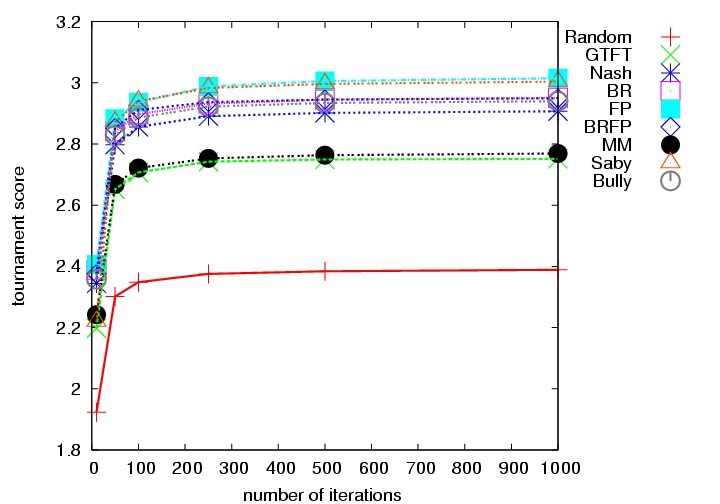
| Figure 2. Choice of the number of iterations | |
| Table 1: Algorithm ranking based on round-robin competition with one player per algorithm | |||
| Rank | Avg Score | Algorithm | std |
|---|---|---|---|
| 1 | FP | 3.014 | 0.002 |
| 2 | Saby | 3.003 | 0.004 |
| 3 | BR | 2.951 | 0.003 |
| BRFP | 2.949 | 0.000 | |
| 5 | Bully | 2.939 | 0.000 |
| 6 | Nash | 2.906 | 0.000 |
| 7 | M | 2.768 | 0.000 |
| 8 | GTFT | 2.751 | 0.008 |
| 9 | R | 2.388 | 0.001 |
| Table 2: Head to head results - mean of the score over all interactions, obtained by the row player in the table, while playing against the column player in the table. | |||||||||||
| Rank | Avg Score | Algorithm | FP | Saby | BR | BRFP | Bully | Nash | M | GTFT | R |
| 1 | 3.014 | FP | 2.950 | 2.950 | 3.027 | 2.999 | 3.081 | 2.943 | 3.081 | 3.101 | 2.994 |
| 2 | 3.003 | Saby | 3.090 | 2.986 | 3.040 | 2.934 | 3.080 | 2.929 | 3.079 | 2.989 | 2.904 |
| 3 | 2.951 | BR | 3.016 | 2.995 | 2.901 | 2.919 | 3.081 | 2.931 | 3.081 | 2.720 | 2.910 |
| 4 | 2.949 | BRFP | 3.040 | 3.122 | 3.133 | 2.906 | 2.797 | 2.921 | 2.884 | 2.858 | 2.879 |
| 5 | 2.939 | Bully | 3.116 | 3.116 | 3.116 | 2.871 | 2.696 | 2.891 | 2.783 | 2.976 | 2.888 |
| 6 | 2.906 | Nash | 2.908 | 2.930 | 2.926 | 2.930 | 2.811 | 2.933 | 2.898 | 2.922 | 2.899 |
