
When and How to Imitate Your Neighbours: Lessons from and for FEARLUS
Journal of Artificial Societies and Social Simulation
12 (3) 2
<https://www.jasss.org/12/3/2.html>
For information about citing this article, click here
Received: 29-Jun-2007 Accepted: 16-May-2009 Published: 30-Jun-2009

 Abstract
Abstract
|
| Figure 1. Grid and Social Neighbourhoods |
|
| Figure 2. Calculation of Land Use to Imitate |
| Table 1: Calculation of Land Use to Imitate | ||||||
| Land Use | A | B | C | D | E | Sum |
| Number of Parcels (used in SI/SSI) | 12 | 2 | 0 | 10 | 4 | 28 |
| Total Yield (used in YI/SYI) | 93 | 16 | 0 | 93 | 42 | 244 |
| Mean Yield (used in BI/SBI) | 7.75 | 8 | N/A | 9.3 | 10.25 | 35.3 |
| Table 2: Estimate and 95% confidence intervals [in brackets] for mean of Aspiration Thresholds across Land Parcels in FEARLUS 21 by 21 Environments. 60 runs of 200 simulation Years for each combination of Algorithm class (columns) and Environment type (rows) | |||||||
| HR | HRSI | HRSSI | HRYI | HRSYI | HRBI | HRSBI | |
| S0-T16c | 7.956 [0.082] | 8.481 [0.059] | 7.951 [0.070] | 8.840 [0.046] | 8.236 [0.073] | 9.103 [0.074] | 9.089 [0.069] |
| S0-T16u | 8.031 [0.051] | 7.985 [0.043] | 7.926 [0.051] | 8.016 [0.057] | 7.919 [0.062] | 7.948 [0.099] | 7.982 [0.091] |
| S8c-T8c | 7.835 [0.057] | 8.252 [0.045] | 7.871 [0.055] | 8.491 [0.046] | 8.306 [0.053] | 8.884 [0.036] | 8.932 [0.040] |
| S8u-T8c | 7.862 [0.055] | 7.935 [0.053] | 7.619 [0.061] | 8.194 [0.058] | 7.809 [0.063] | 8.705 [0.044] | 8.727 [0.043] |
| S8c-T8u | 7.366 [0.043] | 8.042 [0.046] | 7.837 [0.061] | 8.119 [0.042] | 8.140 [0.053] | 8.329 [0.057] | 8.267 [0.071] |
| S8u-T8u | 7.482 [0.040] | 7.488 [0.041] | 7.570 [0.057] | 7.465 [0.041] | 7.533 [0.063] | 7.434 [0.062] | 7.468 [0.064] |
| S16c-T0 | 7.735 [0.036] | 8.006 [0.032] | 7.974 [0.042] | 8.129 [0.039] | 8.213 [0.031] | 8.354 [0.031] | 8.394 [0.028] |
| S16u-T0 | 7.756 [0.029] | 7.802 [0.034] | 7.899 [0.033] | 7.767 [0.035] | 7.886 [0.036] | 7.835 [0.031] | 7.844 [0.032] |
| Table 3: Outcomes of some Selection Algorithm Contests in spatially homogeneous, temporally variable Environments (upper-right in both : S0-T16c; lower-left: S0-T16u) | |||||||
| H8RSBI | H8RBI | H8RSYI | H8RYI | H8RSSI | H8RSI | H8R | |
| H8RSBI | — | 18 (1) | 16 (1) | 8 (0) | 7 (0) | 6 (1) | 8 (1) |
| H8RBI | 57 (40) | — | 41 (14) | 56 (21) | 12 (1) | 32 (8) | 35 (3) |
| H8RSYI | 65 (25) | 50 (27) | — | 90 (54) | 25 (2) | 71 (36) | 54 (25) |
| H8RYI | 62 (23) | 59 (29) | 59 (37) | — | 9 (0) | 32 (6) | 39 (8) |
| H8RSSI | 49 (23) | 45 (33) | 52 (29) | 58 (32) | — | 107 (58) | 94 (57) |
| H8RSI | 59 (30) | 62 (28) | 65 (32) | 58 (29) | 70 (27) | — | 63 (22) |
| H8R | 70 (42) | 74 (33) | 77 (31) | 70 (39) | 82 (38) | 67 (39) | — |
