
Paul Windrum, Giorgio Fagiolo and Alessio Moneta (2007)
Empirical Validation of Agent-Based Models: Alternatives and Prospects
Journal of Artificial Societies and Social Simulation
vol. 10, no. 2, 8
<https://www.jasss.org/10/2/8.html>
For information about citing this article, click here
Received: 22-May-2006 Accepted: 08-Jan-2007 Published: 31-Mar-2007

 Abstract
Abstract| (z)i = { zi, t, t = t 0, …, t1}, i ∈ I. |
Here the set I refers to a population of agents (e.g. firms and households) whose behaviour has been observed across the finite set of time-periods {t0, …, t1} and refers to a list of, say, K variables contained in the vector z. Whenever agent-level observations are not available, the modeller has access to the K-vector of aggregate time-series:
| Z = { Zt, t = t 0, …, 1}, |
which can be obtained by summing up (or averaging out) the K micro-economic variables zi,t, over i ∈ I. In both cases, the observed dataset(s) generate(s) a number of 'stylised facts' or statistical properties that the modeller is seeking to explain.
|
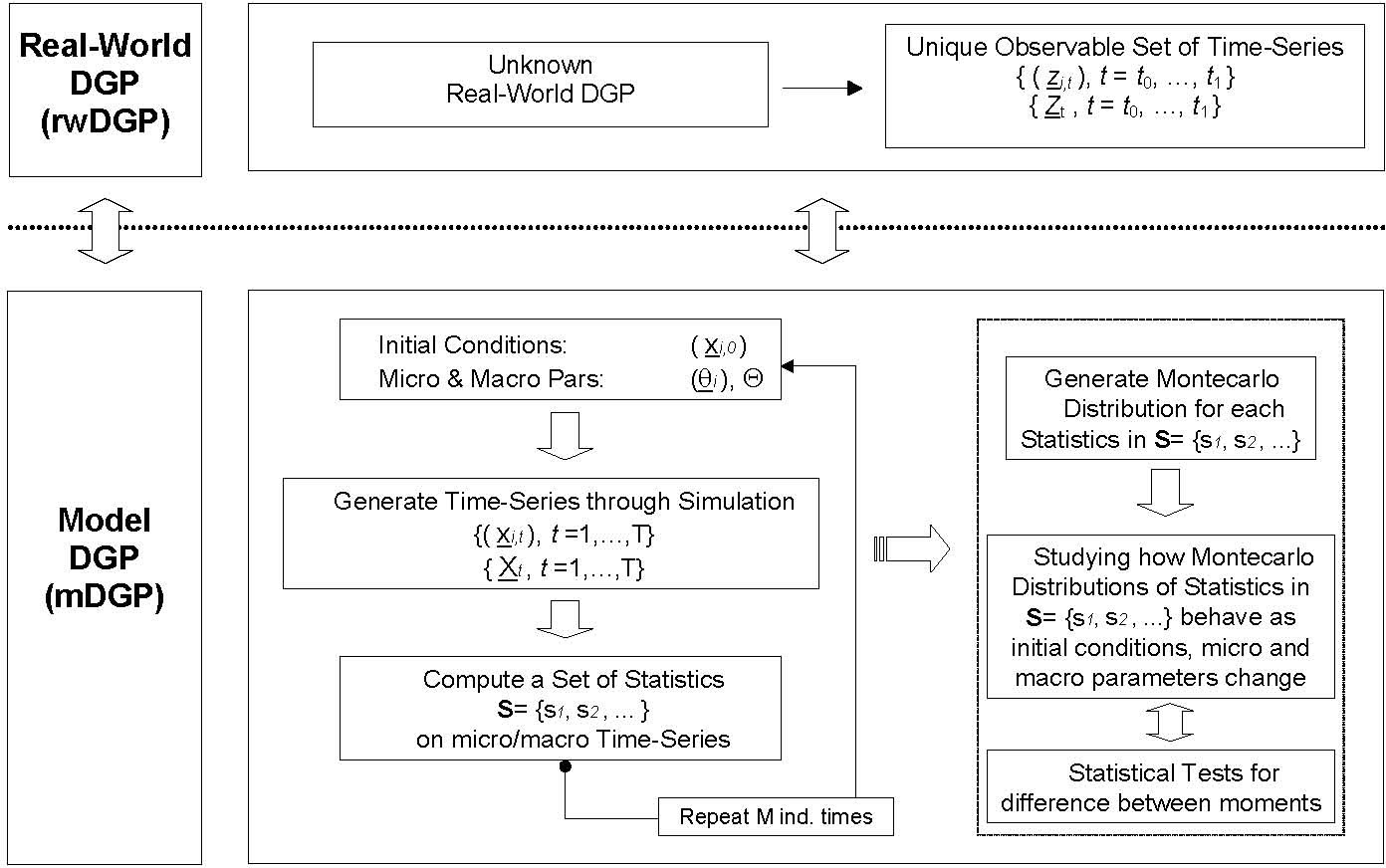
| Figure 1. A procedure for studying the output of an AB model |
|
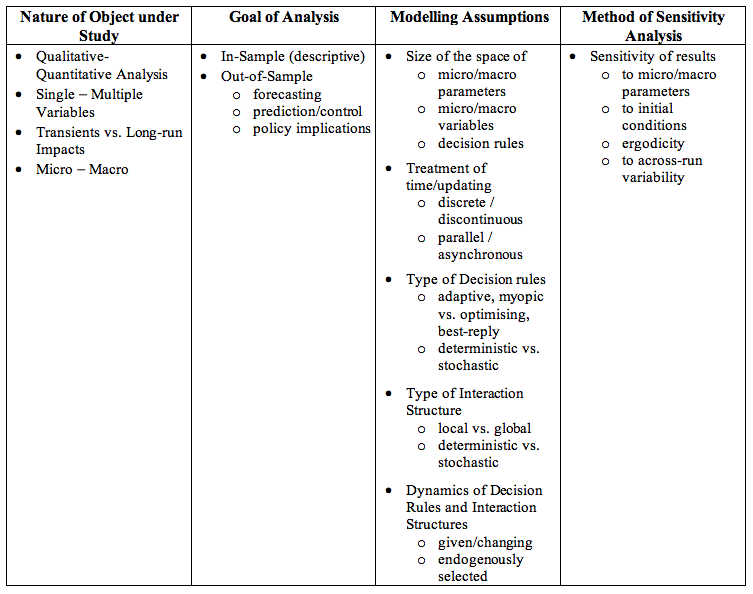
| Table 1. Taxonomy of dimensions of heterogeneity in AB models |
| Table 2: Differences between the types of data collected and their application | ||||
| Empirical domain | The types of data used | The application of data | Order of application | |
