
Matteo Richiardi, Roberto Leombruni, Nicole Saam and Michele Sonnessa (2006)
A Common Protocol for Agent-Based Social Simulation
Journal of Artificial Societies and Social Simulation
vol. 9, no. 1
<https://www.jasss.org/9/1/15.html>
For information about citing this article, click here
Received: 12-Dec-2005 Accepted: 15-Dec-2005 Published: 31-Jan-2006

 Abstract
Abstract| xi,t+1 = fi(xi,t, x-i,t, &alphai) | (1) |
where x-i is the state of all individuals other than i and α are some structural parameters.
| Yt = s(x1,t …, xn,t) | (2) |
| Yi = gt(x1,0, …, xn,0; α1, … &alphan) | (3) |
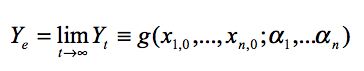
|
(4) |
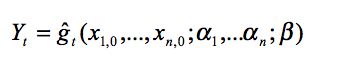
|
(5) |
on the artificial data, where β are some coefficients to be estimated in the artificial data. Note that this is nothing else than a sensitivity analysis on all the parameters together.
the distinction drawn between calibrating and estimating the parameters of a model is artificial at best. Moreover, the justification for what is called "calibration" is vague and confusing. In a profession that is already too segmented, the construction of such artificial distinctions is counterproductive.

|
| Figure 1. An example of a Class diagram |
In particular Class diagrams can be used to show three types of relationships:
|
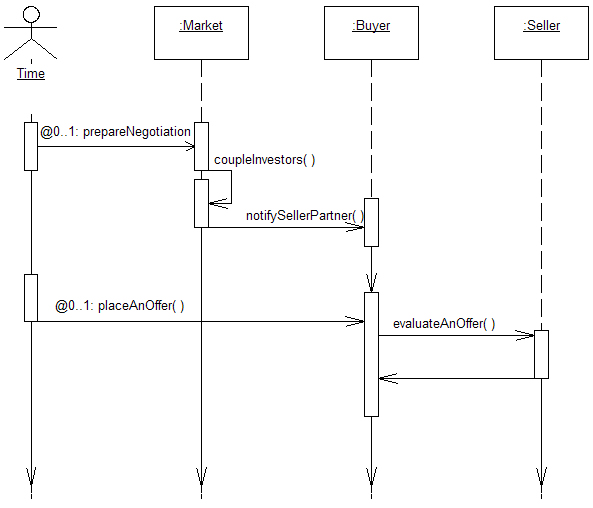
| Figure 2. An example of a Time-Sequence diagram |
2(Arifovic 1995; Arifovic 1996; Andreoni 1995; Arthur 1991; Arthur 1994; Gode and Sunder 1993; Weisbuch 2000)
3We looked for journal articles containing the words "agent-based", "multi-agent", "computer simulation", "computer experiment", "microsimulation", "genetic algorithm", "complex systems", "El Farol", "evolutionary prisoner's dilemma", "prisoner's dilemma AND simulation" and variations in their title, keywords or abstract in the EconLit database, the American Economic Association electronic bibliography of world economics literature. Note however that EconLit sometimes does not report keywords and abstracts. We have thus integrated the resulting list with the references cited in the review articles cited above. The ranking is provided in Kalaitzidakis et al. (2003).
4Schelling 1969; Tullock and Campbell 1970.
5Clarkson and Simon 1960; Cohen 1960; Cohen and Cyert 1961; Orcutt 1960; Shubik 1960 .
. 6JEDC has a section devoted to computational methods in economics and finance.
7We looked for journal articles containing the words "simulation", "agent-based", "multi-agent" and variations in their title, keywords or abstract in the Sociological Abstracts database. All abstracts have been checked for subject matter dealing with ABM. We used the 2001 Citation Impact Factors (CIF) ranking for Sociology journals (93 journals).
8for a brief account of the analogies and differences between agent-based simulations and traditional analytical modelling see Leombruni and Richiardi (2005)
9There is some confusion in the literature to this regard, and it should be an aim of the methodological clarification we are calling for to address it. For discrete-time simulation social scientists generally mean that the state of the system is updated (i.e. observed) only at discrete (generally constant) time intervals. No reference is made to the timing of events within a period - see, for example, Allison and Leinhardt (1982). Conversely, a model is said to be continuous-time event-driven when the state of the system is updated every time a new event occurs (Lancaster 1990; Lawless 1982). In this case it is necessary to isolate all the events and define their exact timing. Note that discrete-time simulation is a natural option when continuous, flow variables are modelled, and the definition of an event becomes more arbitrary. For this reason (and mainly in the Computer Science literature) the definitions above are sometimes reversed.
