
Jean-Philippe Cointet and Camille Roth (2007)
How Realistic Should Knowledge Diffusion Models Be?
Journal of Artificial Societies and Social Simulation
vol. 10, no. 3 5
<https://www.jasss.org/10/3/5.html>
For information about citing this article, click here
Received: 13-Nov-2006 Accepted: 21-Apr-2007 Published: 30-Jun-2007

 Abstract
AbstractFor network analysis to fulfill its potential, however, I feel we must improve the methods of data gathering and measurement (…). Longitudinal panel designs for networks analysis of diffusion process are also needed; along with field experiments, they help secure the necessary data to illuminate the over-time process of diffusion. (Rogers 1976)
SET number_of_nodes := number of agents
SET neighbor := ARRAY OF LISTS of size number_of_nodes
SET state := ARRAY OF BOOLEANS ("INFORMED"/"NOT_INFORMED") of size number_of_nodes
SET number_of_interactions := ARRAY OF INTEGERS of size number_of_nodes
INITIALIZE neighbor[i] with the neighbor list for node i
INITIALIZE state WITH "INFORMED" on a random selection of elements of
size Integer_Part_Of(number_of_nodes*lambda)
INTIIALIZE number_of_interactions WITH 0 on the whole array
FOR each step of the simulation
CHOOSE RANDOMLY an agent i
IF state[i] IS "NOT_INFORMED"
THEN
CHOOSE RANDOMLY an agent j among neighbor[i]
IF state[j] IS "INFORMED"
THEN
IF a uniform random variable in [[0, 1]] IS BELOW
Probability_Of_Adoption_After_N_Interactions(number_of_interactions[i])
THEN
state(i) := "INFORMED"
END IF
INCREMENT number_of_interactions(i)
END IF
END IF
END FOR
|
| Algorithm |
|
|
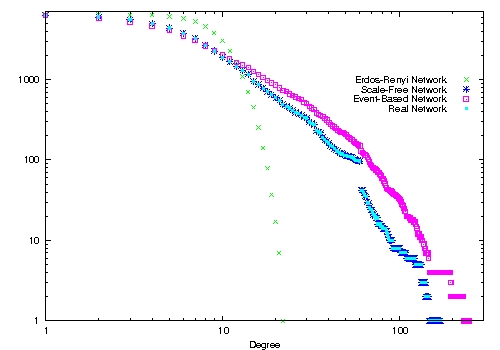
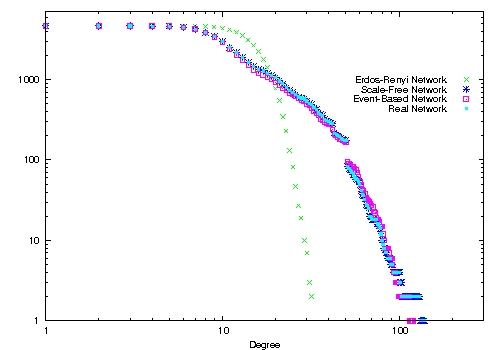
| Figure 1. Cumulated degree distributions for the various network structures, using the Medline-base collaboration network (left) and the board interlock network (right). x-axis: degree k, y-axis: N(k)=∑ k' ≥ kN(k'). | |
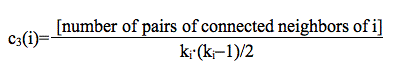
|
(1) |
with ki the degree of node i. Empirical social networks are known to exhibit an abnormally high average clustering coefficient ‹c3›, compared to those found in SF and ER random networks (Newman and Park 2003); many models traditionally try to rebuild this statistical parameter as well. Our real networks do not derogate from this rule. RN1 exhibits a high ‹c3› of .827, while SF1 only has a ‹c3› of .00539. We observe the same discrepancy in the second network: clustering in RN2 is high (‹c3› = .889) while it is two orders of magnitude smaller in SF2 (‹c3› = .00395).