| Indirect Calibration Approach | - Micro (industries, markets) - Macro (countries, world economy) | - Empirical data | - Assisting in model building - Validating simulated output | - First validate, then indirectly calibrate |
| Werker-Brenner Approach | - Micro (industries, markets) - Macro (countries, world economy) | - Empirical data - Historical knowledge | - Assisting in model building - Calibrating initial conditions and parameters - Validating simulated output | - First calibrate, then validate |
| History-Friendly Approach | - Micro (industries, markets) | - Empirical data - Casual, historical and anecdotic knowledge | - Assisting in model building - Calibrating initial conditions and parameters - Validating simulated output | - First calibrate, then validate |
2An alternative view (though one which we doubt would be shared by most AB economists themselves) is that the AB approach is complementary to neoclassical economics. Departures from standard neoclassical assumptions, found in AB models, can be interpreted as 'what if', instrumentalist explorations of the space of initial assumptions. For example, what happens if we do not suppose hyper-rationality on the part of individuals?, What if agents decide on the basis of bounded rationality?
3At a special session on 'Methodological Issues in Empirically-based Simulation Modelling', hosted by Fagiolo and Windrum at the 4th EMAEE conference, Utrecht, May 2005, and at the ACEPOL 2005 International Workshop on 'Agent-Based Models for Economic Policy Design', Bielefeld, July 2005.