10Examples of centralized coordination mechanisms other than the usual, unrealistic Walrasian auctioneer (the hypothetical market-maker who matches supply and demand to get a single price for a good) generally assumed by traditional analytical models include real auctions, stock exchange books, etc. Examples of decentralized coordination mechanisms include bargaining, barter, etc.
11Note that this is not equivalent to saying that simulations are an inductive way of doing science: induction comes at the moment of explaining the behaviour of the model (Axelrod 1997). Epstein qualifies the agent-based simulation approach as 'generative' (Epstein 1999), while the logic behind it refers to abduction (Leombruni 2002).
12These statistics can either be a macro aggregate, or a micro indicator, as in the case of individual strategies. In both cases, as a general rule all individual actions, which in turn depend on individual states, matter.
13Sometimes we are interested in the relationship between different (aggregate) statistics: e.g. the unemployment rate and the inflation rate in a model with individuals searching on the job market and firms setting prices. The analysis proposed here is still valid however: once the dynamics of each statistics is known over time, the relationship between them is univocally determined.
14This definition applies both to the traditional homo sociologicus and the traditional homo oeconomicus. In the first paradigm individuals follow social norms and hence never change their behaviour. In the latter, individuals with rational expectations maximize their utility.
15Or even not dependent on the initial conditions
16Here, the distinction between in-sample and out-of-sample values, and the objection that two formulations may fit equally well the first, but not the latter, is not meaningful. Any value in the relevant range can be included in the artificial experiments.
17Ergodicity means that a time average is indeed representative of the full ensemble. So, if the system is ergodic, each simulation run gives a good description of the overall behavior of the system.
18For an overview on the discussion see Dawkins et al. 2001, pp. 3661ff.
19Homomorphism is used as the criterion for validity rather than isomorphism, because the goal of abstraction is to map an n-dimensional system onto an m-dimensional system, where m < n. If m and n are equal, the systems are isomorphic.
20For a discussion on the confusion that surrounds the basic definition of validity, see Bailey (1988).
21The Object Management Group (OMG) is an open membership, not-for-profit consortium that produces and maintains computer industry specifications for interoperable enterprise applications. Among its members are the leading companies in the computer industry (see http://www.omg.org).
22For an agent based modeller the concept of an actor may create some confusion. According to the UML symbolism, each object or class defined within the software architecture is represented by squared boxes (the class notation), while each external element (like human operators, hardware equipment) interacting with the software is represented by a stylized human symbol (the actor).
23JAS ( http://jaslibrary.sourceforge.net); RePast ( http://repast.sourceforge.net)
24The state of the system is updated (i.e. observed) only at discrete (generally constant) time intervals. No reference is made to the timing of events within a period.
25The state of the system is updated every time a new event occurs. All events are isolated and their exact timing defined.
26auction, book, etc.
27bargaining, etc.
28The behaviour of all meaningful individual and aggregate variables is explored, with reference to the results currently available in the literature. For instance, in a model of labour participation, if firm production is defined, aggregate production (business cycles, etc.) is also investigated.
29The model is investigated only with respect to the behaviour of some variables of interest
30defined as a state where individual strategies do not change anymore.
31defined as a state where some relevant (aggregate) statistics of the system becomes stationary.
ANDERSON, P.W., Arrow, K.J., Pines, D. (ed.) (1988) The Economy as an Evolving Complex System, Addison-Wesley Longman.
ANDREONI, J., Miller, J. (1995) Auctions with adaptive artificial agents Games and Economic Behavior, 10, pp. 39-64.
ARIFOVIC, J. (1995) Genetic algorithms and inflationary economies Journal of Monetary Economics, 36(1), pp. 219-243.
ARIFOVIC, J. (1996) The behavior of the exchange rate in the genetic algorithm and experimental economies Journal of Political Economy, vol. 104 n. 3, pp. 510-541.
ARTHUR, B. (1991) On designing economic agents that behave like human agents: A behavioral approach to bounded rationality American Economic Review, n. 81, pp. 353-359.
ARTHUR, B. (1994) Inductive reasoning and bounded rationality American Economic Review, n. 84, p. 406.
ATTANASIO, O.P. and Weber, G. (1993) Consumption Growth, the Interest Rate and Aggregation Review of Economic Studies 60, pp. 631-649.
ATTANASIO, O.P. and Weber, G. (1994) The UK Consumption Boom of the Late 1980's: Aggregate Implications of Microeconomic Evidence The Economic Journal 104, pp. 1269-1302.
