
Fu-ren Lin and Shyh-ming Lin (2006)
Enhancing the Supply Chain Performance by Integrating Simulated and Physical Agents into Organizational Information Systems
Journal of Artificial Societies and Social Simulation
vol. 9, no. 4
<https://www.jasss.org/9/4/1.html>
For information about citing this article, click here
Received: 03-Jan-2005 Accepted: 12-Aug-2006 Published: 31-Oct-2006

 Abstract
Abstract
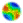
|
| Figure 1. The Swarm's nested inherent hierarchical structure |
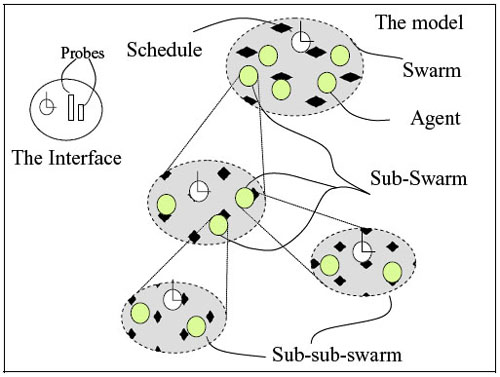
|
| Figure 2. FIPA Specification |
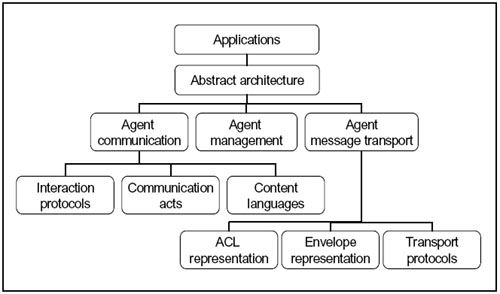
|
| Figure 3. The SPA embedded with information systems |
|
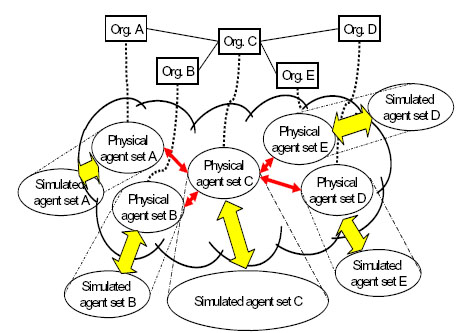
| Figure 4. The deployment of the SPA to an inter-organizational structure |
|
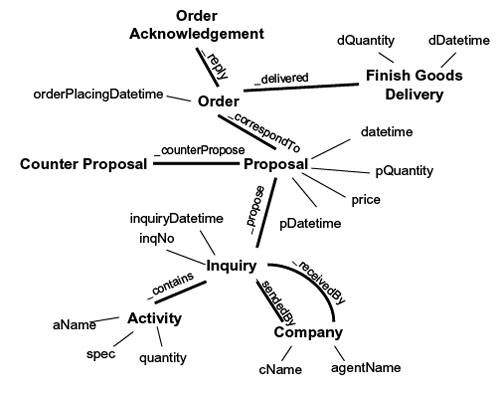
| Figure 5. Predefined ontology for physical agents' interaction |
|
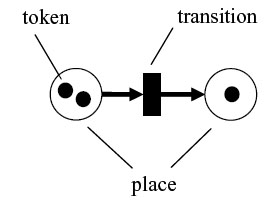
| Figure 6. A simple graphical Petri net |
|
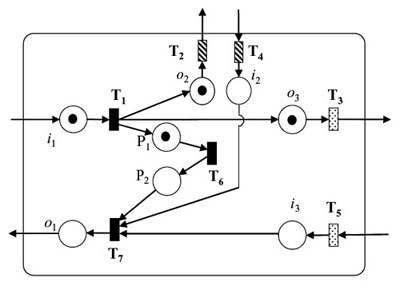
|
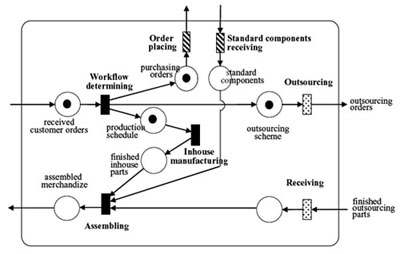
| (a) an organization modeled in OOPN | (b) the symbolized model |
| Figure 7. Modeling the operation of an assembly plant by using OOPN | |
| OOPN=(P, T, F, I, O, P0) | (3.1) |
where
| P ={P1, P2, …, Pn} | (3.2) |
| T ={T1, T2, …, Tn} | (3.3) |
| F ⊆ ( P × T) ∪ ( T × P) | (3.4) |
P is a set of places and T is a set of transitions. F is a set of directed linkages that link transitions and places. I is a set of input places which receive tokens from transitions of outside organizations. O is a set of output places which deliver tokens to transitions of outside organizations. P 0 is the initial marking (condition) of all places.