4Quite often it is not only impossible not only to know the real world DGP but also to get good a quality data set on the 'real world'. The latter problem is discussed in section 5.
5The focus in this paper is the concept of empirical validity. That is, the validity of a model with respect to data. There are other meanings of validity, which are in part interrelated with empirical validity, but which we will not consider here. Examples include model validity (the validity of a model with respect to the theory) and program validity (the validity of the simulation program with respect to the model). The reader is referred to Leombruni et al. (2006).
6Indeed, several possible qualifications of realism are possible (see Mäki 1998).
7The reader is referred to Moneta (2005) for an account of realist and anti-realist positions on causality in econometrics.
8The main theories of confirmation can be divided in probabilistic theories of confirmation, in which evidence in favour of a hypothesis is evidence that increases its probability, and non-probabilistic theories of confirmation, associated with Popper, Fisher, Neyman and Pearson. The reader is referred to Howson (2000).
9For example, one of the micro variables might be an individual firm's output and the corresponding macro variable may be GNP. In this case, we may be interested in the aggregate statistic sj defined as the average rate of growth of the economy over T time-steps (e.g. quarterly years).
10Consider the example of the previous footnote once again. One may plot E(sj), that is the Monte-Carlo mean of aggregate average growth rates, against key macro parameters such as the aggregate propensity to invest in R&D. This may allow one to understand whether the overall performance of the economy increases in the model with that propensity. Moreover, non-parametric statistical tests can be conducted to see if E(sj) differs significantly in two extreme cases, such as a high vs. low propensity to invest in R&D.
11Space constraints prevent us from discussing how different classes of AB models (e.g. evolutionary industry and growth models, history-friendly models, and ACE models) fit each single field of the entries in Table 1. See Windrum (2004), and Dawid (2006) for detailed discussions of this topic. The taxonomy presented in Table 1 partly draws from Leombruni et al. (2006). The reader is also referred to Leigh Tesfatsion's web site on empirical validation (http://www.econ.iastate.edu/tesfatsi/empvalid.htm).
12For examples along this line, see Marks 2005; Koesrindartoto et al., 2005; and the papers presented at the recent conference 'Agent-Based Models for Economic Policy Design' (ACEPOL05), Bielefeld, June 30, 2005 - July, 2, 2005 (http://www.wiwi.uni-bielefeld.de/~dawid/acepol/).
13The pros and cons of this heterogeneity in modelling assumptions for AB economists were discussed in section 1 of this paper. Also see Richiardi (2003), Pyka and Fagiolo (2005), and Leombruni et al. (2006).
14In discussing these three approaches we do not claim exhaustiveness (indeed other methods can be conceived). We selected these approaches because they are the most commonly used approaches to validate AB economics models.
15Obviously, there is no methodological prohibition of doing that. However, the researcher often wants to keep as much degrees of freedom as possible.
16See for example the calibration exercises performed by Bianchi et al. (2005) on the CATS model developed in a series of papers by Gallegati et al. (2003, 2005).
17An important issue related to time-scales in AB models, which we shall just mention here, concerns the choice made about timing in the model. Whether we assume that the time-interval [t, t+1] describes a day, or a quarter, or a year (and whether one supposes that the 'updating scheme' is asynchronous or parallel), has non-trivial consequences for calibration and empirical validation.
18See Windrum (1999) for a detailed discussion of early neo-Schumpeterian models.
19Interested readers are directed to Windrum (2004) for a detailed critique of history-friendly modelling.
20A well-known example of the contestability of history is evidenced by the ongoing debate about whether inferior quality variants can win standards battles (Leibowitz and Margolis 1990; Arthur 1988). As Carr (1961) observed in his classic work, history can be contestable at more fundamental and unavoidable levels.
21A quite related open-issue, as suggested by an anonymous referee, is the inter-relationship between validation and policy implications. Indeed, if one is concerned with a particular policy question, one could have a more pragmatic approach of the kind: "validation of the model for the purpose at hand is successful if, using the available observations of the rwDGP, the set of potential mDGPs can be restricted in a way that the answer to the posed policy question is the same no matter which mDGP from that set is chosen".
