
Wim Westera (2007)
Peer-Allocated Instant Response (PAIR): Computational Allocation of Peer Tutors in Learning Communities
Journal of Artificial Societies and Social Simulation
vol. 10, no. 2, 5
<https://www.jasss.org/10/2/5.html>
For information about citing this article, click here
Received: 02-Jan-2007 Accepted: 24-Feb-2007 Published: 31-Mar-2007

 Abstract
Abstract| T = Nout/Nin | (1) |
In order to ideally produce one tutor out of a cohort of n students, the transmission rate of the allocation filter would be 1/n. While the allocation algorithm rests on two separate filter types, subsequently the quality filter and the economy filter, a balanced filtering mechanism would assign each filter an equal transmission rate of 1/√ n.
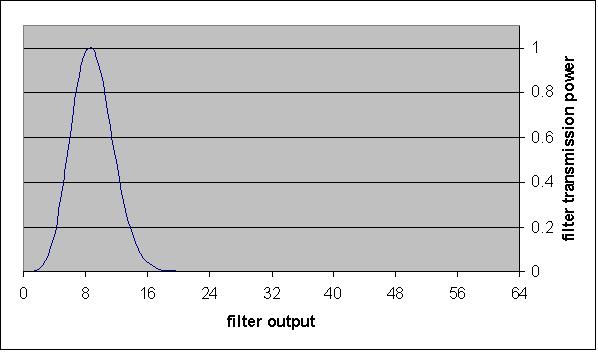
|
| Figure 1. Primary filtering power as a function of transmission, in case of two serial filters (n=64) |
| Score(i) = (t - t0(i,m) + 1) / (t - min(t0(i,m)) + 1) | (2) |
where
| Score(i)= tc(i,m) / t | (3) |
where
| Score(i)= (Of - S(i) + C(i)) / (Of + C(i)) | (4) |
where
| Score(i)= ((Ofr - 1) . S(i) + C(i)) / (Ofr . S(i) + C(i)) | (5) |
where
| Score(i)= (Ou - S(i) + <S(i)>i) / (Ou + <S(i)>i) | (6) |
where
| Score(i)= ((Our -1) . S(i) + <S(i)>i) / ((Our + 1) + <S(i)>i) | (7) |
where
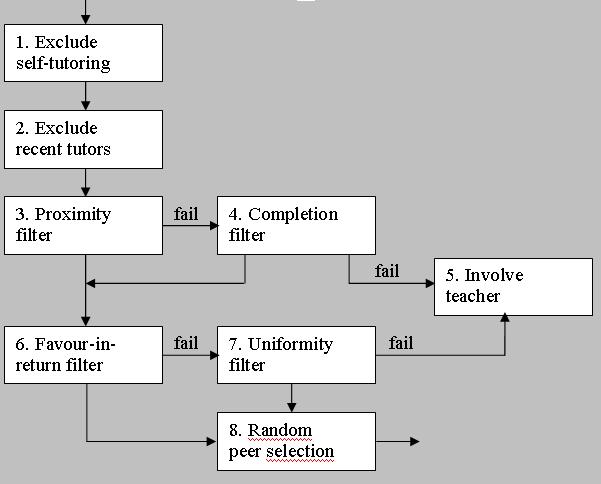
|
| Figure 2. The allocation procedure combining various filter types |
| Table 1: Specification of filtering routes | ||||
| Route ID | FILTERS | Quality criterion | Economy criterion | Outcome |
| I | 1-2-3-4-5 | Completion fails | none | Teacher |
| II | 1-2-3-6 | Proximity succeeds | Favour succeeds =1 | Student |
| III | 1-2-3-6-8 | Proximity succeeds | Favour succeeds >1 | Student |
| IV | 1-2-3-6-7 | Proximity succeeds | Uniform succeeds =1 | Student |
| V | 1-2-3-6-7-8 | Proximity succeeds | Uniform succeeds >1 | Student |
| VI | 1-2-3-6-7-5 | Proximity succeeds | Uniform fails | Teacher |
| VII | 1-2-3-4-6 | Completion succeeds | Favour succeeds =1 | Student |
| VIII | 1-2-3-4-6-8 | Completion succeeds | Favour succeeds >1 | Student |
| IX | 1-2-3-4-6-7 | Completion succeeds | Uniform succeeds =1 | Student |
| X | 1-2-3-4-6-7-8 | Completion succeeds | Uniform succeeds >1 | Student |