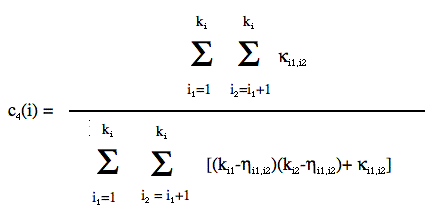
|
(2) |
where κj1,j2 is the number of nodes which the j1-th & j2-th neighbors of i have in common (leaving out i) and ηj1,j2 = 1 + κj1,j2 + θj1,j2 where θj1,j2 = 1 if j1 and j2 are connected, 0 otherwise. EB1 acceptably approaches the ‹c3› of RN1, but falls short of one order of magnitude for c4 , suggesting that even an event-based reconstruction still misses part of the community structure of RN1. On the other hand, EB2 yields a ‹c4› of .268 which is closer to the ‹c4› of .398 for RN2. Values for these statistical parameters are gathered on Table 1.
| Table 1: Main characteristics of the various network structures derived from the real networks RN1 and RN2 in terms of: number of agents N, number links M, density d, degree distribution shape and clustering coefficients ‹c3› & ‹c4‹ (averaged quantities over 1000 networks for SF, ER & EB). | |||||
| RN1 | SF1 | ER1 | CN1 | EB1 | |
| N | 6453 | ||||
| M | 6.74104 | 2.08107 | 7.62104 | ||
| d | .00162 | 1 | .00183 | ||
| degree dist. | power-law tail | Poisson | - | power-law tail | |
| ‹c3› | .827 | .00539 | .00199 | 1 | .753 |
| ‹c4› | .400 | .000260 | .000158 | 1 | .0694 |
| RN2 | SF2 | ER2 | CN2 | EB2 | |
| N | 4656 | ||||
| M | 7.66·104 | 2.17·107 | 7.68·104 | ||
| d | .0035 | 1 | .0035 | ||
| degree dist. | power-law tail | Poisson | - | power-law tail | |
| ‹c3› | .889 | .00395 | .00403 | 1 | .897 |
| ‹c4› | .398 | .000261 | .000217 | 1 | .268 |
|
|
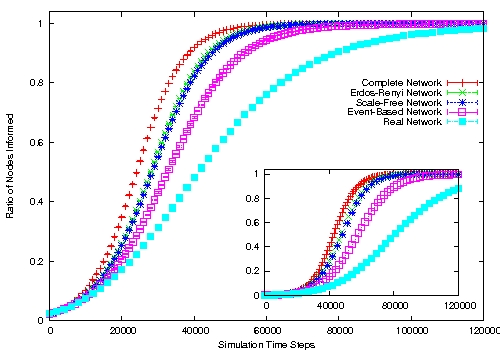
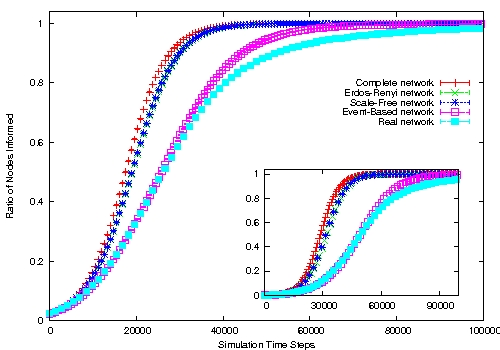
| Figure 2. Simulation results for complete, Erdös-Rényi, Scale-Free, Event-Based and real networks, using λ = 0.02 (outset) and λ = 0.002 (inset), along with associated 99% confidence intervals. Topologies built from the scientific collaboration network (left) and the board interlock network (right). | |
|
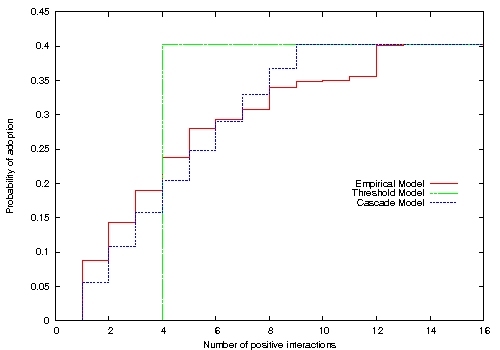
| Figure 3. Final probability of adoption P(n) after n recommending interactions (Pmax=0.4). Empirical data adapted from (Leskovec et al. 2006), where Pmax=0.04 (see Figure 4 for a discussion on Pmax values). |
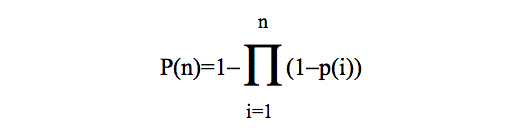
|
(3) |
from which it is straightforward to deduce that:
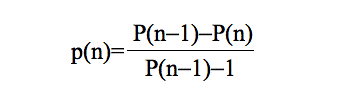
|
(4) |
as we assume that p(i) are independent one each other. Thus, the probability of adopting at each n-th interaction with an informed neighbor is p(n).