BIANCHI C, Cirillo P, Gallegati M and Vagliasindi P (2005) Validation in ACE models. An investigation of the CATS model. Unpublished Manuscript.
BRENNER T (2004) Agent learning representation — advice in modelling economic learning, Papers on Economics and Evolution. Jena: Max Planck Institute.
BRENNER T and Murmann, J P (2003) The use of simulations in developing robust knowledge about causal processes: methodological considerations and an application to industrial evolution, Papers on Economics and Evolution #0303. Jena: Max Planck Institute.
BROCK W (1999) Scaling in economics: a reader's guide. Industrial and Corporate Change, 8, pp. 409-446.
CARR E H (1961) What is History?, London: Macmillan.
CHATTOE E (2002) Building Empirically Plausible Multi-Agent Systems: A Case Study of Innovation Diffusion. In Dautenhahn K (Ed.) Socially Intelligent Agents: Creating Relationships with Computers and Robots. Dordrecht Kluwer.
COWAN R and Foray D (2002) Evolutionary economics and the counterfactual threat: on the nature and role of counterfactual history as an empirical tool in economics, Journal of Evolutionary Economics, 12 (5), pp. 539-562.
DAWID H (2006) Agent-based models of innovation and technological change. In Tesfatsion L and Judd K (Eds.) Handbook of Computational Economics II: Agent-based Computational Economics, Amsterdam: North-Holland.
DORAN J (1997) From computer simulation to artificial societies. SCS Transactions on Computer Simulation, 14 (2), pp. 69-78.
DOSI G (1988) Sources, procedures and microeconomic effects of innovation. Journal of Economic Literature, 26, pp. 126-171.
DOSI G., Fagiolo G. and Roventini A. (2006) An Evolutionary Model of Endogenous Business Cycles. Computational Economics, 27, pp. 3-34.
DOSI G, Freeman C and Fabiani S (1994) The process of economic development: introducing some stylized facts and theories on technologies, firms and institutions. Industrial and Corporate Change, 3, pp. 1-46.
DOSI G and Nelson R R (1994) An introduction to evolutionary theories in economics. Journal of Evolutionary Economics, 4, pp. 153-172.
DOSI G and Orsenigo L (1994) Macrodynamics and microfoundations: an evolutionary perspective. In Granstrand O (Ed.) The economics of technology. Amsterdam: North Holland.
DOSI G, Marengo L and Fagiolo G (2005) Learning in Evolutionary Environment. In Dopfer K (Ed.) Evolutionary Principles of Economics. Cambridge: Cambridge University Press.
EDMONDS B and Moss S (2005) From KISS to KIDS — an 'anti-simplistic' modelling approach. In Davidsson P, Logan B, Takadama K (Eds.) Multi Agent Based Simulation 2004. Lecture Notes in Artificial Intelligence. Springer, 3415, pp.130-144.
FAGIOLO G (1998) Spatial interactions in dynamic decentralized economies: a review. In Cohendet P, Llerena P, Stahn H and Umbhauer G (Eds.) The Economics of Networks. Interaction and Behaviours, Berlin — Heidelberg: Springer Verlag.
FAGIOLO G and Dosi G (2003) Exploitation, Exploration and Innovation in a Model of Endogenous Growth with Locally Interacting Agents, Structural Change and Economic Dynamics, 14, pp. 237-273.
FAGIOLO G, Dosi G and Gabriele R (2004a) Matching, Bargaining, and Wage Setting in an Evolutionary Model of Labor Market and Output Dynamics, Advances in Complex Systems, 14, pp. 237-273.
FAGIOLO G, Marengo L and Valente M (2004b) Endogenous Networks in Random Population Games. Mathematical Population Studies, 11, pp. 121-147.
FRENKEN K. (2005) History, state and prospects of evolutionary models of technical change: a review with special emphasis on complexity theory, Utrecht University, The Netherlands, mimeo.
FRIEDMAN M (1953) The Methodology of Positive Economics, in Essays in Positive Economics. Chicago: University of Chicago Press.