|
| Figure 8. BOM (bill of material) of a digital camera |
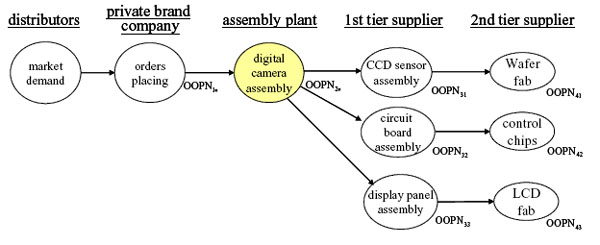
|
| Figure 9. The critical portion of supply chain of digital camera |
| PN = {OOPN11, OOPN21, OOPN31, OOPN32, OOPN33, OOPN41, OOPN42, OOPN43} | (4.1) |
| OOPNjk=( Pjk, T jk, Fjk, ijk, ojk, P jk0) | (4.2) |
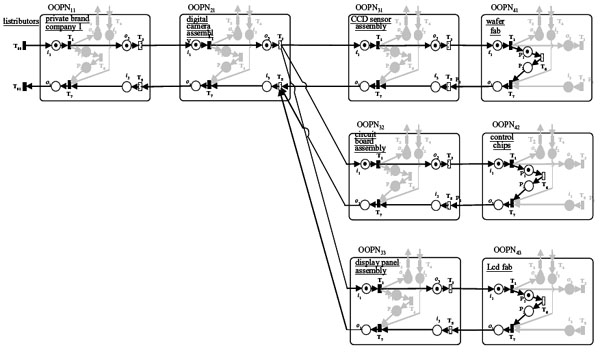
|
| Figure 10. The Petri net of the entire supply chain |

|
| Figure 11. XML file to describe the assembly plant |
|
|
(4.3) |
Where

|
|
|
(4.4) |
|
|
(4.5) |
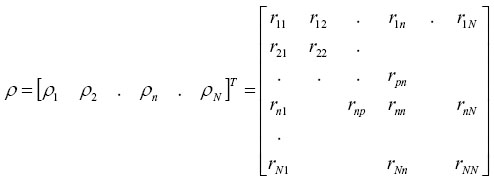
|
(4.6) |
|
|
(4.7) |
|
|
(4.8) |
|
|
(4.9) |
|
|
(4.10) |
|
|
(4.11) |
| Tjk={Tjk1, Tjk3, Tjk5, Tjk7} | (4.12) |
| ijk={ijk1, ijk3} | (4.13) |
| ojk={ojk1, ojk3} | (4.14) |
| Fjk={(ijk1, Tjk1), (Tjk1, ojk3), (ojk3, Tjk3), (Tjk5, ijk3), (ijk3, Tjk7), (Tjk7, ojk1)} | (4.15) |
| Tjk7 = f (ijk3, t jk7setup, t jk7unit) | (4.16) |
| Ljk = Ljk7 = t jk7setup + ijk3 * t jk7unit | (4.17) |
and with j = 4, we obtain OOPN as
| T4k={T4k1, T4k6, T4k7} | (4.18) |
| P4k={P4k1, P4k2} | (4.19) |
| F4k={(i4k1, T4k1), (T4k1, P4k1), (P4k1, T4k6), (T4k6, P4k2), (P4k2, T4k7), (T4k7, o4k1)} | (4.20) |
| T4kl = f (i4kl, t 4klsetup, t 4klunit) | (4.21) |
| L4kl = t 4klsetup + i4kl * t 4klunit | (4.22) |
| L4k = L4k6 + L4k7 | (4.23) |
|
F11,21={(T113, i211), (o211, T115)}, F21,31={(T213, i311), (o311, T215)}, F21,32={(T213, i321), (o321, T215)}, F21,33={(T213, i331), (o331, T215)}, F31,41={(T313, i411), (o411, T315)}, F32,42={(T323, i421), (o421, T325)}, F33,43={(T333, i431), (o431, T335)} |
(4.24) |

|
| Figure 12. The modified AGNES clustering algorithm |
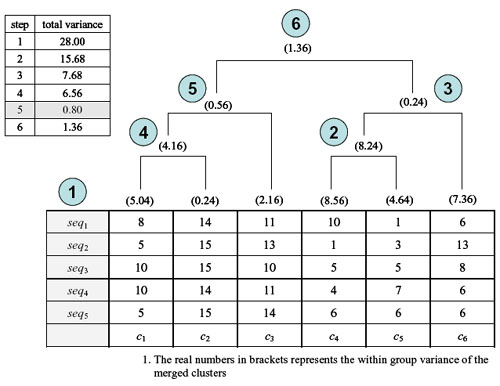
|
| Figure 13a. An example of a complete hierarchical clustering tree |
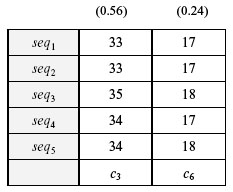
|
| Figure 13b. The optimal clustering results |
|
|
(4.25) |
|
|
(4.26) |
|
|
(4.27) |
|
|
(4.28) |
|
|
(4.29) |
|
|
(4.30) |
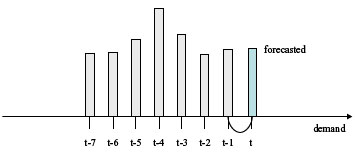
|
| (a) Simple forecasting |
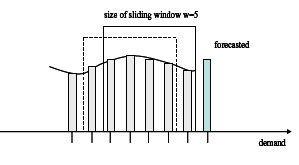
|
| (b) Moving average forecasting |
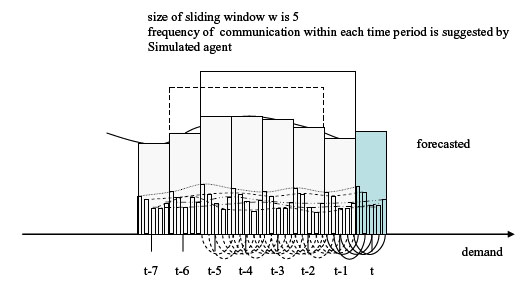
|
| (c) Cluster forecasting |
| Figure 14. Three tested methods |
|
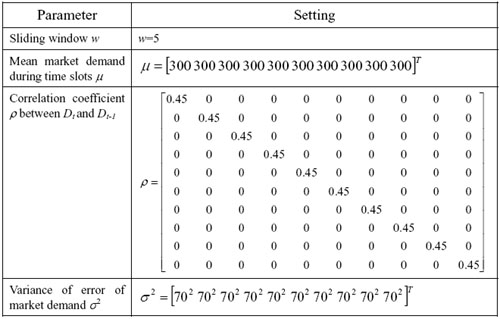
| Table 1. The settings of Experiment 1 |
|
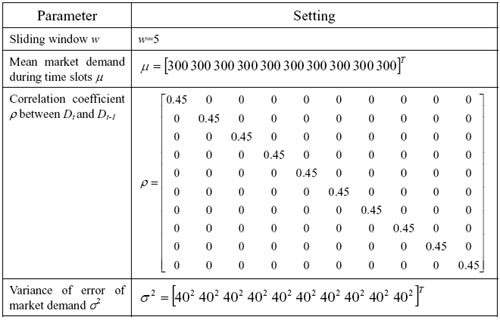
| Table 2. The settings of Experiment 2 |
|
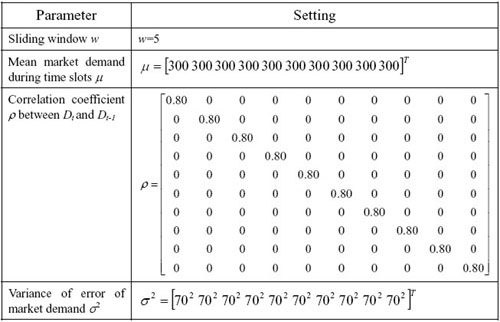
| Table 3. The settings of Experiment 3 |
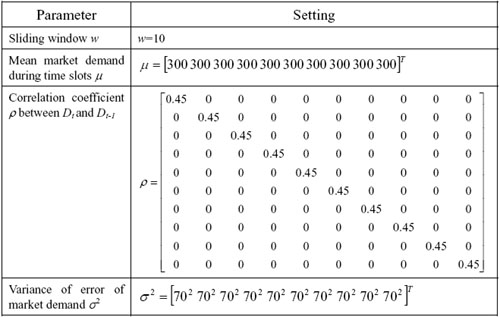
|
| Table 4. The settings of Experiment 4 |
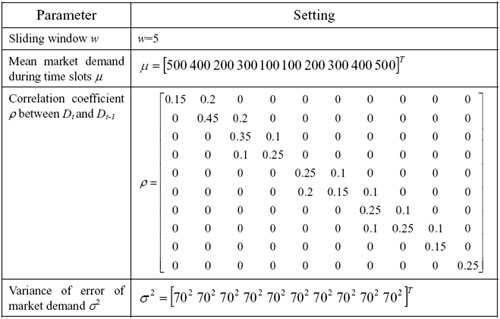
|
| Table 5. The settings of Experiment 5 |