AXELROD, R.M. (1987) The Evolution of Strategies in the iterated Prisoner's Dilemma, in L.D. Davis (ed.) Genetic Algorithms and Simulated Annealing, London, Pitman, pp. 32-41.
AXELROD, R. (1997), The Complexity of Cooperation: Agent-Based Models of Competition and Collaboration, Princeton, New Jersey: Princeton University Press
BAILEY, K.D. (1988) The Conceptualization of Validity. Current Perspectives Social Science Research, 17, pp. 117-136.
BAUER, B., Odell, J., Parunak, H. (2000) Extending UML for Agents in G. Wagner, Y. Lesperance, E. Yu (eds.) Proceedings of the Agent-Oriented Information Systems Workshop (AOIS), Austin, pp. 3-17.
BAUER, B., Muller, J.P., Odell, J. (2001) Agent UML: a formalism for specifying multiagent software systems International Journal on Software Engineering and Knowledge Engineering (IJSEKE), vol. 1, n. 3.
CHATTOE, E.S., Saam, N.J., Möhring, M. (2000) Sensitivity analysis in the social sciences: problems and prospects in G.N. Gilbert, U. Mueller, R. Suleiman, K.G. Troitzsch, (eds.) Social Science Microsimulation: Tools for Modeling, Parameter Optimization, and Sensitivity Analysis, Heidelberg, Physica Verlag, pp. 243-273.
CLARKSON, G.P.E., Simon, H.A. (1960), Simulation of Individual and Group Behavior, The American Economic Review, vol. 50, n. 5, pp.920-932
COHEN, K.J. (1960), Simulation of the firm The American Economic Review, vol. 50, n. 2, Papers and Proceedings of the Seventy-second Annual Meeting of the American Economic Association, pp. 534-540
COHEN, K.J., Cyert R.M. (1961), Computer Models in Dynamic Economics The Quarterly Journal of Economics, vol. 75, n. 1, pp. 112-127
DAWKINS, C., Srinivasan T.N., Whalley J. (2001) Calibration in J.J. Heckman, E. Leamer. (eds.) Handbook of Econometrics. Vol. 5. Elsevier, pp. 3653-3703.
DEIF, A.S. (1986) Sensitivity Analysis in Linear Systems, Berlin, Springer.
VAN DIJKUM, C., Detombe, D., van Kuijk, E. (eds.) (1999) Validation of Simulation Models, Amsterdam, SISWO.
EPSTEIN, J.M. (1999), Agent-Based Computational Models And Generative Social Science Complexity, vol. 4, pp. 41-60
FIACCO, A.V. (1983) Introduction to Sensitivity and Stability Analysis in Non-linear Programming, Paris, Academic Press.
FIACCO, A.V. (ed.) (1984) Sensitivity, Stability and Parametric Analysis, Amsterdam, North-Holland.
FREEMAN, R. (1998) War of the models: Which labour market institutions for the 21st century? Labour Economics, 5, pp. 1-24.
GODE, D. K., Sunder, S. (1993) Allocative efficiency of markets with zero-intelligence traders: Markets as a partial substitute for individual rationality Journal of Political Economy 101, pp. 119-137.
GOURIEROUX, C., Monfort, A. (1997) Simulation-based econometric methods, Oxford University Press.
HANSEN, L. P., and Heckman, J. J. (1996) The Empirical Foundations of Calibration, Journal of Economic Perspectives, vol. 10(1), pages 87-104.
HENDRY, D.F., Krolzig, H.M. (2001) Automatic econometric model selection, London, Timberlake Consultants Press.
HUBERMAN, B.A., Glance, N. (1993) Evolutionary Games and Computer Simulations, Proceedings of the National Academy of Sciences of the United States of America, 90, pp. 7716-7718.
HUGET, M. (2002) Agent UML class diagrams revisited in B. Bauer, K. Fischer, J. Muller, B. Rumpe (eds.), Proceedings of Agent Technology and Software Engineering (AgeS), Erfurt, Germany.
KALAITZIDAKIS, P., Mamuneas, T.P., Stengos, T. (2003) Rankings of academic journals and institutions in economics Journal of the European Economic Association vol. 1, n. 6, pp. 1346-1366.
KLEIJNEN, J.P.C. (1992) Sensitivity Analysis of Simulation Experiments: Regression Analysis and Statistical Design Mathematics and Computers in Simulation, n. 34, pp. 297-315.
KLEIJNEN, J.P.C. (1995a) Sensitivity Analysis and Optimization of System Dynamics Models: Regression Analysis and Statistical Design of Experiments in System Dynamics Review 11, pp. 275-288.