| Table 4: Outcomes of some Selection Algorithm Contests in spatially variable, temporally unchanging Environments (upper-right: S16c-T0, lower-left: S16u-T0) | |||||||
| H8RSBI | H8RBI | H8RSYI | H8RYI | H8RSSI | H8RSI | H8R | |
| H8RSBI | — | 29 (2) | 34 (1) | 36 (0) | 19 (0) | 40 (1) | 29 (1) |
| H8RBI | 54 (24) | — | 59 (23) | 49 (27) | 30 (4) | 56 (15) | 49 (20) |
| H8RSYI | 30 (2) | 46 (7) | — | 69 (38) | 42 (8) | 61 (18) | 61 (28) |
| H8RYI | 44 (22) | 54 (23) | 79 (53) | — | 29 (5) | 65 (26) | 56 (22) |
| H8RSSI | 34 (1) | 34 (2) | 55 (22) | 35 (3) | — | 80 (49) | 83 (47) |
| H8RSI | 58 (17) | 61 (15) | 81 (53) | 56 (25) | 85 (58) | — | 64 (29) |
| H8R | 57 (29) | 75 (33) | 80 (56) | 66 (44) | 90 (60) | 68 (46) | — |
| Table 5: Outcomes of some Selection Algorithm Contests in spatially variable, temporally variable but auto-correlated Environments (upper-right: S8c-T8c, lower-left: S8u-T8c) | |||||||
| H8RSBI | H8RBI | H8RSYI | H8RYI | H8RSSI | H8RSI | H8R | |
| H8RSBI | — | 14 (0) | 12 (0) | 21 (0) | 5 (0) | 18 (0) | 11 (0) |
| H8RBI | 35 (0) | — | 41 (20) | 57 (25) | 13 (0) | 48 (15) | 40 (6) |
| H8RSYI | 7 (0) | 17 (0) | — | 83 (49) | 37 (2) | 83 (38) | 79 (16) |
| H8RYI | 23 (1) | 37 (14) | 101 (60) | — | 11 (0) | 42 (17) | 47 (6) |
| H8RSSI | 5 (0) | 7 (0) | 43 (12) | 10 (0) | — | 102 (59) | 87 (48) |
| H8RSI | 20 (1) | 44 (10) | 97 (59) | 45 (18) | 101 (60) | — | 59 (12) |
| H8R | 22 (0) | 65 (28) | 104 (60) | 56 (43) | 114 (60) | 79 (48) | — |
| Table 6: Outcomes of some Selection Algorithm Contests in spatially variable, temporally variable and uncorrelated Environments (upper-right: S8c-T8u, lower-left: S8u-T8u | |||||||
| H8RSBI | H8RBI | H8RSYI | H8RYI | H8RSSI | H8RSI | H8R | |
| H8RSBI | — | 32 (3) | 24 (3) | 28 (5) | 18 (0) | 26 (3) | 19 (0) |
| H8RBI | 61 (29) | — | 45 (29) | 62 (35) | 22 (6) | 56 (25) | 43 (2) |
| H8RSYI | 21 (0) | 15 (0) | — | 88 (42) | 39 (4) | 75 (30) | 67 (1) |
| H8RYI | 37 (12) | 49 (13) | 99 (59) | — | 15 (3) | 39 (15) | 42 (1) |
| H8RSSI | 21 (0) | 17 (0) | 63 (20) | 25 (0) | — | 88 (60) | 81 (11) |
| H8RSI | 38 (12) | 45 (13) | 98 (60) | 60 (26) | 100 (59) | — | 48 (4) |
| H8R | 54 (33) | 65 (42) | 102 (60) | 60 (45) | 103 (60) | 74 (48) | — |
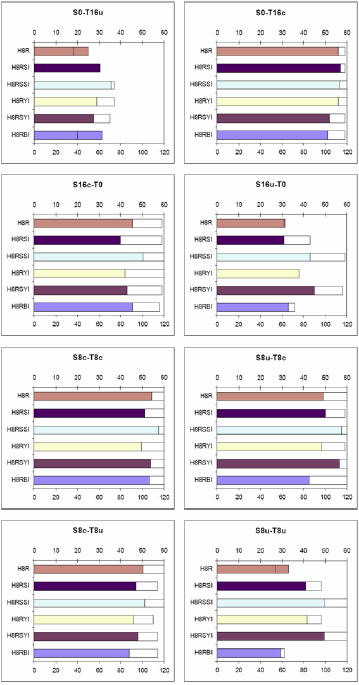
|
| Figure 3. Outcomes of Contests from Table 3 involving H8RSBI |
| Table 7: Outcome of some Selection Algorithm Contests between Algorithms with Aspiration Threshold 10, in spatially homogeneous, temporally variable but correlated Environments | |||||||
| H10RSBI | H10RBI | H10RSYI | H10RYI | H10RSSI | H10RSI | H10R | |
| H10RSBI | — | 12 (1) | 19 (3) | 17 (1) | 7 (0) | 8 (1) | 0 (0) |
| H10RBI | — | 58 (30) | 71 (29) | 14 (7) | 39 (8) | 9 (0) | |