| Table 6: Normalized made-up parameter values of activities in the supply chain | ||
| Transition | Setup time (tsjk) | Unit production / assembly time (tujk) |
| T117 | 3 | 0 |
| T217 | 2 | 0.003 |
| T317 | 0 | 0.002 |
| T327 | 0 | 0.001 |
| T337 | 0 | 0.004 |
| T416 | 0 | 0.002 |
| T426 | 0 | 0.001 |
| T436 | 0 | 0.003 |
| T417 | 0 | 0 |
| T427 | 0 | 0 |
| T437 | 0 | 0 |
| Table 7: Capacities Ca jk of every OOPN jk set up in the supply chain | |
| Transition | Capacity |
| OOPN11 | 10 |
| OOPN21 | 10 |
| OOPN31 | 10 |
| OOPN32 | 5 |
| OOPN33 | 5 |
| OOPN41 | 10 |
| OOPN42 | 5 |
| OOPN43 | 5 |
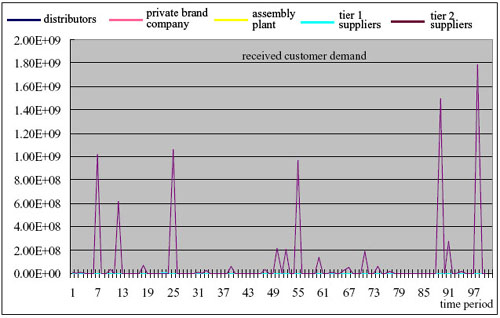
|
| (a) Bullwhip effect |
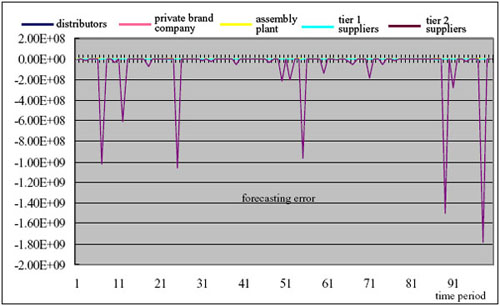
|
| (b) Forecasting errors |
| Figure 15. Results of the simple forecasting in Experiment 2 |
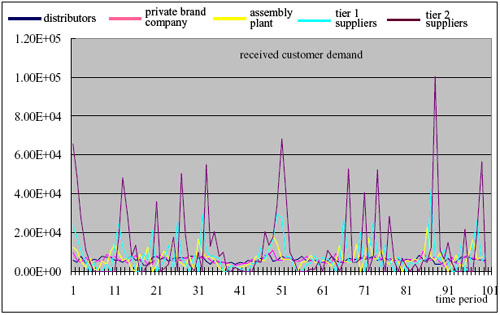
|
| (a) Bullwhip effect |
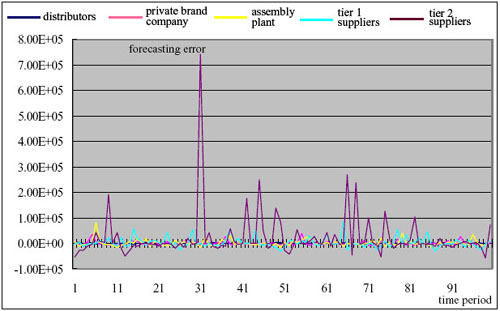
|
| (b) Forecasting errors |
| Figure 16. Results of the moving average forecasting in Experiment 2 |
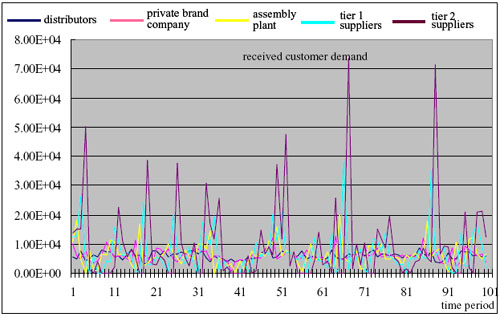
|
| (a) Bullwhip effect |
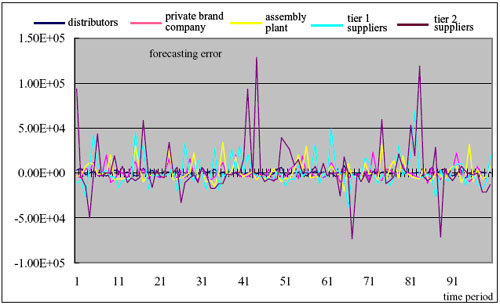
|
| (b) Forecasting errors |
| Figure 17. Results of the cluster forecasting in Experiment 2 |
| Table 8: Significance test of the decrease of forecasting errors by t-test (Experiment 1) | ||||||
| Exp# | Method comparison | Stage 1. distributors | Stage 2. private brand company | Stage 3. assembly plant | Stage 4. tier 1 suppliers | Stage 5. tier 2 suppliers |
| 1 | moving average vs. simple | 6.27* | 4.18* | 4.88* | 6.37* | 9.58* |
| cluster vs. moving average | -1.04 | 2.64* | 1.88* | 4.59* | 5.95* | |
| 2 | moving average vs. simple | 7.15* | 3.25* | 5.61* | 6.80* | 9.47* |
| cluster vs. moving average | -0.85 | 2.53* | 3.44* | 4.62* | 5.01* | |
| 3 | moving average vs. simple | 5.64* | 2.44* | 5.01* | 6.58* | 8.68* |
| cluster vs. moving average | -0.76 | 1.71* | 3.96* | 3.78* | 4.07* | |
| 4 | moving average vs. simple | 6.43* | 3.33* | 4.80* | 6.18* | 10.29* |
| cluster vs. moving average | -1.20 | 2.89* | 3.74* | 2.91* | 4.40* | |
| 5 | moving average vs. simple | 6.28* | 3.39* | 4.80* | 6.82* | 10.24* |
| cluster vs. moving average | -1.00 | 0.71 | 3.14* | 2.50* | 3.95* | |
| 6 | moving average vs. simple | 7.27* | 3.04* | 4.73* | 6.23* | 10.08* |
| cluster vs. moving average | -1.31 | 1.05* | 3.06* | 2.36* | 3.09* | |
| 7 | moving average vs. simple | 6.83* | 2.65* | 5.92* | 6.62* | 10.43* |
| cluster vs. moving average | -1.35 | 1.02 | 0.86 | 4.04* | 3.70* | |