PTM(n)=PmaxHν(n)where Hν is a threshold function: Hν(n)=1 if n ≥ ν, 0 otherwise.
PCM(n)=1-(1-p)min(n,ν)Clearly, p=1-(1-Pmax)1/ν; thus, once Pmax is chosen, CM depends on only one parameter, say ν, as TM does.
|
|
|
|
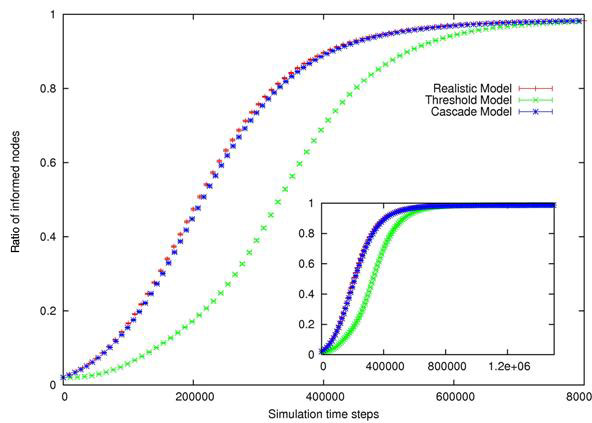
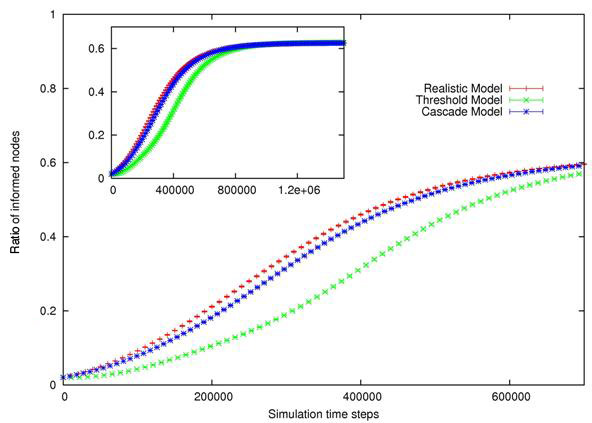
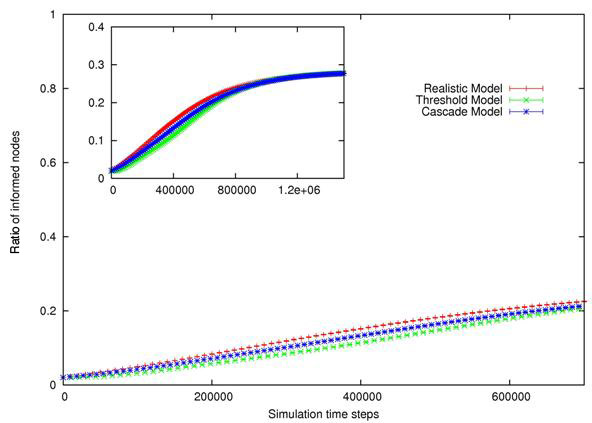
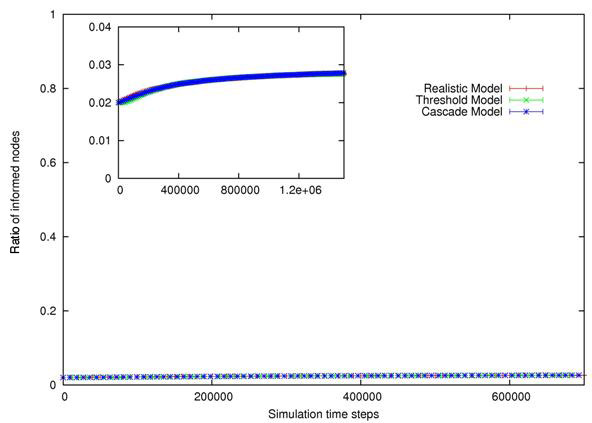
| Figure 4. Evolution of ρ for RM, TM and CM, given four distinct Pmax, from left to right and from top to bottom : Pmax =0.99, Pmax =0.7, Pmax =0.4, Pmax =0.04. Confidence intervals (99%) are also shown. Insets exhibit asymptotic behavior for large time steps. | |
|
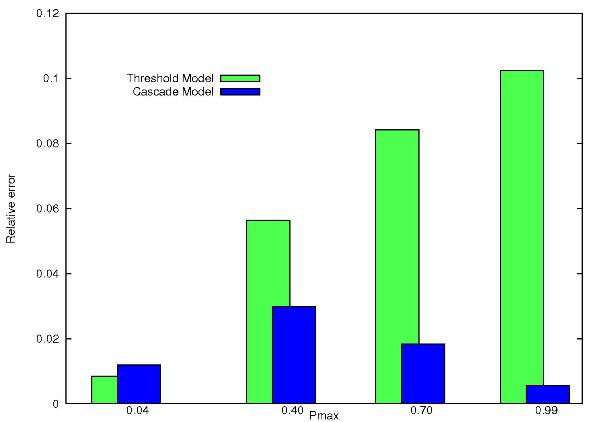
| Figure 5. Relative error between Threshold and Cascade model compared to Realistic Model |
2 This is especially relevant if the timescale of diffusion is smaller than that of social network evolution (e.g. in the case of rumors, hypes, etc.), then the social network can be considered static.