| 7 | 2.768 | M | 2.696 | 2.698 | 2.696 | 2.713 | 2.626 | 2.734 | 2.626 | 3.134 | 2.994 |
| 8 | 2.751 | GTFT | 2.728 | 2.921 | 2.830 | 2.880 | 2.880 | 2.932 | 2.582 | 2.510 | 2.495 |
| 9 | 2.388 | R | 2.375 | 2.391 | 2.402 | 2.355 | 2.311 | 2.363 | 2.310 | 2.494 | 2.494 |
| Table 3: Head-to-head performance - net score difference of the row player in the table when playing against the column player in the table | |||||||||
| Algorithm | FP | Saby | BR | BRFP | Bully | Nash | M | GTFT | R |
| FP | -0.140 | 0.011 | -0.040 | -0.035 | 0.035 | 0.385 | 0.373 | 0.618 | |
| Saby | 0.140 | 0.044 | -0.188 | -0.035 | -0.001 | 0.380 | 0.067 | 0.513 | |
| BR | -0.011 | -0.044 | -0.214 | -0.035 | 0.004 | 0.385 | -0.110 | 0.508 | |
| BRFP | 0.040 | 0.188 | 0.214 | -0.074 | -0.009 | 0.170 | -0.021 | 0.524 | |
| Bully | 0.035 | 0.035 | 0.035 | 0.074 | 0.080 | 0.157 | 0.096 | 0.577 | |
| Nash | -0.035 | 0.001 | -0.004 | 0.009 | -0.080 | 0.163 | -0.010 | 0.535 | |
| M | -0.385 | -0.380 | -0.385 | -0.170 | -0.157 | -0.163 | 0.551 | 0.683 | |
| GTFT | -0.373 | -0.067 | 0.110 | 0.021 | -0.096 | 0.010 | -0.551 | 0.000 | |
| R | -0.618 | -0.513 | -0.508 | -0.524 | -0.577 | -0.535 | -0.683 | -0.000 | |
| Table 4: Head to head results - standard deviation of the score obtained by the row player in the table while playing against the column player in the table (the value of the standard deviation is the value of an entry times 10-3) | |||||||||