| XI | 1-2-3-4-6-7-5 | Completion succeeds | Uniform fails | Teacher |
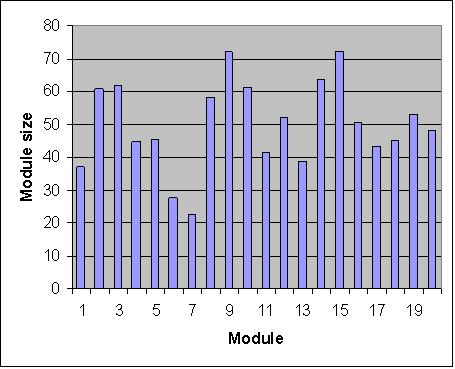
|
| Figure 3. Specimen: module size generated by a random trial from a normal distribution |
| Progress(i,m) = (t - t0(i,m)) / M1(m) / M2(m) . X1(i) . X2(i) . X3(i) | (8) |
where
| Eventtrigger(i) = Random[0,1] . X4((i)/ X1(i) / X2(i) | (9) |
where
| Table 2: Typical values of simulation parameters | |
| Population size | typically 100 |
| Average module size | typically 15 |
| Number of modules | typically 20 |
| Evaluation time | typically 200 |
| Average prior knowledge fraction | typically 0.10 |
| Request rate | typically 0.3 requests per student per unit of time |
| Overload (absolute) | typically 0-200 |
| Tutor dead-time | typically 2 |
| Standard deviation of normal distributions | typically 1/3 - 1/6 |
| Table 3: Overview of investigated allocation types | |||||
| Allocation type | A | B | C | D | |
| Filters | |||||
| Proximity filter | transmission ceiling (√n) | x | x | ||
| no transmission ceiling | x | x | |||
| Completion filter | transmission ceiling (√n) | x | x | ||
| no transmission ceiling | x | x | |||
| Favour-in-return filter | relative overload tolerance | x | x | ||
| absolute overload tolerance | x | x | |||
| Uniformity filter | relative overload tolerance | x | x | ||
| absolute overload tolerance | x | x | |||
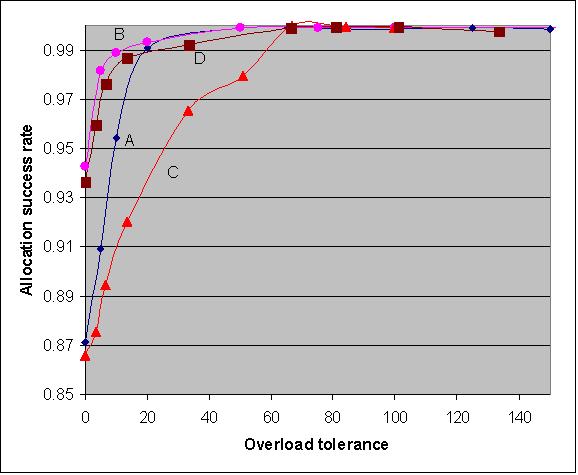
|
| Figure 4. Allocation success rates as a function of overload tolerance (conditions A, B, C and D, n = 100) |
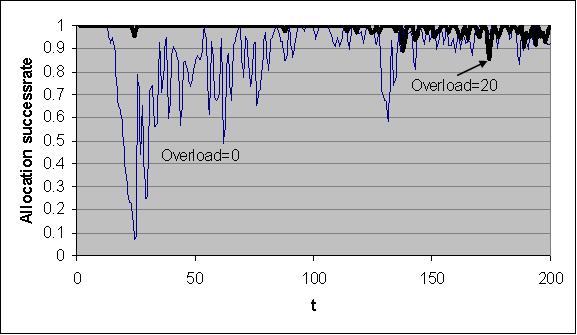
|
| Figure 5. Instantaneous allocation success rates as a function of time (condition A, n=100). |
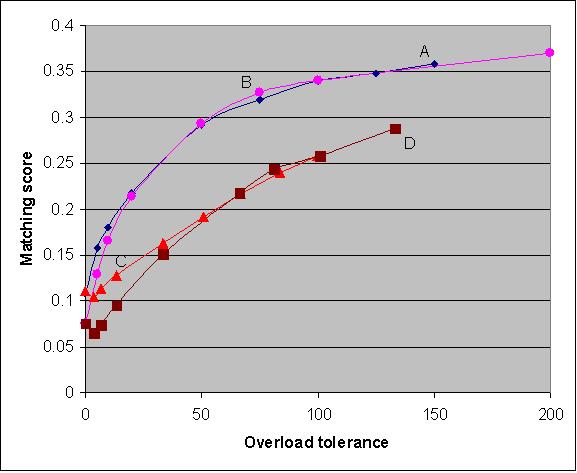
|
| Figure 6. Matching scores as a function of overload tolerance (conditions A, B, C and D, n=100) |
For all conditions the matching score increases with higher overloads. Indeed, raising the overload value allows more frequent allocation of the highest scoring tutor candidates. As a consequence the distribution of workload over the students shows larger deviations from uniformity: increasingly only part of the students provide most of the tutoring.
