
Stephen Wendel and Catherine Dibble (2007)
Dynamic Agent Compression
Journal of Artificial Societies and Social Simulation
vol. 10, no. 2, 9
<https://www.jasss.org/10/2/9.html>
For information about citing this article, click here
Received: 01-Jan-2007 Accepted: 09-Jan-2007 Published: 31-Mar-2007

 Abstract
Abstract

|
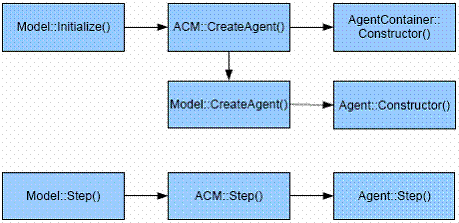
| Figure 1. Program Execution Before Implementing Dynamic Agent Compression |
|
| Figure 2. Program Execution After Implementing Dynamic Agent Compression (ACM = Agent Compression Manager) |
|
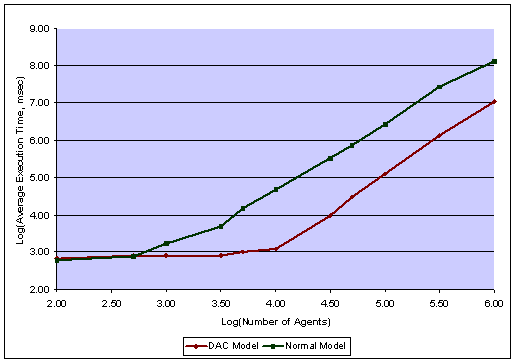
| Figure 3. Execution Time of the Sample Model with and without Dynamic Agent Compression (DAC) |
|
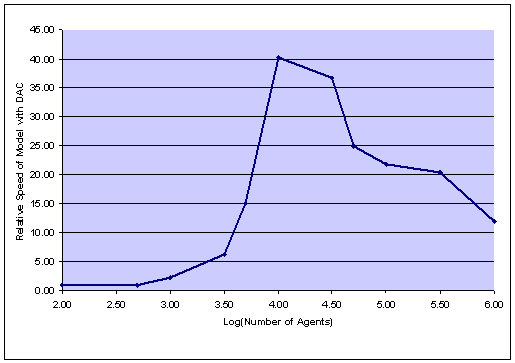
| Figure 4. Relative Improvement in Execution Time due to Dynamic Agent Compression ( = Execution Time without Compression Divided by Execution Time with Compression) |
|
|
(1) |
Or the time to step each of the agents plus the time to step the rest of the model (graphics, data logging, control logic, etc.).
|
|
(2) |
|
|
(3) |
Or, equivalently: Dynamic Agent Compression improves the run-time efficiency of a model when the benefit from compression (the time required to step containers minus the cost that would have been incurred by stepping each of the agents within the containers individually) is greater than the cost of handling the flow of agents that decompress on each time tick.

|
(4) |
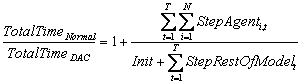
|
(5) |
2 Bias in model behavior would be considered a compression artifact. As with any lossy compression technique, the goal is to provide modelers with the fewest artifacts for the desired level of compression. Artifacts can never be completely avoided, however, and the modeler should perform a thorough sensitivity analysis to evaluate tradeoffs.
3 The meaning of sufficiently clustered depends on the level of compression chosen. In a lossless implementation, agents would have to be on the same point in space. Lossless compression would be suitable for grid and network landscapes, but not for continuous real-valued landscapes. In a lossy compression, agents could be clustered if they were located in nearby points in space.
4 For example, compressing an agent in the sample implementation given above only entails incrementing the relevant Agent Container's counter and storing the agent's name in a list.
5 This is the maximum improvement if all else were constant; disk-paging and garbage collection issues can complicate the analysis. If the model is too large to fit into physical memory, and the computer is forced to use a page-file, then the simulation would run significantly slower. When Dynamic Agent Compression allows the computer to avoid paging, the realized gains would naturally be much higher.
6 Following similar robustness analyses that modelers already apply to input parameters, a la Steven Bankes's use of a Latin Hyber-cube to sample and analyze parameters (see www.evolvinglogic.com/el_news.html for an example).
7 A simple hash lookup can be used to see if they fit into an existing container.
HELLWEGER F. L. and Kianirad E. (2006) 'Spatially Explicit Individual-Based Modeling: Global vs. Local Fixed Agent Number Methods'. SwarmFest 2006 Presentation, June 2006, Notre Dame, Indiana.
NAGEL K. and Rickert M. (2001) 'Parallel implementation of the TRANSIMS micro-simulation'. Parallel Computing, 27(12):1611-1639.
ROSE K. A., Christensen S. W., and DeAngelis D. L. (1993) 'Individual-based modeling of populations with high mortality: A new method based on following a fixed number of model individuals'. Ecological Modelling 68(3-4):273-292.
SCHEFFER M., Baveco J. M., DeAngelis D. L., Rose K. A., and Nes E. H. (1995) 'Super-individuals a simple solution for modelling large populations on an individual basis'. Ecological Modelling 80(2):161-170.
SERVAT D., Perrier E., Treuil J. P., and Drogoul A. (1998) 'When Agents Emerge from Agents: Introducing Multi-scale Viewpoints in Multi-agent Simulations'. Lecture Notes in Computer Science 1534:183-198.
STAGE, A. R., Crookston N. L., and Monserud R. A. (1993) 'An aggregation algorithm for increasing the efficiency of population models'. Ecological Modelling 68(3-4):257-271.
|
|
(1) |
Dynamic Agent Compression is primarily designed to improve the execution time of the model at each time step, and will be the focus of the discussion here. Moreover, the initialization cost of lossless Dynamic Agent Compression as presented in the main paper is trivial.
|
|
(2) |
Or the time to step each of the agents plus the time to step the rest of the model (graphics, data logging, control logic, etc.).

|
(3) |
With terms:

|
(4) |
With terms:
|
|
(5) |
With terms:
|
|
(6a) |
Or, equivalently,
|
|
(6b) |
I.e., when the time required to step the (1-at)*N agents compressed within containers plus the time required to decompress bt% of the compressed agents is less than the time it would have taken to just step the same number of uncompressed agents. Finally, we can restate this equation as:
|
|
(6c) |
Dynamic Agent Compression improves the run-time efficiency of a model when the benefit from compression (the time required to step containers minus the cost that would have been incurred by stepping each of the agents within the containers individually) is greater than the cost of handling the flow of agents that decompress and are instantiated as new individual agent on each time tick.

|
(7) |

|
(8a) |
See 4.1 for an analysis of these equations, including the upper and lower bound on efficiency to be expected from Dynamic Agent Compression.
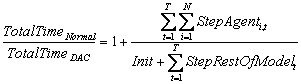
|
(8b) |
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]