| H10RSYI | — | 86 (46) | 35 (6) | 68 31 | 31 (9) | ||
| H10RYI | — | 9 (2) | 26 (3) | 13 (1) | |||
| H10RSSI | — | 112 (59) | 92 (50) | ||||
| H10RSI | — | 31 (10) | |||||
| H10R | — | ||||||
"the drive to compare one's opinions and abilities with that of others is larger, the more uncertain one is regarding one's own opinions and abilities."However, FEARLUS results reported here indicate that as Year-to-Year uncertainty increases (this is uncertainty inherent in the environment rather than measured by the individual agent from the accuracy of their predictions, but increasing inherent environmental uncertainty would make such predictions less accurate), repetition becomes increasingly favoured over Imitation of any kind, and the latter also becomes less favoured relative to Random Experimentation (probably because the rewards of Imitation fall, while those of diversity, which Random Experimentation tends to increase, do not). The results reported in Polhill, Gotts and Law (2001) also indicate that greater Year-to-Year uncertainty favours Selection Algorithms based on the long-term expected mean performance on specific Land Parcels at the expense of Imitative Selection Algorithms. In at least some kinds of decision-making, then, people behaving as Festinger and the consumat approach predict would lose out to those behaving differently. They may behave in such a manner, but when comparably simple alternatives would do better, it does seem likely selective pressures would lead to their adoption. How people actually change their tendency to imitative behaviour as environmental uncertainty increases would seem to be discoverable by laboratory experiment, but we have found no directly relevant studies.
2 The experiments newly reported here used FEARLUS versions 0-5-1-4, 0-5-1-5 (which differ only slightly) and 0-6-8-2. Versions 0-5-1-5 and 0-6-8-2, and relevant parameter files and scripts, are available from the authors.
BENDOR, J. and Swistak, P. (1997) The evolutionary stability of cooperation. American Political Science Review 91(2):290-307.
BESLEY, T. and Case, A. (1994) Diffusion as a Learning Process: Evidence from HYV Cotton. Discussion Paper #174, Research Program in Development Studies, Center of International Studies, Woodrow Wilson School of Public and International Affairs, Princeton University.
BRANDT, H., Hauert, C. and Sigmund, K. (2003). Punishment and reputation in spatial public goods games. Proceedings of the Royal Society of London B 270:1099-1104.
CASE, A. (1992) Neighborhood influence and technological change. Regional Science and Urban Economics 22(3):491-508.
CHIFFOLEAU, Y. (2005) Learning about innovation through networks: the development of environment-friendly viticulture. Technovation 25:1193-1204.