| Algorithm | FP | Saby | BR | BRFP | Bully | Nash | M | GTFT | R |
| FP | 0.00 | 0.21 | 0.00 | 0.00 | 0.00 | 0.50 | 0.00 | 6.34 | 0.42 |
| Saby | 0.20 | 2.69 | 3.04 | 0.18 | 0.00 | 0.36 | 0.02 | 0.29 | 0.59 |
| BR | 0.00 | 3.15 | 0.00 | 0.00 | 0.00 | 0.41 | 0.00 | 9.69 | 0.49 |
| BRFP | 0.00 | 0.22 | 0.00 | 0.00 | 0.00 | 0.34 | 0.00 | 0.00 | 0.39 |
| Bully | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.36 | 0.00 | 0.00 | 0.47 |
| Nash | 1.55 | 0.40 | 0.39 | 0.29 | 0.24 | 0.34 | 0.21 | 0.53 | 0.53 |
| M | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.50 | 0.00 | 0.00 | 0.73 |
| GTFT | 9.28 | 8.03 | 6.36 | 0.00 | 0.00 | 0.35 | 0.00 | 0.56 | 0.53 |
| R | 1.92 | 0.62 | 0.49 | 0.45 | 0.52 | 0.77 | 0.45 | 0.51 | 0.50 |
|
|
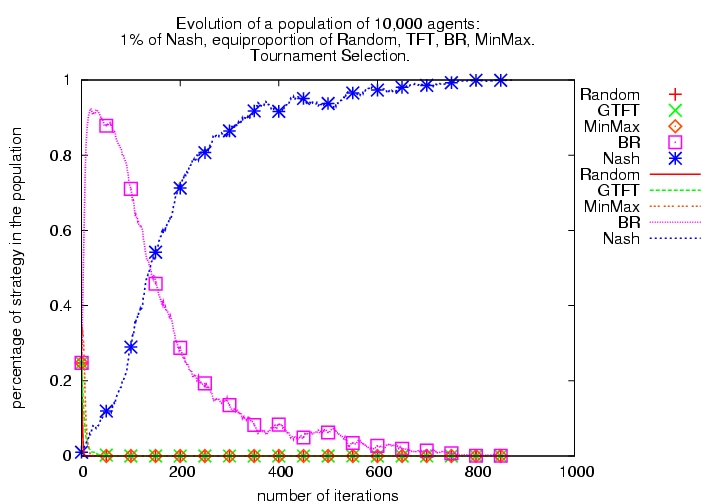
| Figure 3. Evolutionary Tournament with 5 algorithms (1% Nash and equal proportion of R, GTFT, BR and M) with tournament selection (left) and modified tournament selection (right) | |
There are two important observations from this representative population:
|
|
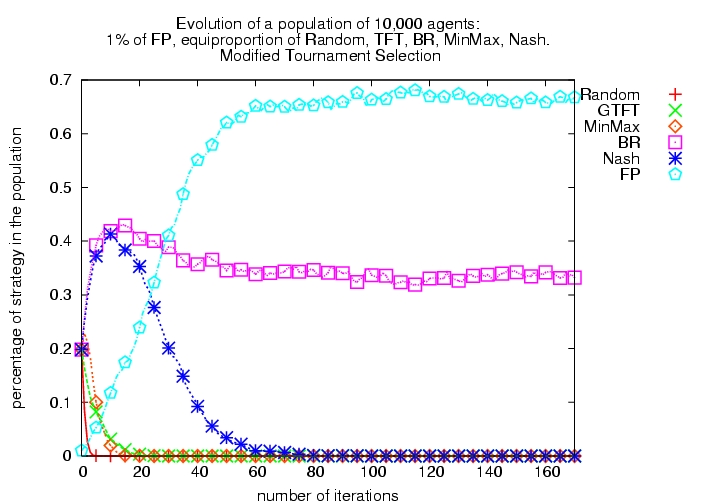
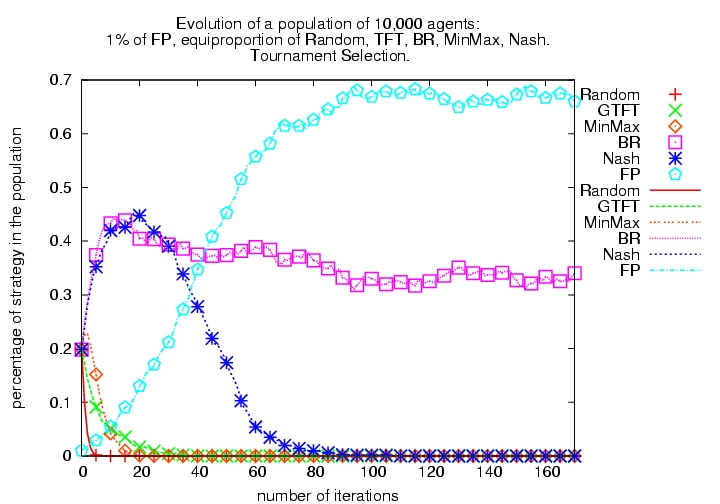
| Figure 4. Evolutionary Tournament with 6 algorithms (1% FP and equiproportion of R, GTFT, BR, MaxMin, Nash each) with tournament selection (left) and modified tournament selection (right) | |