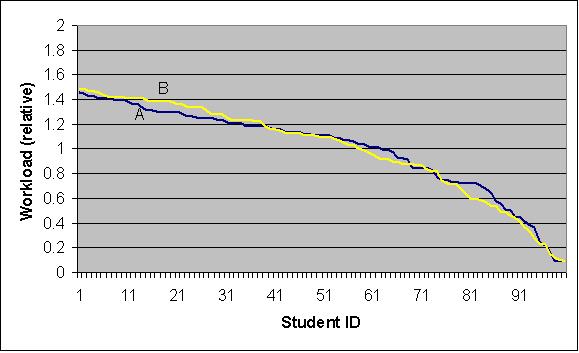
|
| Figure 7. Distribution of workload over students (conditions A and B, n=100) |
Conditions A and B show quite similar outcomes. While students will only be involved with one call at the time no accumulation of workload occurs. Also defining a dead time in order to recover from a tutoring activity counteracts accumulation.
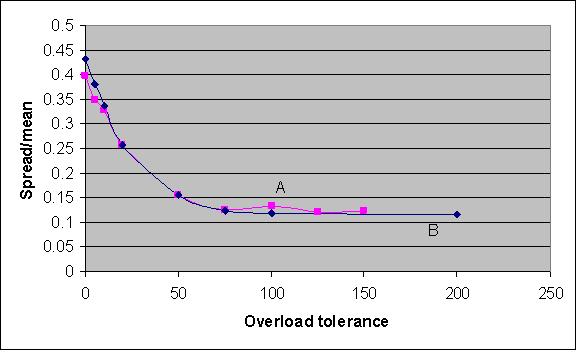
|
| Figure 8. Spread of tutoring load (conditions A and B, n=100) |
Note that the curves for condition A and B nearly coincide. Clearly, at increasing overload tolerance the spread decreases, which means that the distribution of workload becomes less uniform. Indeed, at higher values of overload tolerance there are hardly any restrictions for repeatedly selecting the best quality tutors. This is in accordance with the higher matching scores as displayed in figure 6.