| 8 | moving average vs. simple | 7.13* | 3.23* | 5.53* | 6.96* | 9.50* |
| cluster vs. moving average | -0.90 | 1.99* | 2.90* | 3.40* | 3.32* | |
| 9 | moving average vs. simple | 8.01* | 2.19* | 5.43* | 6.71* | 9.18* |
| cluster vs. moving average | -1.25 | 2.97* | 3.41* | 2.58* | 5.40* | |
| 10 | moving average vs. simple | 6.16* | 3.61* | 4.34* | 6.55* | 9.53* |
| cluster vs. moving average | -1.34 | 1.93* | 3.49* | 2.03* | 3.31* | |
| % of significance | moving average vs. simple | 100% | 100% | 100% | 100% | 100% |
| cluster vs. moving average | 0% | 80% | 90% | 100% | 100% | |
*significant, α≤ 0.05, n1=300, n2=300, t=1.64
| Table 9: Significance test of the decrease of forecasting errors by t-test (Experiment 2) | ||||||
| Exp# | Method comparison | Stage 1. distributors | Stage 2. private brand company | Stage 3. assembly plant | Stage 4. tier 1 suppliers | Stage 5. tier 2 suppliers |
| 1 | moving average vs. simple | 6.96* | 6.24* | 6.75* | 5.27* | 3.96* |
| cluster vs. moving average | -1.69 | 0.12 | 2.28* | 2.99* | 5.21* | |
| 2 | moving average vs. simple | 8.04* | 7.66* | 6.91* | 7.36* | 3.74* |
| cluster vs. moving average | -1.52 | -0.01 | 2.01* | 3.15* | 4.69* | |
| 3 | moving average vs. simple | 7.25* | 6.69* | 6.45* | 5.44* | 3.90* |
| cluster vs. moving average | -2.16 | 0.79 | 2.15* | 3.49* | 5.16* | |
| 4 | moving average vs. simple | 7.16* | 6.47* | 6.17* | 6.39* | 4.73* |
| cluster vs. moving average | -1.73 | 0.27 | 1.39 | 3.17* | 4.33* | |
| 5 | moving average vs. simple | 7.87* | 6.71* | 6.18* | 6.56* | 4.68* |
| cluster vs. moving average | -2.68 | -0.15 | 2.38* | 2.57* | 4.69* | |
| 6 | moving average vs. simple | 7.51* | 6.75* | 5.82* | 5.52* | 4.32* |
| cluster vs. moving average | -1.96 | 1.21 | 2.37* | 3.48* | 4.72* | |
| 7 | moving average vs. simple | 8.35* | 6.56* | 7.13* | 6.42* | 4.45* |
| cluster vs. moving average | -2.88 | -0.58 | 0.85 | 2.32* | 4.27* | |
| 8 | moving average vs. simple | 7.60* | 6.75* | 6.40* | 6.51* | 4.38* |
| cluster vs. moving average | -2.23 | -0.75 | 1.08 | 2.15* | 3.67* | |
| 9 | moving average vs. simple | 7.67* | 6.79* | 6.03* | 6.25* | 4.14* |
| cluster vs. moving average | -1.69 | 0.19 | 1.35 | 2.98* | 4.40* | |
| 10 | moving average vs. simple | 6.58* | 6.16* | 6.40* | 2.91* | 4.65* |
| cluster vs. moving average | -1.99 | -1.32 | 1.25 | 2.52* | 4.19* | |
| % of significance | moving average vs. simple | 100% | 100% | 100% | 100% | 100% |
| cluster vs. moving average | 0% | 0% | 50% | 100% | 100% | |
*significant, α≤0.05, n1=300, n2=300, t=1.64
