
Jordi Sabater, Mario Paolucci and Rosaria Conte (2006)
Repage: REPutation and ImAGE Among Limited Autonomous Partners
Journal of Artificial Societies and Social Simulation
vol. 9, no. 2
<https://www.jasss.org/9/2/3.html>
For information about citing this article, click here
Received: 13-Mar-2005 Accepted: 01-Mar-2006 Published: 31-Mar-2006

 Abstract
Abstract
|
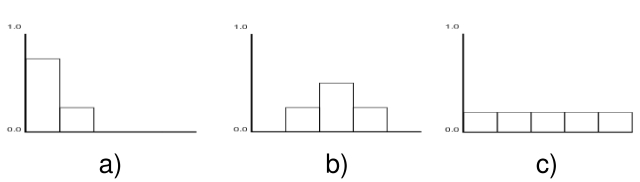
| Figure 1. Examples of fuzzy evaluations. In a) we have {0.75, 0.25, 0, 0, 0}, a mostly bad (75% very bad, 25% bad) evaluation; b) is an average evaluation, neither good nor bad. In c), we show the situation of maximum uncertainty; aggregating another number with this one leaves the first unchanged. |
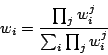
|
that is also our choice for use in Repage. This function shows several good properties: besides respecting the identity, it is commutative and associative. However, it loses sense when denominator — the sum of the products of weights — is zero; notice that, for this to happen, it is sufficient