KLEIJNEN, J.P.C. (1995b) Sensitivity Analysis and Related Analyses: A Survey of Some Statistical Techniques Journal of Statistical Computation and Simulation, 57, pp. 111-142.
KLEVORICK, A.K. (ed.) (1983) Cowles fiftieth anniversary, Cowles Foundation, New Haven, Connecticut.
KÖHLER, J. (1996) Sensitivity Analysis of Integer Linear Programming, Discussion Paper, Fachbereich Mathematik und Informatik, Universität Halle-Wittenberg.
KYDLAND, F.E., Prescott, E.C. (1996), The Computational Experiment: An Econometric Tool Journal of Economic Perspectives, vol. 10, pp. 69-85
LANCASTER, T. (1990) The Econometric Analysis of Transition Data, Cambridge University Press.
LAW, A., Kelton, W.D. (1991) Simulation Modeling and Analysis, New York, McGraw-Hill, second edition.
LAWLESS, J. (1982) Statistical Models and Methods for Lifetime Data, John Wiley.
LEOMBRUNI, R. (2002), The methodological Status of Agent Based Simulations LABORatorio R. Revelli Working Paper no. 19
LEOMBRUNI, R., Richiardi, M.G. (2005) Why are Economists Sceptical About Agent-Based Simulations?, Physica A. Vol.355, No. 1, pp. 103-109.
MARIANO, B., Weeks, M., Schuermann T. (eds.) (2000), Simulation Based Inference: Theory and Applications, Cambridge, Cambridge University Press.
MERZ, J. (1994) Microsimulation - A Survey of Methods and Applications for Analyzing Economic and Social Policy, FFB Discussion Paper, n. 9, Universität Luneburg, June.
MILLER, J.H., Rust, J., Palmer, R. (1994) Characterising Effective Trading Strategies: Insights from a Computerised Double Auction Tournament Journal of Economic Dynamics and Control, 18, pp. 61-96.
MINAR, N., Burkhart, R., Langton, C., Askenazi, M. (1996) The Swarm Simulation System: A Toolkit for Building Multi-agent Simulations, Santa Fe Institute Working Paper, n. 96-06-042.
OMG (2003), Object Management Group, http://www.omg.org.
ORCUTT, G.H. (1960), Simulation of Economic Systems The American Economic Review, vol. 50, n. 5, pp. 893-907
RESNICK, M. (1994) Turtles, Termites and Traffic Jams: Explorations in Massively Parallel Microworlds, Cambridge MA, MIT Press.
ROS INSUA, D. (1990) Sensitivity Analysis in Multi Objective Decision Making, Berlin, Springer.
SCHELLING, T. (1969) Models of Segregation in American Economic Review, n. 59, pp. 488-493.
SHUBIK, M. (1960), Simulation of the Industry and the Firms The American Economic Review, vol. 50, n. 5, pp.908-919
SI ALHIR S. (2003), Learning UML, O' Reilly & Associates
SONNESSA, M. (2004) Modelling and simulation of complex systems, PhD Thesis, "Cultura e impresa", University of Torino, Italy.
STANISLAW, H. (1986) Tests of computer simulation validity. What do they measure? Simulation and Games 17, pp. 173-191.
STERMAN, J.D. (1984) Appropriative summary statistics for evaluating the historic fit of system dynamics models Dynamica 10, pp. 51-66.
TESFATSION, L. (2001a) Special issue on agent-based computational economics Journal of Economic Dynamics and Control 25, pp. 3-4.
TESFATSION, L. (2001b) Special issue on agent-based computational economics Computational Economics , vol. 18, n. 1.
TESFATSION, L. (2001c) Agent-based computational economics: A brief guide to the literature, in J. Michie (ed.) Reader's Guide to the Social Sciences, vol. 1, London, Fitzroy-Dearborn.
TRAIN, K. (2003), Discrete Choice Methods with Simulations, Cambridge, Cambridge University Press.
TULLOCK, G., Campbell, C.D. (1970) Computer simulation of a small voting system Economic Journal, vol. 80 n. 317, pp. 97-104.
VANDIERENDONCK, A. (1975) Inferential simulation: hypothesis-testing by computer simulation Nederlands Tijdschrift voor de Psychologie 30, pp. 677-700.
WAN, H.A. Hunter, A., Dunne, P. (2002) Autonomous Agent Models of Stock Markets Artificial Intelligence Review 17, pp. 87-128.
WEIBULL, J.W. (1995) Evolutionary Game Theory, Cambridge, MA, MIT Press.
WEISBUCH, G., Kirman, F., Herreiner, A. (2000) Market organization and trading relationships Economic Journal 110, pp. 411-436.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2006]