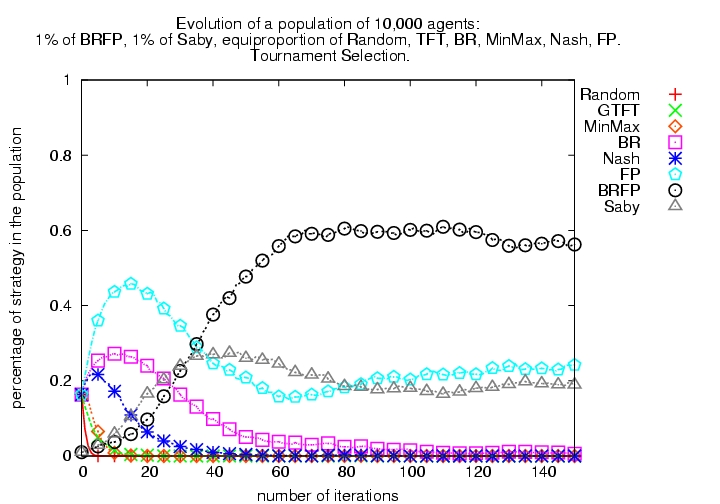
|
|
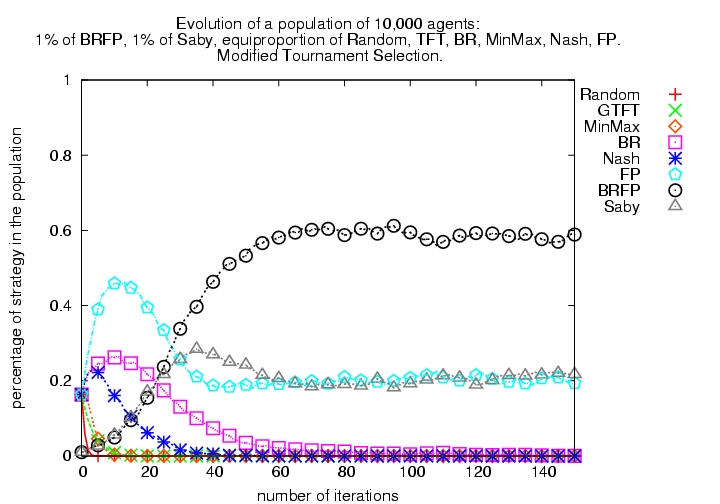
| Figure 5. Evolutionary Tournament with 8 algorithms (1000 each of R, GTFT, BR, M, Nash, FP, BRFP, Saby), using modified tournament selection | |
| Tournament Selection | Modified Tournament Selection | |
| No Bully initially present | 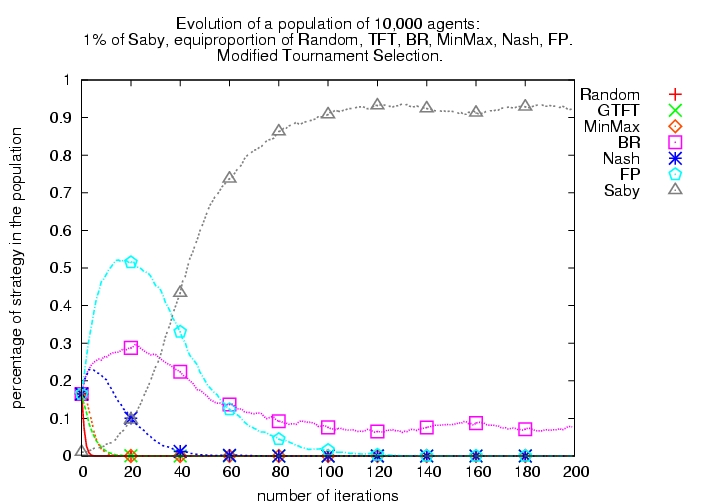
|
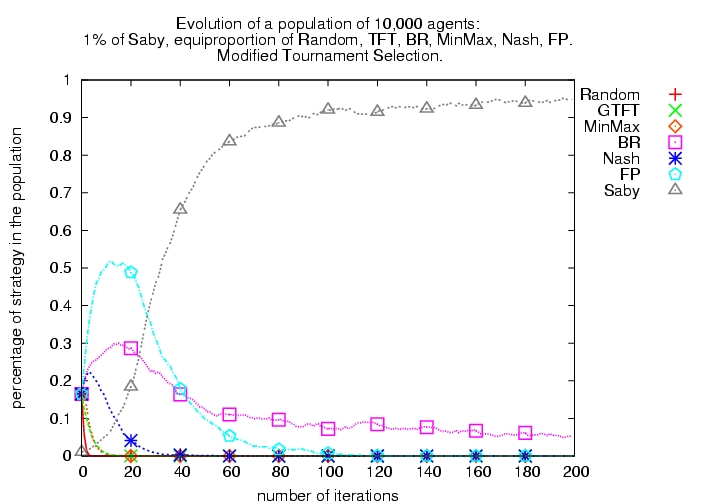 |
| Small proportion of Bully initially present | 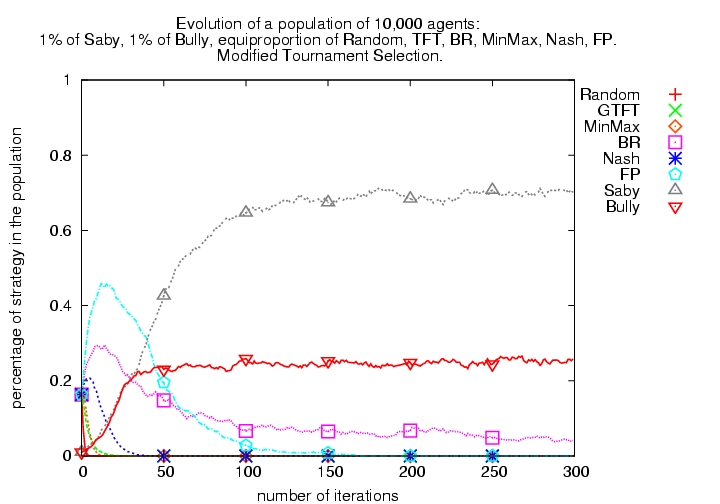 |
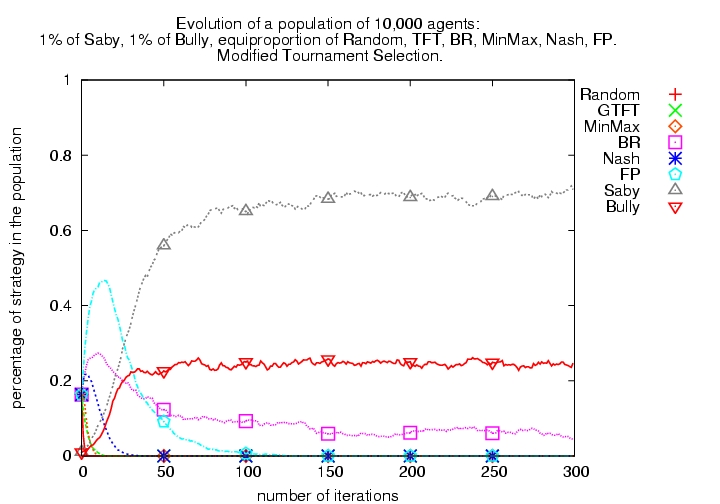 |
Figure 6: Evolutionary tournaments including learning algorithms with or without Bully
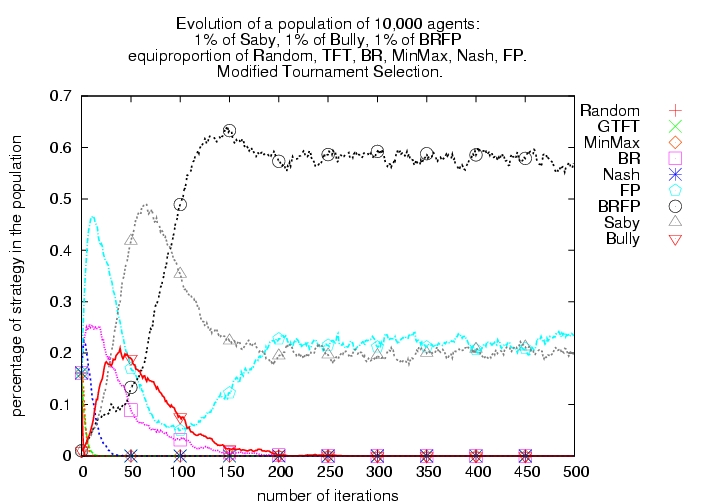
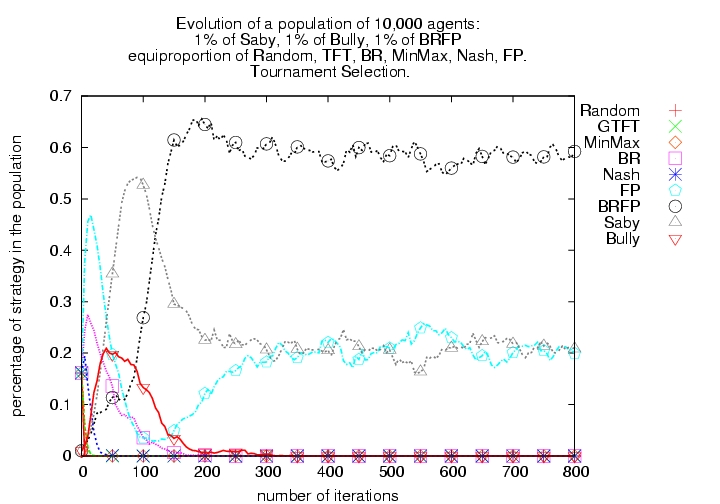
| 
|
| (a) Modified tournament selection | (b) 99% Modified tournament selection and 1% random selection
|
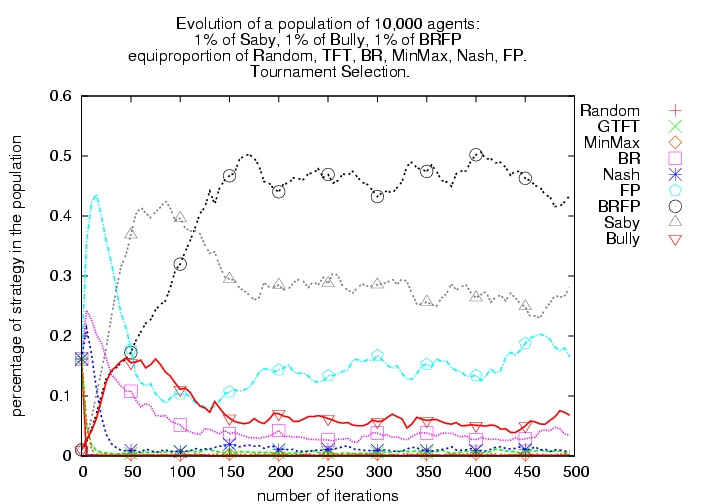
|
|
| (a) Tournament selection | (b) 99% Tournament selection and 1% random selection
|
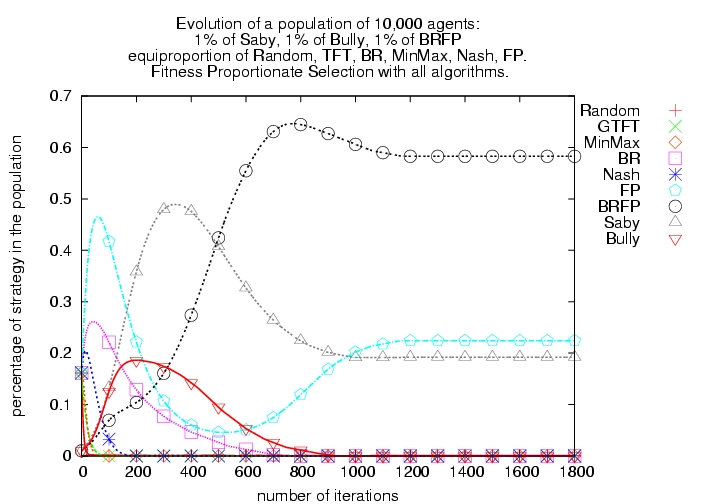
|
| Figure 9. Fitness Proportionate Selection with all algorithms |
1 A conflicted game is a game where no joint action can provide the most preferred outcome to all players.