to have at least one zero in all evaluation levels for some of the values to be aggregated, which, for large aggregations, is quite easily the case. Yager (2004b) proposes several solutions, but in Repage we get rid of this problem as a side effect of the strength of beliefs. To take strength into account, we apply the standard procedure of moving the fuzzy set to be aggregated towards the identity by a quantity determined by the strength (rescaled to the [0, 1] interval by the use of the arctan function). After rescaling, no value can be zero if not in the case of infinite strength, thus avoiding the problem of incompatible values.
|
|
In words, the higher the momentum, the wider the difference between the values compared.
|
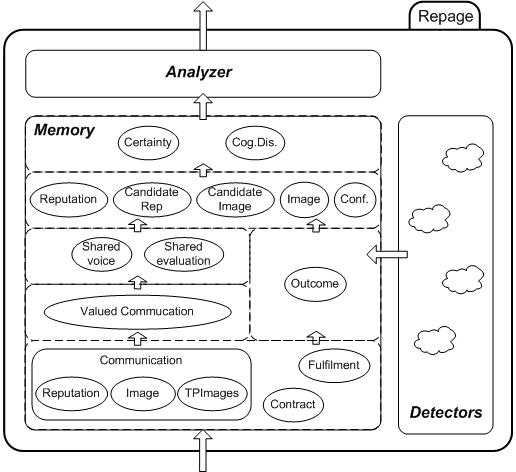
| Figure 2. Repage architecture |
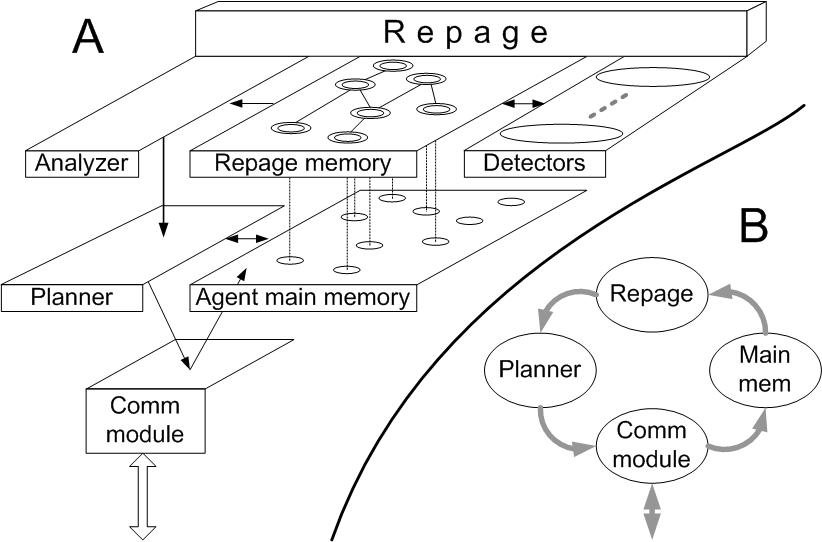
|
| Figure 3. Repage and its environment |
|
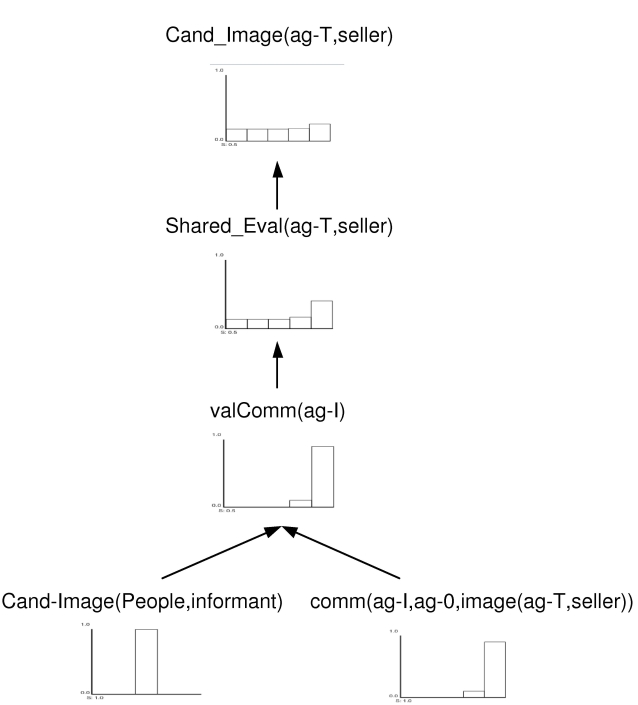
| Figure 4. Value of direct interaction. Starting situation |
|
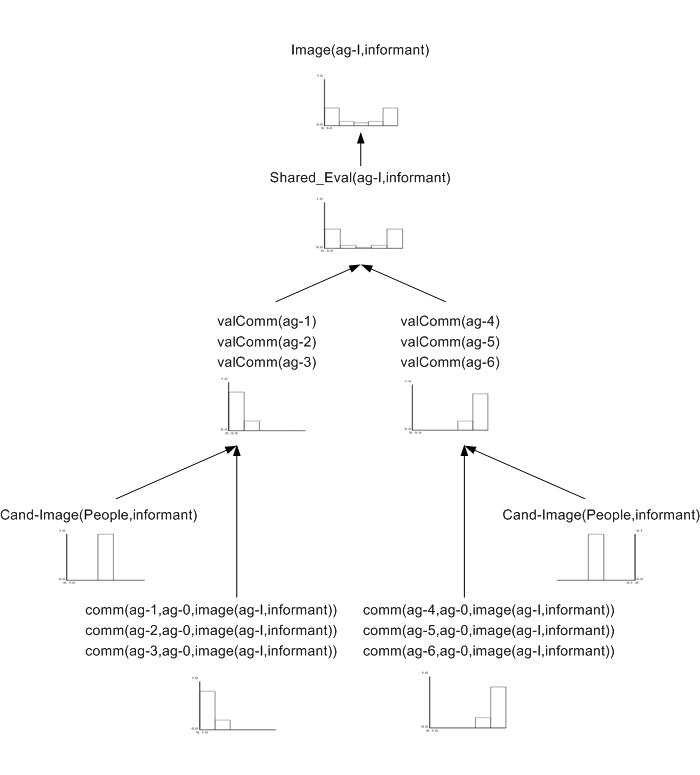