3 Wang et al. (2003) show that their model of virus diffusion is more efficient than that of Pastor-Satorras and Vespignani (2001) on various topologies, including a real computer network, while actually not directly comparing how diversely their model performs between real-world and modeled topologies. Similarly, Wu et al. (2004) simulate information propagation on a real e-mail network; yet not estimating how different the behavior would be in other kinds of (scale-free) networks.
4 Freely available from http://www.pubmed.com. Additionally, the particular network data used in this paper is here.
5 Data freely available from http://www.theyrule.net, Additionaly, the particular network data used in this paper is here.
6 Similarly to Leskovec et al. (2006), Backstrom et al. (2006) have measured the propension to join a "LiveJournal" community as a function of the number of friends already present in the community.
7 It is unclear whether such feature may or may not be accounted for by the aggregation of different categories of products and/or agents.
AMARAL, L. A. N., Scala, A., Barthélémy, M. and Stanley, H. E. (2000). Classes of small-world networks. PNAS, 97(21), pp. 11149-11152.
AMBLARD, F. and Deffuant, G. (2004). The role of network topology on extremism propagation with the relative agreement opinion dynamics. Physica A, 343, pp. 725-738.
ANDERSON, R. M. and May, R. M. (1979). Population biology of infectious diseases. Nature, 280, pp. 361-367 & 455-461. Part I & II.
AXELROD, R. (1997). The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration. Princeton, N.J.: Princeton University Press.
BACKSTROM, L., Huttenlocher, D., Kleinberg, J. and Lan, X. (2006). Group formation in large social networks: membership, growth, and evolution. In KDD '06: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, NY, USA: ACM Press, pp. 44-54.
BALA, V. and Goyal, S. (1998). Learning from Neighbours. Review of Economic Studies, 65(3), pp. 595-621.
BARABSI, A.-L. and Albert, R. (1999). Emergence of Scaling in Random Networks. Science, 286, pp. 509-512.
BARABASI, A.-L., Jeong, H., Ravasz, R., Neda, Z., Vicsek, T. and Schubert, T. (2002). Evolution of the social network of scientific collaborations. Physica A, 311, pp. 590-614.
BARBOUR, A. and Mollison, D. (1990). Epidemics and random graphs. In J.-P. Gabriel, C. Lefevre and P. Picard (Eds.) Stochastic Processes in Epidemic Theory, Lecture Notes in Biomaths, 86. Springer, pp. 86-89.
BARTHELEMY, M., Barrat, A., Pastor-Satorras, R. and Vespignani, A. (2005). Dynamical patterns of epidemic outbreaks in complex heterogeneous networks. Journal of Theoretical Biology, 235, p. 275.
BOGUNA, M. and Pastor-Satorras, R. (2002). Epidemic spreading in correlated complex networks. Physical Review E, 66, p. 047104.
BOGUNA, M., Pastor-Satorras, R., Diaz-Guilera, A. and Arenas, A. (2004). Models of social networks based on social distance attachment. Physical Review E, 70, p. 056122.
BOLLOBAS, B. (1985). Random Graphs. London: Academic Press.
BURT, R. S. (1987). Social Contagion and Innovation: Cohesion Versus Structural Equivalence. American Journal of Sociology, 92(6), pp. 1287-1335.
COLEMAN, J., Katz, E. and Menzel, H. (1957). The Diffusion of an Innovation Among Physicians. Sociometry, 20(4), pp. 253-270.