2 For a given game in the testbed, there exists structurally equivalent games (that can be obtained by renaming the actions or the players), but none of the equivalent games is present in the testbed. All the games in the testbed are therefore structurally distinct. For each game structure, our selection of the representing matrices has introduced a bias: playing as a column player introduces an advantage.
3 Games with multiple Nash equilibria, rational agents will face a problem of equilibrium selection. Since the agents do not communicate, they may often select different equilibria and hence reach an undesirable outcome. A simple example is the coordination game, where each of the two agents gets 1 if they play the same action and 0 otherwise. There are three Nash equilibria, two pure strategies and one mixed strategy. One pure strategy equilibrium is when both players play the first action and other pure strategy equilibrium is when both players play the second action. In the mixed equilibrium, both the players play each action with probability 0.5. Therefore there is a significant chance that both players end up playing different actions and get 0.
4When there are two algorithms i and j present in the population, we can easily compute the score obtained by any agent as a function of the proportion fi of algorithm i in the population (1-fi is the proportion of algorithm j in the population). From Table 2, let hij denote the score obtained by an agent using algorithm i when playing against an agent using algorithm j. The score of an agent using algorithm i is si(fi)=fi·hii+(1-fi)·hij and the score for agent using algorithm j is sj(fi) = fi·hji+(1-fi)·hjj. If si(fi)>sj(fi) or si(fi)<sj(fi) for all fi∈[0,1], one algorithm will be ultimately used by all agents in the population. Otherwise, there exists a fixed point fi* where the two algorithms coexist: ∃fi*∈[0,1] | si(fi*)=sj(fi*): all the agents have the same score. Let us consider the case where si(fi) is a decreasing function of fi (sj(fi)=1-si(fi) is then an increasing function) and we have ∀fi < fi*, si(fi)>sj(fi) and ∀fi > fi*, si(fi)<sj(fi). For fi < fi*, the number of agents using algorithm i increases since those agents have better performance. However, with the increase in the number of agents using i, the performance of agents using i decreases whereas the performance of agents using algorithm j increases. When fi >fi*, agents using the algorithm j outperform those using algorithm i and hence, the proportion of algorithm j now increases. This process repeats until the population reaches the equilibrium point. This shows that the fixed point is an attractor. Similarly, a theoretical equilibrium can be calculated for n strategies by solving the following problem: ∀ (i,j) ri = rj where ri=Σj fj hij, Σifi=1 and fi ∈ [0,1] ∀i.
AXELROD R (1985) The Evolution of Cooperation, Basic Books, New York.