| Table 10: Significance test of the decrease of forecasting errors by t-test (Experiment 3) | ||||||
| Exp# | Method comparison | Stage 1. distributors | Stage 2. private brand company | Stage 3. assembly plant | Stage 4. tier 1 suppliers | Stage 5. tier 2 suppliers |
| 1 | moving average vs. simple | 6.83* | 0.31 | 6.79* | 8.14* | 5.53* |
| cluster vs. moving average | -2.36 | 0.24 | -2.11 | 3.25* | 3.92* | |
| 2 | moving average vs. simple | 6.22* | 1.19 | 6.17* | 7.64* | 5.83* |
| cluster vs. moving average | -3.23 | 0.82 | -1.74 | 3.30* | 3.98* | |
| 3 | moving average vs. simple | 6.50* | -0.56 | 6.61* | 8.02* | 6.25* |
| cluster vs. moving average | -2.25 | 0.84 | -0.04 | 3.58* | 4.11* | |
| 4 | moving average vs. simple | 5.52* | 1.07* | 6.28* | 7.54* | 4.55* |
| cluster vs. moving average | -2.91 | 0.31 | -0.90 | 4.48* | 4.82* | |
| 5 | moving average vs. simple | 5.79* | -0.61 | 6.70* | 7.97* | 4.24* |
| cluster vs. moving average | -2.01 | 1.07 | -0.57 | 3.63* | 5.21* | |
| 6 | moving average vs. simple | 6.90* | 0.20 | 7.64* | 8.50* | 2.96* |
| cluster vs. moving average | -2.05 | 2.09* | -1.39 | 4.64* | 5.53* | |
| 7 | moving average vs. simple | 6.51* | -1.68 | 6.91* | 8.85* | 3.79* |
| cluster vs. moving average | -3.18 | -0.27 | -0.35 | 3.12* | 5.03* | |
| 8 | moving average vs. simple | 6.39* | 0.03 | 5.94* | 7.86* | 3.54* |
| cluster vs. moving average | -2.30 | 2.31* | -1.65 | 4.22* | 6.03* | |
| 9 | moving average vs. simple | 6.13* | 1.75* | 5.59* | 7.33* | 6.22* |
| cluster vs. moving average | -2.38 | 0.54 | 1.30 | 3.32* | 4.37* | |
| 10 | moving average vs. simple | 7.31* | -0.37 | 6.73* | 7.98* | 5.68* |
| cluster vs. moving average | -2.65 | 0.79 | -1.88 | 3.39* | 4.58* | |
| % of significance | moving average vs. simple | 100% | 20% | 100% | 100% | 100% |
| cluster vs. moving average | 0% | 20% | 0% | 100% | 100% | |
*significant, α≤0.05, n1=300, n2=300, t=1.64
| Table 11: Significance test of the decrease of forecasting errors by t-test (Experiment 4) | ||||||
| Exp# | Method comparison | Stage 1. distributors | Stage 2. private brand company | Stage 3. assembly plant | Stage 4. tier 1 suppliers | Stage 5. tier 2 suppliers |
| 1 | moving average vs. simple | 9.25* | 4.68* | 7.48* | 6.95* | 9.32* |
| cluster vs. moving average | -0.77 | 0.53 | 1.96* | 2.21* | 2.01* | |
| 2 | moving average vs. simple | 8.12* | 4.61* | 6.27* | 6.67* | 9.14* |
| cluster vs. moving average | -1.05 | 0.96 | 1.32 | 0.05 | 0.99 | |
| 3 | moving average vs. simple | 8.62* | 4.69* | 7.04* | 6.26* | 10.03* |