| Figure 5. Value of direct interaction. Arrival of contradictory information |
|
| Figure 6. Value of direct interaction. Good direct interaction causes good image |
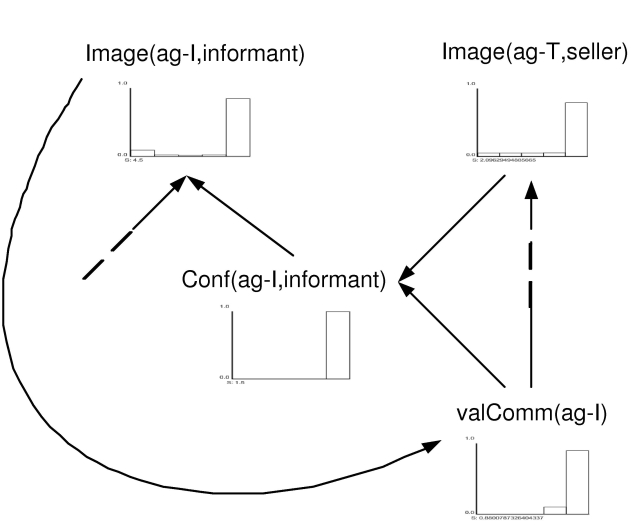
|
| Figure 7. Value of direct interaction. Feedback loop |
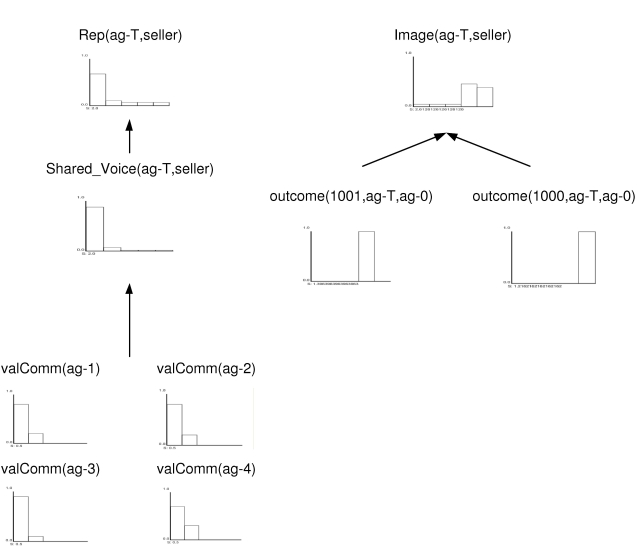 |
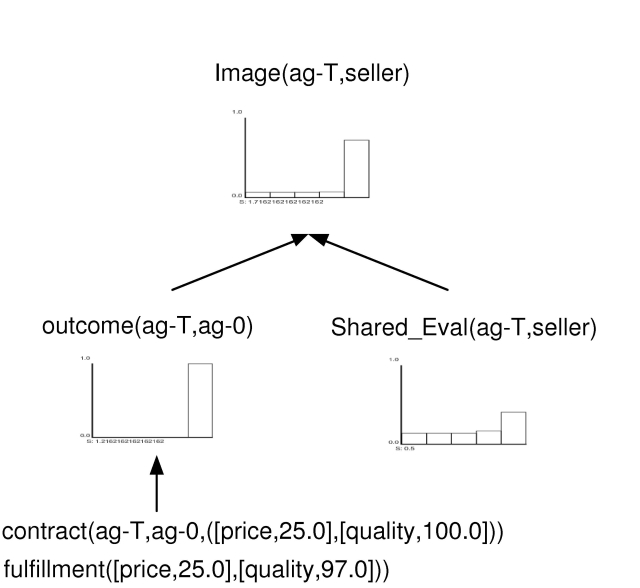
| Figure 8. Image can be distinct from Reputation |
CABRAL L M B and Hortaçsu A (2004) The Dynamics of Seller Reputation: Theory and Evidence from eBay, CEPR Discussion Papers 4345, http://econpapers.repec.org/paper/cprceprdp/4345.htm
CARBO J . Molina J M and Davila J (2002) Comparing predictions of SPORAS vs. a fuzzy reputation agent system. In 3rd International Conference on Fuzzy Sets and Fuzzy Systems, Interlaken, pp. 147--153
CARBO J Molina J M and Davila J (2003) Trust management through fuzzy reputation. Int. Journal in Cooperative Information Systems, 12(1), pp.135-155
CONTE R and Paolucci M (2002) Reputation in Artificial Societies: Social Beliefs for Social Order. Boston: Kluwer.