GALLEGATI M, Giulioni G, Palestrini A and DelliGatti D (2003) Financial fragility, patterns of firms' entry and exit and aggregate dynamics. Journal of Economic Behavior and Organization, 51, pp. 79-97.
GALLEGATI M, Gatti D D, Guilmi C D, Gaeo E, Giulioni G and Palestrini A (2005) A new approach to business fluctuations: heterogeneous interacting agents, scaling laws and financial fragility. Journal of Economic Behavior Organization, 56, pp. 489-512.
GIBBARD A and Varian H (1978) Economic Models. Journal of Philosophy, 75, pp. 664-677.
GILBERT N and Troitzsch K (1999) Simulation for the Social Scientist. Milton Keynes: Open University Press.
HAAVELMO T (1944) The Probability Approach in Econometrics, Econometrica, 12, pp. 1-115.
HOWSON C (2000) Evidence and Confirmation. In Newton-Smith W H (Ed.) A Companion to the Philosophy of Science. Malden, MA: Blackwell Publishers, pp. 108-116.
JANSSEN M C W (1994) Economic Models and Their Applications, Poznan Studies in the Philosophy of the Science and the Humanities, 38, pp. 101-116.
KIRMAN A P (1997a) The Economy as an Interactive System. In Arthur W B, Durlauf S N and Lane D (Eds.) The Economy as an Evolving Complex System II, Santa Fe Institute, Santa Fe and Reading, MA: Addison-Wesley.
KIRMAN A P (1997b) The Economy as an Evolving Network, Journal of Evolutionary Economics, 7, pp. 339-353.
KNIGHT F H (1921) Risk, Uncertainty, and Profits. Chicago: Chicago University Press.
KOESRINDARTOTO D, Sun J and Tesfatsion L (2005) An Agent-Based Computational Laboratory for Testing the Economic Reliability of Wholesale Power Market Designs, IEEE Power Engineering Society Conference Proceedings.
LAKATOS I (1970) Falsification and the Methodology of Scientific Research Programmes. In Lakatos I and Musgrave A, Criticism and the Growth of Knowledge, Cambridge: Cambridge University Press, pp. 91-196.
LANE D (1993a) Artificial worlds and economics, part I, Journal of Evolutionary Economics, 3, pp. 89-107.
LANE D (1993b) Artificial worlds and economics, part II, Journal of Evolutionary Economics, 3, pp. 177-197.
LAW A and Kelton W D (1991) Simulation Modeling and Analysis. New York: McGraw-Hill.
LEAMER E E (1978) Specification Searches, Ad Hoc Inference with Nonexperimental Data. New York: John Wiley.
LIEBOWITZ S J and Margolis S E (1990) The Fable of the Keys, Journal of Law and Economics, 22, pp. 1-26.
LEOMBRUNI R (2002) The Methodological Status of Agent-Based Simulations, Working Paper No. 19. Turin, Italy: LABORatorio R. Revelli, Centre for Employment Studies.
LEOMBRUNI R, Richiardi M, Saam, N and Sonnessa M. (2006) A Common Protocol for Agent-Based Social Simulation, Journal of Artificial Societies and Social Simulation, 9(1) https://www.jasss.org/9/1/15.html.
MÄKI U (1992) On the Method of Isolation in Economics, Poznan Studies in the Philosophy of the Sciences and the Humanities, 26, pp. 19-54.
MÄKI U (1998) Realism. In Davis J B, Hands D W and Mäki U (Eds.) The Handbook of Economic Methodology. Cheltenham, UK: Edward Elgar. pp. 404-409.
MÄKI U (2003) 'The methodology of positive economics' (1953) does not give us the methodology of positive economics, Journal of Economic Methodology, 10(4), pp. 495-505.
MÄKI U (2005) Models are experiments, experiments are models, Journal of Economic Methodology, 12(2), pp. 303-315.
MALERBA F and Orsenigo L (2001) Innovation and market structure in the dynamics of the pharmaceutical industry and biotechnology: towards a history friendly model, Conference in Honour of Richard Nelson and Sydney Winter, Aalborg, 12th — 15th June 2001.