| cluster vs. moving average | -0.97 | 0.73 | 1.67* | 1.92* | 3.13* | |
| 4 | moving average vs. simple | 6.84* | 5.26* | 5.97* | 6.31* | 9.38* |
| cluster vs. moving average | -0.63 | 0.32 | 0.83 | 3.76* | 2.79* | |
| 5 | moving average vs. simple | 7.32* | 4.20* | 6.74* | 6.63* | 10.14* |
| cluster vs. moving average | -1.24 | 0.47 | 0.93 | 0.28 | 2.73* | |
| 6 | moving average vs. simple | 7.91* | 5.05* | 6.30* | 6.51* | 11.48* |
| cluster vs. moving average | -0.99 | -0.51 | 1.84* | 2.00* | 2.70* | |
| 7 | moving average vs. simple | 6.67* | 4.65* | 6.14* | 6.02* | 9.29* |
| cluster vs. moving average | -0.63 | 0.41 | 2.71* | 2.34* | 3.50* | |
| 8 | moving average vs. simple | 7.48* | 5.86* | 7.01* | 6.25* | 9.68* |
| cluster vs. moving average | -0.94 | 0.86 | 0.88 | 1.65* | 2.22* | |
| 9 | moving average vs. simple | 7.52* | 5.02* | 6.21* | 6.30* | 10.20* |
| cluster vs. moving average | -1.44 | -0.59 | 1.12 | 2.51* | 1.48 | |
| 10 | moving average vs. simple | 6.95* | 5.73* | 5.42* | 6.26* | 9.82* |
| cluster vs. moving average | -1.15 | -1.05 | 0.51 | 1.13 | 2.18* | |
| % of significance | moving average vs. simple | 100% | 100% | 100% | 100% | 100% |
| cluster vs. moving average | 0% | 0% | 40% | 70% | 80% | |
*significant, α≤0.05, n1=300, n2=300, t=1.64
| Table 12: Significance test of the decrease of forecasting errors by t-test (Experiment 5) | ||||||
| Exp# | Method comparison | Stage 1. distributors | Stage 2. private brand company | Stage 3. assembly plant | Stage 4. tier 1 suppliers | Stage 5. tier 2 suppliers |
| 1 | moving average vs. simple | 6.10* | 3.78* | 4.63* | 6.42* | 8.76* |
| cluster vs. moving average | -0.71 | 2.78* | 3.91* | 4.25* | 5.21* | |
| 2 | moving average vs. simple | 5.91* | 4.33* | 3.97* | 6.17* | 10.40* |
| cluster vs. moving average | -1.44 | 2.31* | 3.03* | 2.68* | 5.20* | |
| 3 | moving average vs. simple | 6.53* | 3.46* | 4.29* | 5.93* | 9.72* |
| cluster vs. moving average | -0.45 | 3.07* | 4.05* | 2.36* | 3.15* | |
| 4 | moving average vs. simple | 6.73* | 3.83* | 4.37* | 6.43* | 9.17* |
| cluster vs. moving average | -1.32 | 2.21* | 4.17* | 4.23* | 5.55* | |
| 5 | moving average vs. simple | 7.72* | 3.46* | 5.05* | 7.04* | 9.59* |
| cluster vs. moving average | -1.32 | 1.80* | 3.13* | 3.17* | 5.68* | |
| 6 | moving average vs. simple | 6.77* | 4.43* | 4.96* | 6.82* | 9.84* |
| cluster vs. moving average | -0.88 | 2.38* | 3.80* | 2.86* | 3.76* | |
| 7 | moving average vs. simple | 6.07* | 2.81* | 5.31* | 6.14* | 9.72* |
| cluster vs. moving average | -1.69 | 3.29* | 2.20* | 3.85* | 3.85* | |