COWAN, R. and Jonard, N. (2004). Network structure and the diffusion of knowledge. Journal of Economic Dynamics and Control, 28, pp. 1557-1575.
CREPEY, P., Alvarez, F. P. and BarthÈlemy, M. (2006). Epidemic variability in complex networks. Physical Review E, 73(4), p. 046131.
DEFFUANT, G. (2006). Comparing Extremism Propagation Patterns in Continuous Opinion Models. Journal of Artificial Societies and Social Simulation, 9(3), p. 8.
DEFFUANT, G., Amblard, F., Weisbuch, G. and Faure, T. (2002). How can extremism prevail? A study based on the relative agreement interaction model. Journal of Artificial Societies and Social Simulation, 5(4), p. 1.
DELGADO, J. (2002). Emergence of social conventions in complex networks. Artificial Intelligence, 141, pp. 171-185.
DEROIAN, F. (2002). Formation of social networks and diffusion of innovations. Research Policy, 31, pp. 835-846.
DOROGOVTSEV, S. N. and Mendes, J. F. F. (2003). Evolution of Networks: From Biological Nets to the Internet and WWW. Oxford University Press, Oxford.
EGUILUZ, V. M. and Klemm, K. (2002). Epidemic threshold in structured scale-free networks. Physical Review Letters, 89, p. 108701.
ELLISON, G. and Fudenberg, D. (1995). Word-of-Mouth Communication and Social Learning. Quarterly Journal of Economics, 110(1), pp. 93-125.
ERDÖS, P. and Rényi, A. (1959). On random graphs. Publicationes Mathematicae, 6, pp. 290-297.
GANESH, A., Massoulié, L. and Towsley, D. (2005). The effect of network topology on the spread of epidemics. In IEEE Infocom, vol. 2. pp. 1455-1466.
GILBERT, N., Pyka, A. and Ahrweiler, P. (2001). Innovation Networks — A Simulation Approach. Journal of Artificial Societies and Social Simulation, 4(3), p. 8.
GOLDENBERG, J., Libai, B. and Muller, E. (2001). Talk of the network: A complex systems look at the underlying process of word-of-mouth. Marketing Letters, 12(3), pp. 211-223.
GRANOVETTER, M. (1987). Threshold models of collective behavior. American Journal of Sociology, 83(6), pp. 1420-1443.
GRANOVETTER, M. S. (1973). The Strength of Weak Ties. The American Journal of Sociology, 78(6), pp. 1360-1380.
GRUHL, D., Guha, R., Liben-Nowell, D. and Tomkins, A. (2004). Information Diffusion Through Blogspace. In WWW2004: Proceedings of the 13th Intl Conf on World Wide Web. NYC, NY, USA, pp. 491-501.
GUILLAUME, J.-L. and Latapy, M. (2004). Bipartite structure of all complex networks. Information Processing Letters, 90(5), pp. 215-221.
GUIMERA, R., Uzzi, B., Spiro, J. and Amaral, L. A. N. (2005). Team Assembly Mechanisms Determine Collaboration Network Structure and Team Performance. Science, 308, pp. 697-702.
HETHCOTE, H. W. (2000). The Mathematics of Infectious Diseases. SIAM Review, 42(4), pp. 599-653.
HOLME, P., Edling, C. R. and Liljeros, F. (2004). Structure and time evolution of an Internet dating community. Social Networks, 26, pp. 155-174.
KEELING, M. J. and Eames, K. T. D. (2005). Networks and epidemics models. Journal of the Royal Society Interface, 2, pp. 295-307.
KEMPE, D., Kleinberg, J. and Tardos, E. (2003). Maximizing the spread of influence through a social network. In KDD '03: Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. New York, NY, USA: ACM Press, pp. 137-146.
KEMPE, D., Kleinberg, J. and Tardos, E. (2005). Influential Nodes in a Diffusion Model for Social Networks. In ICALP, vol. 3580 of Lecture Notes in Computer Science. Springer, pp. 1127-1138.
KEMPE, D. and Kleinberg, J. M. (2002). Protocols and Impossibility Results for Gossip-Based Communication Mechanisms. In I. C. Society (Ed.) FOCS '02: Proceedings of the 43rd Symposium on Foundations of Computer Science. Washington, DC, USA, pp. 471-480.
KLEMM, K., Eguiluz, V. M., Toral, R. and Miguel, M. S. (2005). Globalization, polarization and cultural drift. Journal of Economic Dynamics and Control, 29, pp. 321-334.