AXELROD R (1987) The Evolution of Strategies in the Iterated Prisoner's Dilemma. In Genetic Algorithms and Simulated Annealing, Lawrence Davis (ed.) (London: Pitman, and Los Altos, CA: Morgan Kaufman, 1987), pp. 32-41. Reprinted as Evolving New Strategies, pp. 10-39. in Axelrod, R. M. (1997).
BANERJEE B, Sen S and Peng J (2001) Fast concurrent reinforcement learners. In Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, 825–830.
BANERJEE D and Sen S (2007) Reaching pareto-optimality in prisoner's dilemma using conditional joint action learning. In Autonomous Agents and Multi-Agent Systems, Volume 15, number 1, August 2007, 91-108, Springer Netherlands
BOWLING M (2005) Convergence and no-regret in multiagent learning. In Advances in Neural Information Processing Systems 17 , 209-216
BOWLING M and Veloso M (2001) Rational and convergent learning in stochastic games. In Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, 1021–1026.
BOWLING M and Veloso M (2002) Multiagent learning using a variable learning rate. Artificial Intelligence, 136:215–250.
BRAMS S J (1994) Theory of Moves. Cambridge University Press, Cambridge: UK.
CLAUS C and Boutilier C (1998) The dynamics of reinforcement learning in cooperative multiagent systems. In Proceedings of the Fifteenth National Conference on Artificial Intelligence, 746–752. Menlo Park, CA: AAAI Press/MIT Press.
CONITZER V and Sandholm T (2003) Complexity results about Nash equilibria. In Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI), 2003.
CRANDALL J W and Goodrich M A (2005) Learning to Compete, Compromise, and Cooperate in Repeated General-Sum Games. In Proceedings of the 22nd International Conference on Machine Learning, 161-168.
DEB K and Goldberg D (1991) A comparative analysis of selection schemes used in genetic algorithms. In Rawlins, G. J., ed., Foundations of Genetic Algorithms, 69–93. San Mateo, CA: Morgan Kaufman.
NUDELMAN E, Wortman J, Shoham Y and Leyton-Brown K (2004) Run the GAMUT: A Comprehensive Approach to Evaluating Game-Theoretic Algorithms. In Proceedings of the third International Joint Conference on Autonomous Agents and Multiagent Systems(AAMAS'04).
FUDENBERG D and Levine K (1998) The Theory of Learning in Games. Cambridge, MA: MIT Press.
GREENWALD A and Hall K (2003) Correlated-q learning. In Proceedings of the Twentieth International Conference on Machine Learning, pages 242-249.
HU J and Wellman M P (1998) Multiagent reinforcement learning: Theoretical framework and an algorithm. In Shavlik, J., ed., Proceedings of the Fifteenth International Conference on Machine Learning, 242–250. San Francisco, CA: Morgan Kaufmann.
JAFARI A, Greenwald A, Gondek D and Ercal G (2001) On no-regret learning, fictitious play and Nash equilibrium. In Proceedings of the Eighteenth International Conference on Machine Learning, 226-233, San Francisco, CA: Morgan Kaufmann.
LITTMAN M L and Stone P (2001) Implicit negotiation in repeated games. In Intelligent Agents VIII: AGENT THEORIES, ARCHITECTURE, AND LANGUAGES, 393–404. Littman, M. L. 1994. Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the Eleventh International Conference on Machine Learning, 157–163. San Mateo, CA: Morgan Kaufmann.
LITTMAN M L (1994) Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the Seventh International Conference on Machine Learning, 157-163.
LITTMAN M L (2001) Friend-or-foe q-learning in generalsum games. In Proceedings of the Eighteenth International Conference on Machine Learning, 322–328. San Francisco, CA: Morgan Kaufmann.
MCKELVEY R D, McLennan A M, and Turocy T L (2005) Gambit: Software Tools for Game Theory, Version 0.2005.06.13. http://econweb.tamu.edu/gambit
MUNDHE M and Sen S (2000) Evaluating concurrent reinforcement learners. In Proceedings of Fourth International Conference on MultiAgent Systems, 421–422. Los Alamitos, CA: IEEE Computer Society.
SANDHOLM T and Crites R (1995) Multiagent Reinforcement Learning in the Iterated Prisoner's Dilemma. In Biosystems 37(1:2).
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]