COHEN, M. D., Riolo, R. L.& Axelrod, R. (1999). The Emergence of Social Organization in the Prisoner's Dilemma: How Context-Preservation and other Factors Promote Cooperation. Working Paper 99-01-002, Santa Fe Institute.
CRAMB, R.A., Garcia, J.N.M., Gerrits, R.V. and Saguiguit, G.C. (1999) Smallholder adoption of soil conservation techniques: evidence from upland projects in the Philippines. Land Degradation and Development 10:405-423.
DUNG, L.C., Vinh, N.N.G.V., Tuan, L.A. and Bousquet, F. (2005) Economic differentiation of rice and shrimp farming systems and riskiness: a case of Bac Lieu, Mekong Delta, Vietnam, in : F. Bousquet, F., Trebuil, G. and Hardy, B. Companion Modeling and Multi-agent Systems for Integrated Natural Resource Management in Asia. Metro Manila, International Rice Research Institute, p. 211-235.
EGUÍLEZ, V.M., Zimmermann, M.G., Cela-Conde, C.J. and San Miguel, M. (2005) Cooperation and the Emergence of Role Differentiation in the Dynamics of Social Networks. American Journal of Sociology 110(4): 977-1008.
ESHEL, I., Herreiner, D. K., Samuelson, L., Sansone, E. & Shaked, A. (2000). Cooperation, Mimesis and Local Interaction Sociological Methods and Research 28(3): 341-364.
ESHEL, I., Samuelson, L. & Shaked, A. (1998). Altruists, Egoists and Hooligans in a Local Interaction Model. American Economic Review 88(1): 157-179.
FEDER, G. and Slade, R. (1984) The Acquisition of Information and the Adoption of New Technology. American Journal of Agricultural Economics 66(3):312-320.
FESTINGER, L. (1954). A theory of social comparision processes. Human Relations 7:117-140.
FOSTER, A. D. and Rosenzweig, M.R. (1995) Learning by Doing and Learning from Others: Human Capital and Technological Change in Agriculture. Journal of Political Economy 103(6):1176-1209
FUJISAKA, S. (1994) Learning from six reasons why farmers do not adopt innovations intended to improve sustainability of upland agriculture. Agricultural Systems 46:409-425.
GOTTS, N.M., Polhill, J.G. and Law, A.N.R. (2003) Aspiration levels in a land use simulation. Cybernetics and Systems 34(8):663-683.
GOTTS, N.M., Polhill, J.G. and Adam, W. J. (2003) Simulation and Analysis in Agent-Based Modelling of Land Use Change. Proceedings, First conference of the European Social Simulation Association September 18-21, Groningen, The Netherlands, http://www.uni-koblenz.de/~essa/ESSA2003/.
GOTTS, N.M., Polhill, J.G., Law, A.N.R. and Izquierdo, L.R. (2003) Dynamics of imitation in a land use simulation. In Dautenhahn, K. and Nehaniv, C.L. (Eds.) Proceedings of the AISB '03 Second International Symposium on Imitation in Animals and Artifacts, 7-11 April, The University of Wales, Aberystwyth, The Society for the Study of Artificial Intelligence and Simulation of Behavious (SSAISB), pp.39-46. Also available online at http://www.macaulay.ac.uk/fearlus/FEARLUS-publications.html.
GRIM, P. (1996). Spatialization and Greater Generosity in the Stochastic Prisoner's Dilemma. BioSystems 37: 3-17.
HÄGERSTRAND, T. (1967) Innovation Diffusion as a Spatial Process, translated and with a postscript by Pred, A., translation with the assistance of Haag, G. University of Chicago Press, Chicago.
HIEBERT, L.D. (1974) Risk, Learning, and the Adoption of Fertilizer Responsive Seed Varieties. American Journal of Agricultural Economics 56:764-768.
HOFBAUER, J. and Sigmund, K. (1998) Evolutionary Games and Population Dynamics. Cambridge, UK, Cambridge University Press.