| 8 | moving average vs. simple | 6.44* | 4.27* | 5.33* | 6.68* | 9.33* |
| cluster vs. moving average | -0.94 | 1.33 | 3.07* | 4.01* | 5.83* | |
| 9 | moving average vs. simple | 6.92* | 5.26* | 4.75* | 5.99* | 8.88* |
| cluster vs. moving average | -1.54 | 1.81* | 4.65* | 2.08* | 2.10* | |
| 10 | moving average vs. simple | 6.19* | 3.23* | 4.76* | 6.64* | 10.51* |
| cluster vs. moving average | -0.74 | 3.20* | 3.95* | 3.27* | 3.84* | |
| % of significance | moving average vs. simple | 100% | 100% | 100% | 100% | 100% |
| cluster vs. moving average | 0% | 90% | 100% | 100% | 100% | |
*significant, α≤0.05, n1=300, n2=300, t=1.64
BAGANHA M P and Cohen M A (1998) The stabilizing effect of inventory in supply chains. Operations Research, 46(3), pp. 572-583.
BRUSTOLONI J C (1991) Autonomous agents: characterization and requirements. Carnegie Mellon Technical Report CMU-CS-91-204, Pittsburgh: Carnegie Mellon University.
CARLSSON C & Fuller R (2001) Reducing the bullwhip effect by means of intelligent, soft computing methods. Proceedings of the 34th Hawaii International Conference on System Sciences.
CHANDRA C and Grabis J (2005) Application of multi-steps forecasting for restraining the bullwhip effect and improving inventory performance under autoregressive demand. European Journal of Operational Research, 166(2), pp.337-350.
CHEN F, Drezner Z, Ryan J K and Simch-levi D (2000a) Quantifying the bullwhip effect in a simple supply chain: The impact of forecasting. Management Science, 46(3), pp.436-443.
CHEN F, Drezner Z, Ryan J K and Simchi-levi D (2000b) The impact of exponential smoothing forecasts on the bullwhip effect. Naval Research Logistics, 47, pp.269-286.
DAVIDSSON P (2002) Agent Based Social Simulation: A Computer Science View. Journal of Artificial Societies and Social Simulation, 5(1), https://www.jasss.org/5/1/7.html
DEJONCKHEERE J, Disney S M, Lambrecht M R and Towill D R (2004) The impact of information enrichment on the bullwhip effect in supply chains: A control engineering perspective. European Journal of Operational Research, 153(3), pp. 727-750.
FONER L N (1993) What's an agent, anyway? A sociological case study. Agents Memo 93-01. Agents Group. Cambridge, MA: MIT Media Lab.
FORRESTER J W (1958) Industrial dynamics: A major breakthrough for decision makers. Harvard Business Review, 36(4), pp.37-66.
FOX, M S, Barbuceanu M, and Teigen, R (2000) Agent-oriented supply-chain management. International Journal of Flexible Manufacturing Systems, 12(2,3), pp.165-188.