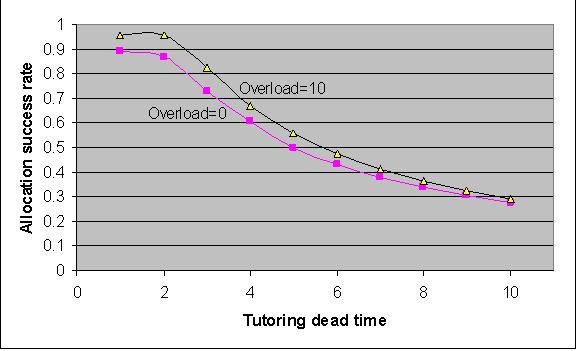
|
| Figure 9. Allocation success rate against tutoring dead time (condition A, n=100) |
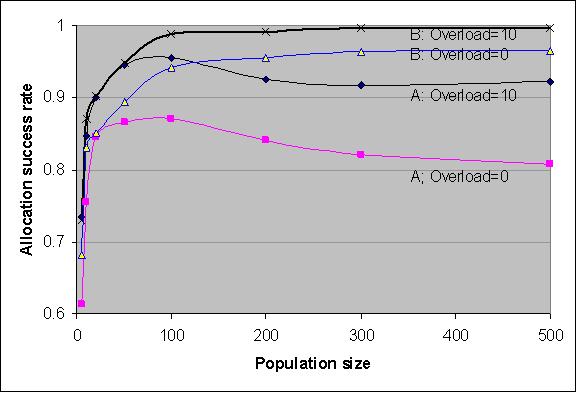
|
| Figure 10. Success rates at various population sizes (condition A and B) |
For condition A the allocation success rate shows a peak at moderate population sizes, while it slowly decreases at larger populations. The effect is significant and reproducible. It has has turned out that this effect is due to the cross-over mechanism that restricts the transmission power of the quality filter. Because of the nonlinear nature of the filter transmission ceiling (√n) the quality filter tends to select an increasingly smaller fraction of high quality candidates at larger populations. Indeed, at n=100 the transmission ceiling allows the 10% highest qualified candidates to pass; at n=500 this is reduced to the 4.4% (=1/√500). While these elite candidates are more likely to become eliminated in the economy filter, the cross-over mechanism work adversely. Therefore, at large populations one should be cautious with the cross-over ceiling mechanism. At larger populations omitting the cross-over mechanism produces higher allocation success rates.
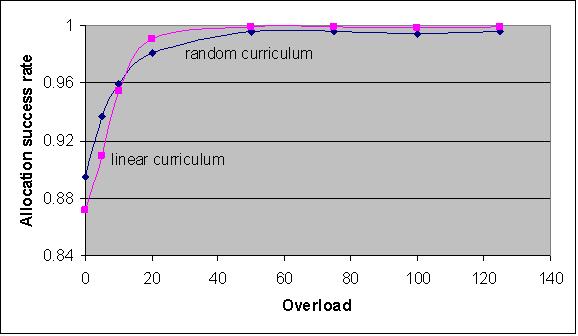
|
| Figure 11. Allocation success rates for a linear and a random curriculum (condition A, n=100) |
The results for the various curriculum types coincide within a few percents. Curriculum structure is thus concluded to be of little importance as a determinant.
BROWN, J.S., Collins, A. & Duguid, S. (1989). Situated cognition and the culture of learning. Educational Researcher, Vol. 18(1), pp. 32-42.
FANTUZZO, J W, Riggio, R E, Connelly, S and Dimeff, L A (1989) Effects of reciprocal peer tutoring on academic achievement and psychological adjustment: A component analysis. Journal of Educational Psychology, Vol. 81, pp. 173-177.
GERGEN, K (1995) "Social construction and the educational process". In Steffe L and Gale J (Eds.). Constructivism in education, (pp.17-39), Lawrence Erlbaum Associates,Inc.: New Jersey.
GYANANI, T C and Pahuja, P (1995) Effects of peer tutoring on abilities and achievement. Contemporary Educational Psychology, Vol. 20, pp. 469-475.
KING, A, Staffieri, A and Adelgais, A (1998) Mutual peer tutoring: Effects of structuring tutorial interaction to scaffold peer learning. Journal of Educational Psychology, Vol. 90, pp. 134-152.
VAN BRUGGEN, J, Sloep, P, Van Rosmalen, P, Brouns, F, Vogten, H, Koper, R and Tattersall, C (2004) Latent semantic analysis as a tool for learner positioning in learning networks for lifelong learning. British Journal of Educational Technology, Vol. 35 (6), pp. 729-738.
VAN ROSMALEN, P, Brouns, F, Tattersall, C, Vogten, H, van Bruggen, J, Sloep, P and Koper, R. (2005) Towards an open framework for adaptive, agent-supported e-learning. International Journal of Continuing Engineering Education and Lifelong Learning, Vol. 15 (3-6), pp. 261-275.
WESTERA, W (2001) Competences in Education: a confusion of tongues. Journal of Curriculum Studies, Vol. 33 (1), pp. 75-88.
WONG, W K, Chan, T W, Chou, C Y, Heh, J S and Tung, S H (2003) Reciprocal tutoring using cognitive tools. Journal of Computer Assisted Learning, Vol. 19, pp. 416-428.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]