KOSSINETS, G. and Watts, D. J. (2006). Empirical Analysis of an Evolving Social Network. Science, 311, pp. 88-90.
LESKOVEC, J., Adamic, L. A. and Huberman, B. A. (2006). The Dynamics of Viral Marketing. In ACM Conference on Electronic Commerce. pp. 228-237.
LEW, B. (2000). The Diffusion of Tractors on the Canadian Prairies: The Threshold Model and the Problem of Uncertainty. Explorations in Economic History, 37(2), pp. 189-216.
LIND, P. G., Gonzalez, M. C. and Herrmann, H. J. (2005). Cycles and clustering in bipartite networks. Physical Review E, 72, p. 056127.
LLOYD, A. L. and May, R. M. (2001). How Viruses Spread Among Computers and People. Science, 292(5520), pp. 1316-1317.
MAY, R. M. and Lloyd, A. L. (2001). Infection dynamics on scale-free networks. Physical Review E, 64(6), p. 066112.
MOLLOY, M. and Reed, B. (1995). A critical point for random graphs with a given degree sequence. Random Structures and Algorithms, 161(6), pp. 161-179.
MORRIS, S. (2000). Contagion. Review of Economic Studies, 67(1), pp. 57-78.
NEWMAN, M. E. J. (2002). Spread of Epidemic Disease on Networks. Physical Review E, 66(016128).
NEWMAN, M. E. J. (2003). Ego-centered networks and the ripple effect — or — Why all your friends are weird. Social Networks, 25, pp. 83-95.
NEWMAN, M. E. J. and Park, J. (2003). Why social networks are different from other types of networks. Physical Review E, 68(036122).
NEWMAN, M. E. J., Strogatz, S. and Watts, D. (2001). Random graphs with arbitrary degree distributions and their applications. Physical Review E, 64(026118).
PASTOR-SATORRAS, R. and Vespignani, A. (2001). Epidemic Spreading in Scale-Free Networks. Physical Review Letters, 86(14), pp. 3200-3203.
PASTOR-SATORRAS, R. and Vespignani, A. (2002). Epidemic dynamics in finite size scale-free networks. Physical Review E, 65, p. 035108.
REDNER, S. (2005). Citation Statistics from 110 Years of Physical Review. Physics Today, 58, pp. 49-54.
ROBERTSON, T. S. (1967). The Process of Innovation and the Diffusion of Innovation. Journal of Marketing, 31(1), pp. 14-19.
ROBINS, G. and Alexander, M. (2004). Small Worlds Among Interlocking Directors: Network Structure and Distance in Bipartite Graphs. Computational and Mathematical Organization Theory, 10, pp. 69-94.
ROGERS, E. M. (1976). New Product Adoption and Diffusion. The Journal of Consumer Research, 2(4), pp. 290-301.
ROGERS, E. M. (2003). Diffusion of Innovations, 5th Edition. Free Press.
SZENDRÖI, B. and Csányi, G. (2004). Polynomial epidemics and clustering in contact networks. Proceedings of the Royal Society London, B Biological sciences, 271, pp. S364-S366.
VALENTE, T. W. (1995). Network Models of the Diffusion of Innovations. Hampton Press.
VALENTE, T. W. (1996). Social network thresholds in the diffusion of innovations. Social Networks, 18, pp. 69-89.
WANG, Y., Chakrabarti, D., Wang, C. and Faloutsos, C. (2003). Epidemic Spreading in Real Networks: An Eigenvalue Viewpoint. In Proceedings of the 22nd Symposium on Reliable Distributed Systems (SRDS 2003). IEEE Computer Society, pp. 25-34.
WASSERMAN, S. and Faust, K. (1994). Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press.
WATTS, D. J. and Strogatz, S. H. (1998). Collective dynamics of "small-world" networks. Nature, 393, pp. 440-442.
WHITE, D. R., Kejzar, N., Tsallis, C., Farmer, D. and White, S. D. (2006). A generative model for feedback networks. Physical Review E, 73, p. 016119.
WU, F., Huberman, B. A., Adamic, L. A. and Tyler, J. R. (2004). Information Flow in Social Groups. Physica A, 337, pp. 327-335.
ZEGURA, E. W., Calvert, K. L. and Bhattacharjee, S. (1996). How to Model an Internetwork. In IEEE Infocom, vol. 2. San Francisco, CA: IEEE, pp. 594-602.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]