JAGER, W., Janssen, M.A., De Vries, H.J.M., De Greef, J. and Vlek, C.A.J. (2000) Behaviour in Commons Dilemmas: Homo economicus and Homo psychologicus in an Ecological-Economic Model. Ecological Economics 35:357-379.
JANSSEN, M.A. and Jager, W. (1999) An Integrated Approach to Simulating Behavioural Processes: A Case Study of the Lock-In of Consumption Patterns. Journal of Artificial Societies and Social Simulation 2(2) https://www.jasss.org/2/2/2.html.
JANSSEN, M.C.W. (2000) Imitation of Cooperation in Prisoner's Dilemma Games with Some Local Interaction. Tinbergen Institute Discussion Paper TI 2000-019/1
JANSSEN, M.C.W. (2007) Coordination in Irrigation Systems: An Analysis of the Lansing-Kremer model of Bali. Agricultural Systems 93:170-190.
KILLINGBACK, T., Doebeli, M. & Knowlton, N. (1999). Variable Investment, the Continuous Prisoner's Dilemma, and the Origin of Cooperation. Proceedings of the Royal Society of London B 266:1723-1728.
KIRCHKAMP, O. (2000). Evolution of Learning Rules in Space. In Suleiman, R., Troitzsch, K.G. and Gilbert, G.N. (Eds.) Tools and Techniques for Social Science Simulation, Chapter 10, pp.179-195. Berlin, Physica-Verlag.
LANSING, J. S. (2000) Anti-Chaos, Common Property and the Emergence of Cooperation. In Kohler, T.A. and Gumerman, G.J. (Eds.) Dynamics in Human and Primate Societies, pp.207-223. Santa Fe Institute Studies in the Sciences of Complexity. Oxford University Press, Oxford.
LANSING, J. S. and Kremer, J.N. (1994) Emergent properties of Balinese water temple networks: coadaptation on a rugged fitness landscape. Artificial Life III. Langton, C.G. (ed), pp.201-223. Addison-Wesley.
LETENYEI, I. ( 2001) Rural innovation chains: two examples for the diffusion of rural innovations. Hungarian Review of Sociology 7(1):85-100.
NOAILLY, J., Withagen, C.A. and van den Bergh, J.C.J.M. (2005) Spatial Evolution of Social Norms in a Common-Pool Resource Game, Working Papers 2005.79, Fondazione Eni Enrico Mattei.
NOWAK, M. & Sigmund, K. (1993). A Strategy of Win-Stay, Lose-Shift that Outperforms Tit-for-Tat in the Prisoner's Dilemma Game. Nature 364:56-58.
POLHILL, J.G., Gotts, N.M. and Law, A.N.R. (2001) Imitative versus non-imitative strategies in a land use simulation. Cybernetics and Systems 32(1-2):285-307.
POMP, M. and Burger, K. (1995) Innovation and imitation: adoption of cocoa by Indonesian smallholders. World Development 23(3):423-431.
RYAN, B. and Gross, N.C. (1943) The diffusion of hybrid seed corn in two Iowa communities. Rural Sociology 3(Pt.1):15-24.
SCHMIDT, C. and Rounsevell, M. D. A. (2006) Are agricultural land use patterns influenced by farmer imitation? Agriculture, Ecosystems & Environment 115(1-4):113-127.
SIMON, H.A. (1955) A behavioral model of rational choice. Quarterly Journal of Economics 69:99-118. Reprinted in Simon, H.A. (1957) Models of Man, Social and Rational: Mathematical Essays on Rational Human Behavior in a Social Setting, ch.14, pp.241-260.
SIMON, H.A. (1957) Models of Man, Social and Rational: Mathematical Essays on Rational Human Behavior in a Social Setting. New York, John Wiley and Sons.
TAYLOR, P. and Jonker, L. (1978) Evolutionarily stable strategies and game dynamics. Mathematical Biosciences 40:145-156.
YOON, K. (2005) Is Imitation Conducive to Cooperation in Local Interaction Models? Korean Economic Review 21(2):203-212.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2009]