MALERBA F, Nelson R R, Orsenigo L and Winter S G (1999) History friendly models of industry evolution: the computer industry, Industrial and Corporate Change, 8, pp. 3-41.
MARENGO L and Willinger M (1997) Alternative Methodologies for Modeling Evolutionary Dynamics: Introduction, Journal of Evolutionary Economics, 7, pp. 331-338
MARKS B (2005) Agent-Based Market Design, Australian Graduate School of Management, mimeo.
MONETA A (2005) Causality in Macroeconometrics: Some Considerations about Reductionism and Realism, Journal of Economic Methodology, 12(3), pp. 433-453.
MORRISON M and Morgan M S (1999) Models as mediating instruments. In Morgan M S and Morrison M (Eds.) Models as Mediators. Perspectives on Natural and Social Science. Cambridge: Cambridge University Press. pp. 10-37,
NELSON R R and Winter S G (1982) An Evolutionary Theory of Economic Change. Cambridge: Harvard University Press.
NELSON R R (1995) Recent Evolutionary Theorizing About Economic Change, Journal of Economic Literature, 33, pp. 48-90.
PYKA A and Fagiolo G (2005) Agent-Based Modelling: A Methodology for Neo-Schumpeterian Economics. In Hanusch H and Pyka A (Eds.) The Elgar Companion to Neo-Schumpeterian Economics. Cheltenham: Edward Elgar.
RICHIARDI M (2003) The Promises and Perils of Agent-Based Computational Economics, Working Paper No. 29. Turin, Italy: LABORatorio R. Revelli, Centre for Employment Studies.
SAVIOTTI P P and Pyka A (2004) Economic development, qualitative change and employment creation, Structural Change and Economics Dynamics, 15(3), pp. 265-287.
SAWYER K R, Beed C and Sankey H (1997) Underdetermination in Economics. The Duhem-Quine Thesis, Economics and Philosophy 13, pp. 1-23.
SCHORFHEIDE F (2000) Loss function-based evaluation of DSGE models, Journal of Applied Econometrics, 15(6), pp. 645-670.
SILVERBERG G and Verspagen B (1995) Evolutionary theorizing on economic growth, IIASA, Laxenburg, Austria, Working Paper, WP-95-78.
SILVERBERG G, Dosi G and Orsenigo L (1988) Innovation, diversity and diffusion: a self-organisation model, Economic Journal, 98, pp. 1032-1054.
TESFATSION L (1997) How Economists Can Get A Life. In Arthur, W, Durlauf S and Lane D (Eds.) The Economy as an Evolving Complex System II. SantaFeInstitute, Santa Fe and Reading, MA: Addison-Wesley.
TESFATSION L (2002) Agent-based Computational Economics: Growing Economies from the Bottom Up, Artifical Life, 8, pp. 55-82.
VALENTE M (2005) Qualitative Simulation Modelling, Faculty of Economics, University of L'Aquila, L'Aquila, Italy, mimeo.
WERKER C and Brenner T (2004) Empirical Calibration of Simulation Models, Papers on Economics and Evolution # 0410. Jena: Max Planck Institute for Research into Economic Systems.
WINDRUM P (1999) Simulation models of technological innovation: a review, American Behavioral Scientist, 42(10), pp. 1531-1550.
WINDRUM P (2004) Neo-Schumpeterian simulation models, Merit Research Memoranda 2004-004, MERIT, University of Maastricht. Forthcoming in Hanusch H and Pyka A (Eds.) The Elgar Companion to Neo-Schumpeterian Economics. Cheltenham: Edward Elgar.
WINDRUM P (2005) Heterogeneous preferences and new innovation cycles in mature industries: the camera industry 1955-1974, Industrial and Corporate Change, 14(6), pp. 1043-1074.
WINDRUM P and Birchenhall C (1998) Is life cycle theory a special case?: dominant designs and the emergence of market niches through co-evolutionary learning, Structural Change and Economic Dynamics, 9, pp. 109-134.
WOOLDRIDGE M and Jennings N R (1995) Intelligent agents: theory and practice, Knowledge Engineering Review, 10, pp. 115-152.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]