CONTE R and Paolucci M (2003) Social cognitive factors of unfair ratings in reputation reporting systems. In Proceedings of the IEEE/WIC International Conference on Web Intelligence — WI 2003, pp. 316-322
DELLAROCAS C (2003) Efficiency and Robustness of Binary Feedback Mechanisms in Trading Environments with Moral Hazard, Paper 170, January 2003, Center for eBusiness@mit.edu
DUNBAR R (1998) Grooming, Gossip, and the Evolution of Language. Harvard Univ Press.
FALCONE R Pezzulo G and Castelfranchi C (2003) A fuzzy approach to a belief-based trust computation. Lecture Notes on Artificial Intelligence, 2631, pp. 73-86
GRUNIG J E and Hung C F (2002) The effect of relationships on reputation and reputation on relationships: A cognitive, behavioral study, Paper presented at the PRSA Educator's Academy 5th Annual International, Interdisciplinary Public Relations Research Conference.
HUYNH D Jennings N R and Shadbolt N R (2004) Developing an integrated trust and reputation model for open multi-agent systems. In Proceedings of the Workshop on Trust in Agent Societies (AAMAS-04), New York, USA, pp 65--74
KREPS D M and Wilson R (1982) Reputation and imperfect information. Journal of Economic Theory, 27, pp. 253-279
MICELI M and Castelfranchi C (2000) 'Human cognition and agent technology, in The Role of Evaluation in Cognition and Social Interaction. Amsterdam:Benjamins.
NOWAK M A and Sigmund K (1998) Evolution of indirect reciprocity by image scoring. Nature, 393, pp. 573-577
RAMCHURN S D Huynh D and Jennings N R (2004a) Trust in multiagent systems. The Knowledge Engineering Review 19 (1) pp. 1-25.
RAMCHURN S D Sierra C Godo L and Jennings N R (2004b) Devising a trust model for multi-agent interactions using confidence and reputation. Int. J. of Applied Artificial Intelligence, (18) pp. 833--852
RESNICK P and Zeckhauser R (2002) Trust among strangers in internet transactions: Empirical analysis of ebay's reputation system. In The Economics of the Internet and E-Commerce. Michael R. Baye, editor. Volume 11 of Advances in Applied Microeconomics. Amsterdam, Elsevier Science. http://www.si.umich.edu/~presnick/papers/ebayNBER/RZNBERBodegaBay.pdf
SABATER J and Sierra C (2002) Reputation and social network analysis in multi-agent systems. In Proceedings AAMAS-02, Bologna, Italy, pp. 475-482
SABATER J (2003) Trust and Reputation for agent societies. PhD thesis. Artificial Intelligence Research Institute (IIIA-CSIC), Bellaterra, Catalonia, Spain. http://www.iiia.csic.es/~jsabater/
SABATER J and Sierra C (2004) Review on computational trust and reputation models. Artificial Intelligence Review, vol. 24, no. 1, pp. 33-60
SCHILLO M Funk P and Rovatsos M (2000) Using trust for detecting deceitful agents in artificial societies. Applied Artificial Intelligence, 14: 825-848
SKOWRONSKI J J and Carlston D E (1989) Negativity and extremity biases in impression formation: A review of explanations. Psychological Bulletin, 105, pp. 131-142
YAGER R (2004a) On the determination of strength of belief for decision support under uncertainity-Part I: generating strength of belief. Fuzzy Sets and Systems, 142, v. 1, pp. 117-128
YAGER R (2004b) On the determination of strength of belief for decision support under uncertainty-Part II: fusing strengths of belief. Fuzzy Sets and Systems, 142, v.1, pp. 129-142
YU B and Singh M P (2002) An evidential model of distributed reputation management. In Proceedings of AAMAS-02, Bologna, Italy, pp 294-301
ZADEH L A (1965) Fuzzy sets. Inform. Control, 8, pp. 338-353
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2006]