HAN J and Kamber M (2001) Cluster analysis. In Data Mining: Concepts and Techniques, Morgan Kaufmann Publishers, San Francisco, CA, pp. 335-394.
HAYES-ROTH B (1995) An architecture for adaptive intelligent systems. Artificial Intelligence: Special Issue on Agents and Interactivity, 72, pp. 329-365.
HOSODA T and Disney S M (2006) On variance amplification in a three-echelon supply chain with minimum mean square error forecasting. The International Journal of Management Science, 34(4), pp. 344-358.
JIAO J, You X and Kumar A (2006) An agent-based framework for collaborative negotiation in the global manufacturing supply chain network. Robotics and Computer-Integrated Manufacturing, 22(3), pp. 239-255.
KEEN C D and Lakos C A (1993) A methodology for the construction of simulation models using object-oriented petri nets. Proc. of the European Simulation Multi-conference, pp. 267-271.
KAIHARA T (2003) Multi-agent based supply chain modeling with dynamic environment. International Journal of Production Economics, 85(2), pp.263-269.
KAUFMAN L and Rousseeuw P J (1990) Finding Groups in Data: an Introduction to Cluster Analysis, John Wiley & Sons.
KIMBROUGH S O, Wu D J and Fang Z (2002) Computers play the beer game: can artificial agents manage supply chains? Decision Support Systems, 33(3), pp.323-333.
KRAUSE S, Morais de Assis Silva F, Magedanz T, Popescu-Zeletin R, Falsarella O M and Raul Arias Mendez C (1997) MAGNA -- A DPE-based platform for mobile agents in electronic service markets. Proceedings of Third International Symposium on Autonomous Decentralized Systems, pp.93-102.
LEE H L, Padmanabhan P and Whang S (1997a) The paralyzing curse of the bullwhip effect in a supply chain. Sloan Management Review, Spring 1997, pp. 93-102.
LEE H L, Padmanabhan P and Whang S (1997b) Information distortion in a supply chain: the bullwhip effect. Management Science, 43(4), pp. 546-558.
LEE H L, Padmanabhan P and Whang S (2004a) information distortion in a supply chain: The bullwhip effect. Management Science, 50(12), pp.1875-1886.
LEE H L, Padmanabhan P and Whang S (2004b) Comments on 'information distortion in a supply chain: the bullwhip effect' the bullwhip effect: reflections. Management Science, 50(12), pp. 1887-1893.
LIN F R and Lin Y Y (2004) Integrating multi-agent negotiation to resolve constraints in fulfilling supply chain orders. The 8th Pacific-Asia Conference on Information Systems, Shanghai, China.
LIN F R and Shaw M J (1998) Reengineering the order fulfillment process in supply chain networks. International Journal of Flexible Manufacturing Systems, 10(3), pp.197-229.
LUNA F and Stefansson B (2000) Economic Simulation in Swarm: Agent-based Modeling and Object Oriented Programming, Kluwer Academic Publishers, Boston.
MAES P (1995) Artificial life meets entertainment: life like autonomous agents. Communications of the ACM, 38(11), pp. 108-114.
METTERS R (1996) Quantifying the bullwhip effect in supply chains. MSOM Conf. pp. 264-269.
MINAR N, Burkhart R, Langton C and Askenazi M (1996) The swarm simulation system: a toolkit for building multi-agent simulations. http://www.swarm.org.
PETRI C A (1962) Fundamentals of a theory of asynchronous information flow. IFIP Congress.
TERNA P (1998) Simulation tools for social scientists: building aAgent based models with Swarm. Journal of Artificial Societies and Social Simulation, 1(2), https://www.jasss.org/1/2/4.html
THONEMANN U W (2002) Improving supply-chain performance by sharing advance demand information. European Journal of Operational Research, 142(1), pp. 81-107.
STRADER T J, Lin F R and Shaw M J (1998) Simulation of order fulfillment in divergent assembly supply chains. Journal of Artificial Societies and Social Simulation, 1(2), https://www.jasss.org/1/2/5.html
WAGNER T, Guralnik V and Phelps J (2003) TAEMS agents: enabling dynamic distributed supply chain management. Electronic Commerce Research and Applications, 2(2), pp.114-132.
WEIDMANN N B and Girardin L (2005) Technical note: evaluating java development kits for agent-based modeling. Journal of Artificial Societies and Social Simulation, 8(2), https://www.jasss.org/8/2/8.html
WOOLDRIDGE M and Jennings N R (1995) Agent theories, architectures, and languages: a survey. In M. Wooldridge and N.R. Jennings (Eds.), Intelligent Agents, Berlin: Springer-Verlag, pp.1-22.
YUNG S K, Yang C C, Lau A SM and Yen J (2000) Applying multi-agent technology to supply chain management. Journal of Electronic Commerce Research, 1(4), pp.119-132.
ZHA X F (2000) An object-oriented knowledge based Petri net approach to intelligent integration of design and assembly planning. AI in Engineering, 14(1), pp.83-112.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2006]